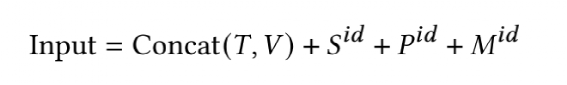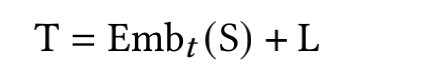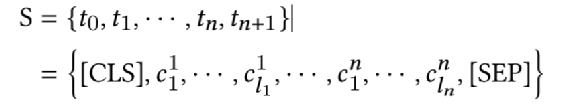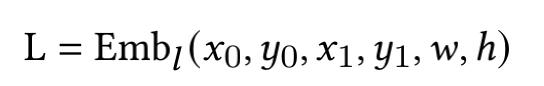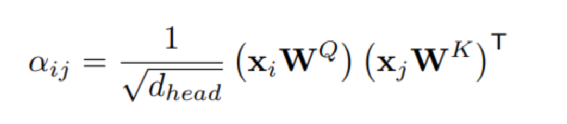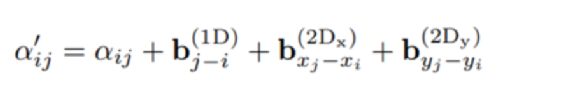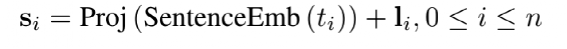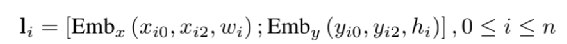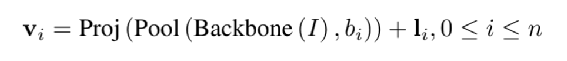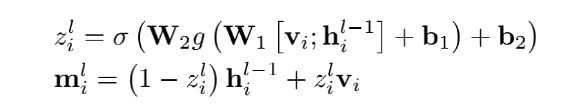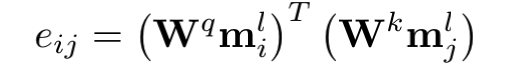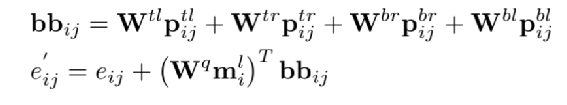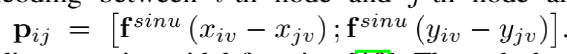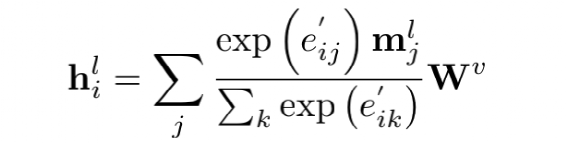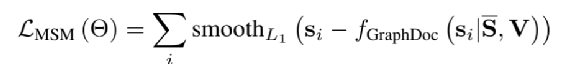一.前言
文档图像有多个文本条目(Segment)或者词(Word)或者区域(Region),文档智能核心要解决的两个问题是:
- 学习 Segment(Word、Region)良好的 Embedding 表示;
- 基于学习的 Embedding 来进行分类从而实现类别预测;
- 基于学习的 Embedding 计算相似度来预测配对关系,配对的 Segment(Word、Region)相似度很高;
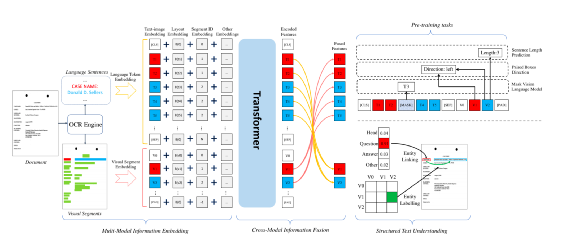
本文选取这个领域比较有代表性的三篇论文,对里边核心技术做简单介绍,三个模型如下:以上论文的模型都是通过自监督学习来学习 Segment 、Word 或者 Region 的 Embedding 表示,从而得到一个 Pretrain 模型,Pretrain 模型通过领域类的数据做Finetune 来解决实际的 Segment 等 分类或者 K-V 预测。StrucText、LayoutLMv3、GraphDoc 虽然属于不同的模型,但是核心点可以抽象成三部分:输入特征是指模型都会采用哪些特征做为模型输入,目前这个领域最前沿的模型基本都会采用图像、文本、版式的多模态多种特征;特征融合是指多个Segment(Word、Region)的输入特征如何相互融合,从而让每个Segment学习一个更有代表性的Embedding,目前基本两种做法:我们可以获取的文档是海量的,但是带有标注信息的却非常少,所以还有非常关键的一点是:通过文档数据的特点来设计自监督任务;其中 T 代表 文本特征、V代表图像特征、S代表Segment Idx特征、P代表字符长度特征、M代表模态特征。简单总结,就是将图像和文本两类序列特征分别加上S、P、M 特征后再拼接起来作为一个特征序列文本是通过OCR识别获得,除了文本还会得到文本Segment的坐标 (????0, ????0, ????1, ????1) ,代表Segment左上和右下的横纵坐标,通过坐标还能得到该Segment的宽和高 (????, ℎ )。