作为超级自动化的代表公司,来也科技推进的许多自动化解决方案中,需要OCR(光学文字识别)的能力,经过持续的积累和创新,目前来也自研的通用OCR识别在60多个复杂的中文测试集合上近70万的字符上,综合F1指标已经接近97%,远超国内大多数竞品公司。虽然综合指标上已经取得非常好的成绩,但是因为视觉深度学习OCR模型的天生缺陷,在一些长尾问题上依然识别准确率不高,典型的有以下场景:污渍干扰如红章、墨迹
形似字 如 “戍”与“戌、成、戊”
图像变形引起的字体变形
在OCR解码过程加入语义信息、典型如百度的SRN【1】,用CNN提取的图像特征进行解码时融入字符的语义信息,保证解码的时不光用了图像特征,还和前一个字符做了语义对齐。
加入预测语义信息的多任务。一般做法是在图片上通过马赛克视觉随机遮挡字符,最终有两个Head网络,一路是预测图片上的字符,一路是预测遮挡的字符,这样的模型就会学到基于语义的纠错信息。
第三种一般是将纠错作为一个和OCR识别不耦合的后处理模块。
针对这三种做法,我们经过仔细分析选择第三种做法,原因如下:在我们合成的大量图片样本中,为了让一些长尾字符如生僻字出现足够多的次数,我们增加包含生僻字的随机文本;为了让模型区分一些形似字故意让多个形似字出现在一个图片,所以合成图片上的文字缺乏语义连贯性。
真实的样本标注中为了减少成本,我们不标注单字位置,这样没法在真实样本上位置准确的 Mask 一个字符,所以第二种做法也不成立。
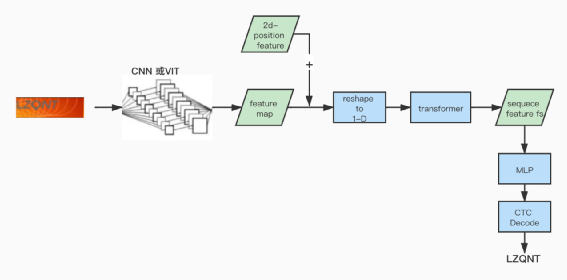
在正式进入纠错之前,先简单介绍来也OCR的整体流程和识别模型架构,这样可以更好的理解纠错服务的设计和实现思想。因为效果和性能、以及对训练数据的要求等原因,目前工业界的OCR基本还是以两阶段为主,先检测文本行(列),再对文本行(列)上的图片进行识别得到文字内容。来也的通用识别OCR也是遵循这个大两阶段的思路,只是在不同阶段增加了针对性的前后处理、减少该阶段模型的输入噪音和让输出结果更规整,整体流程图如下: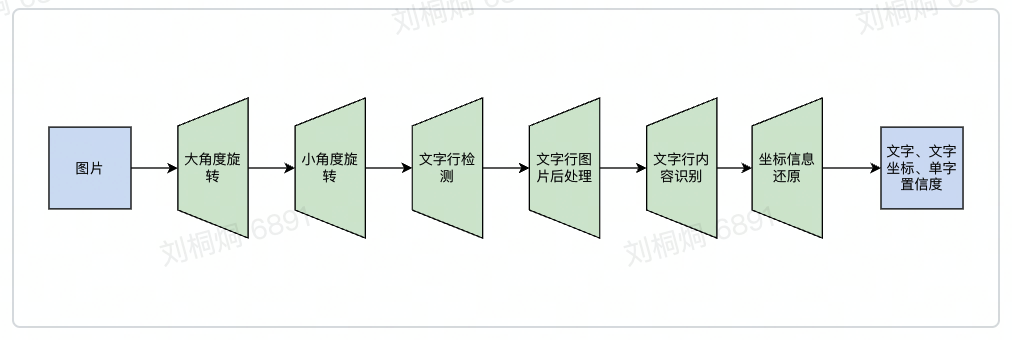
经过结果分析,前边提到的长尾识别错误主要是发生在文字行内容识别这个阶段,所以我们计划在这个阶段之后、坐标信息还原之前增加一个后处理模块,用模块将文字行内容纠正对。在模型训练的最后阶段一般会打开多任务训练如center-loss【2】和rdrop【3】提高模型识别的准确率。文本纠错是一个比较久远的实际问题,从基于字典的查找算法、到基于贝叶斯的传统机器学习算法、再到现在各种基于深度学习的纠错,我们如何从众多的方案中选择最适合我们的?我们从以下几个方面进行思考: 今天我感到飞长高兴 -> 今天我感到非常高兴
今天我感到常高兴 -> 今天我感到非常高兴
今天我感到非非常高兴 -> 今天我感到非常高兴
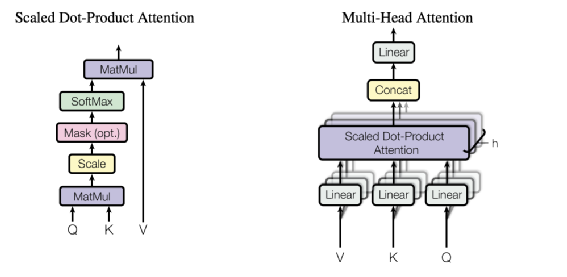
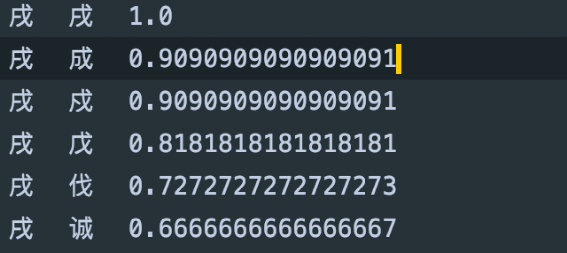
前边提过,目前来也科技 OCR 发生的错误主要是因为干扰或者形近字导致的误识别,所以我们要解决的问题只有第一种。我们需要纠错的是一个通用场景,所以基于词典的方案肯定不合适,只能选择采用模型的方案。如果是采用有监督的模型,就需要大量的 <OCR错误结果、准确结果>的标注样本对。在目前OCR效果已经非常好的情况下,要产生足够多的样本,需要非常高的成本,所以需要这种样本对的有监督模型不适用。可以从前边的流程图看到,我们整体OCR有多个阶段的图像处理模型如图像方向、文本行检测、文本行识别等,这些模块都需要GPU,为了节省昂贵的GPU,我们希望这个纠错模型比较轻量,可以在CPU上执行。基于上边的需求分析,我们决定采用一个轻量的非有监督的模型和方案实现我们的需求。文本纠错无论在研究还是实际的工业生产场景都有着非常广泛的关注,目前常用的模型基本可以分为两类:在单一的纠错任务上,第二种做法效果一般更好如 Soft-Masked BERT【4】,因为额外错字检测任务可以有效的缓解纠错中的误召回问题。所以我们计划采用第二种做法设计模型,将整个任务分成三大部分:再回到我们OCR任务上,OCR识别网络的最后一层是一个N分类任务