其中S代表整个文档中单词级别(若是汉字为字符级别)的序列,序列的按照单词左上角坐标顺序排序,在序列前后会补齐开始和结束字符。L代表的是Layout的编码特征,对文档的单词(或汉字的字符)的坐标进行Embedding编码。L序列的长度、维度和T的长度、维度保持一致,因为一般OCR无法获取单词级别的坐标,这种情况下可以根据Segment的坐标估算其中CNN代表ResNet50+FPN,要注意的这里用的是Segment位置(不是文本特征中的单词或者字符)对应的图像FPN特征,L也相应的用Segment坐标计算。所有的Segment 按照左上角坐标排序后,每个Segment会有一个唯一的Idx,对Idx进行编码作为S特征,注意在T中,同一个Segment的多个单词都要用对应S的特征输入特征(文本、图像拼接)作为一个序列,进入多层的Transformer,通过多头自注意力算序列中不同Step特征的相关性,进行特征融合。最终得到的每个单词、每个Segment的学习的Embedding表示
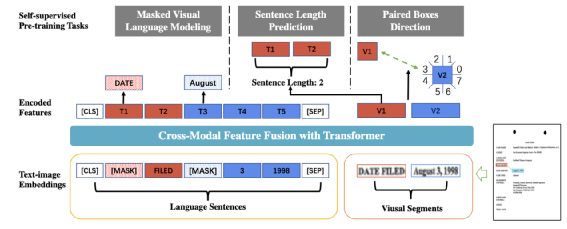
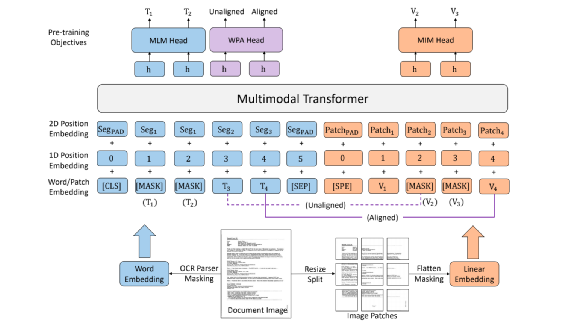
Mask 掉输入文本中一些单词,通过最终学习的Embedding来预测Mask掉的单词通过Segment的学习的Embedding,来预测这个Segment有几个单词根据不同Segment的相对方向分成8类,来预测两个Segment方向属于哪一类,类似做做法在图像的自监督任务中使用很多,可以参考我们以前发布的博客【4】LayoutLMv3 是微软提出的文档智能 Layout 的第三代模型,第一代预训练输入阶段只用文本,第二代输入的特征也考虑图片,并且在计算 Attention 矩阵时考虑了相对的位置关系,第三代的 Layout 最大的改进是用 VIT 取代预训练的各种 CNN 做视觉特征提取,v3 的模型架构如下图:输入特征由4部分组成:文本特征、1D Layout特征、2D Layout特征、图像特征。处理方法和StrucText类似:将文本序列特征分别加上1D Layout特征、2D Layout 特征得到文本特征,图像序列特征加上1D Layout特征后得到图像特征,再将文本、图像特征拼接起来作为一个特征序列(在文本序列特征首尾会增加[CLS]、[SEP],在图像序列的开始会增加[SPE] 等特殊的Token)。
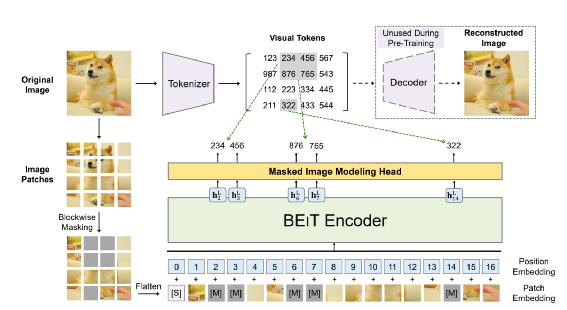
和StrucText 一样将文档中单词拆分成序列,每个单词采用RoBERTa【7】预训练的字向量。文本或图像序列中的Idx的Embedding表示,1D Layout特征在文本和图像上共享。对于每个单词所在的Segment有四个标量 (????, ????, ????, ℎ) 代表左上角的横纵坐标和宽高,然后分别对这4个标量做Embedding表示得到4个2D Layout特征。能看出来和StrucText不同的地方:不是每个单词的用自己位置坐标而是一个Segment的单词共享了Segment的坐标。Layout V3 没有采用CNN+FPN类似的模型去提取特征,而是直接采用VIT类似的方案,将文档图像拆成固定大小的Patch,所有Patch按照从左到右、从上到下的顺序展开为序列,再对一个Patch做线性变换到和文本特征一样的维度,用得到序列特征加上1D Layout特征作为图像特征。同StrucText 类似,LayoutLM系列也采用多头的自注意力来计算特征的相关性,不同于传统的自注意力权重计算,如下公式 (xi,xj为特征,WQ,WK为待学习参数矩阵):LayoutLM还考虑不同特征的相对位置关系,引入1D、2D-x、2D-y三个待学习参数,公式如下:在LayoutLMv3 中,同样设计3种自监督任务同StrucText 一样,Mask单词时采样概率采用泊松分布这里的基于图像的自监督任务采用BIET【6】模型,架构如下:目标是预测原始图片中被Mask的Patch块,如果只是做最原始的图像像素重建可能缺乏全局语义信息,所以BIET先采用DVAE【7】的模型,将原始图像表示为一个固定数量的离散整数值,其中离散值数量等于Patch块,离散值范围[0,8192],这样可以认为一个图片Patch有一个Idx值(类似Bert中的词的Idx),这样自监督任务可以设计为预测Mask掉Patch的Idx值。在第2个自监督任务中提到,会有图像Patch被Mask掉,所以第三部分任务设计为:预测单词所对应的图像Patch有没有被Mask掉,需要注意的MLM 任务中被Mask掉单词不能参与这个任务前边提到两种算法都是通过Transformer 来捕获不同字符或Segment(Word、Region)的特征的相关性,现在还有一种前沿的方向就是通过图卷积来捕获不同Segment(Word、Region)的特征的相关性(可以认为Transformer也是一种特殊的图卷积,所有Item相互有边连接)。在图卷积中核心的一个概念是邻接矩阵,对于一个N个节点图G,邻接矩阵A ∈ NxN,反映的是相连节点之间的相关性。GraphDoc属于利用图卷积来做文档智能的代表模型,整体架构图如下:和以上两个模型不同的是,GraphDoc关注的是区域的表征信息,区域代表是一个连续语义区域如文档图上不同的颜色区域代表不同的区域。GraphDoc 依然采用的是文本、图片、Layout三种模态的信息。对每个区域的文本通过Sentence-Bert编码后加上Layout编码信息,公式如下:注意Sentence-Bert采用预训练好的模型。li为layout编码,公式如下:将X轴的layout信息(region的最小x坐标,最大x和宽度w)以及Y轴的layout信息(region的最小y坐标,最大y和高度y)。注意一点:S0是代表一个占位符 [CLS]的编码特征。采用Swin Trasnformer【10】+FPN 作为骨干网络,在PubLayNet 【8】版面分析数据集合上进行预训练,最终采用1/4 下采样的FPN视觉特征P2。对应的每个Region bi的视觉特殊是对P2 做RoIAlign 【9】 并加上layout编码,公式如下:在GraphDoc中的特征融合分两部分,一部分是每个Region的融合,另一部分是来融合不同的Region(Region和节点会在后文混用)。不同于StrucText 或者LayoutLM V2 【10】,SDMG_R【11】等模型将每个Region的不同模态特征进行简单的融合(如Concat,相加,hadamard 积)进入前向多层模型,GraphDoc认为在不同的前向层中视觉和文本贡献不一样,所以设计有一个简单的Attention Gate来融合每一个Region文本和视觉特征,公式如下:z [0,1]就是学习到一个门控权重,g代表gelu函数,hi^l-1代表GNN第i个节点在l-1层特征输出,hi^0为第i节点的文本表示也就是前边的Si。可以认为最终mi^l就是学习到第i个节点最终的特征表示。GraphDoc中不同Region的特征是通过GNN图卷积来进行融合,GNN中一种实现方式是基于谱的图滤波器,核心思想是通过邻接矩阵【12】和原始节点特征矩阵相乘从而得到新的节点特征表示(一般还要乘以度【13】矩阵进行归一化)对于邻接矩阵中的节点i和j的边权重,原始的计算公式如下(所有W都是待学习参数):这种算法忽视了不同节点位置的相对关系,所以边权重又融合2D的位置编码信息,公式如下:xiv,yiv依次代表一个Region的四个顶点的x和y坐标,f^sinu为 sinusoidal 编码函数,得到学习到的邻接矩阵后,GNN多层前向传播过程中,图节点的输出特征计算公式如下。对于以上算法计算出来的邻接矩阵,GraphDoc又做了两方面优化:- 为了减少计算量和避免过拟合,邻接矩阵中每个节点只会保留数值最大的k条边;
- 为了让每个节点都能学到全局特征,显式的增加一个全局节点G,让这个G和其他所有节点都有边;
在GraphDoc中自监督任务比较简单,随机的选中一个Region,将选中Region的文本替换为[Mask]特殊标识进行GNN前向传播,将经过GNN学习到Region的表示和原始Region文本的SentenceEmbedding进行Smooth-L1的Loss计算,公式如下:从以上三篇论文解读可以看到,类似模型都是通过对多模态特征有效融合、捕获不同Segment(Word、Region)之间特征的相关性,最终学习一个好的Segment((Word、Region)表示。智能文档处理是来也的一个核心产品【14】,对于一篇文档,关键信息抽取、节点信息分类、节点信息预测都是我们需要解决的核心问题,对此我们基于前人的工作,针对性优化设计适合我们内部的模型,将在未来的博客中会为大家解读。1. https://arxiv.org/abs/2108.029232. https://arxiv.org/abs/2204.083873. https://arxiv.org/abs/2203.135304. https://mp.weixin.qq.com/s/WrCDYuvHw-QPMzzRHdOHeA5. https://arxiv.org/abs/1706.037626. https://arxiv.org/abs/2106.082547. https://arxiv.org/abs/1805.074458. https://github.com/ibm-aur-nlp/PubLayNet9. https://zhuanlan.zhihu.com/p/7313874010. https://arxiv.org/abs/2012.1474011. https://arxiv.org/abs/2103.1447012. https://baike.baidu.com/item/%E9%82%BB%E6%8E%A5%E7%9F%A9%E9%98%B5/979608013. https://blog.csdn.net/luzaijiaoxia0618/article/details/104718146/14. https://mage.laiye.com/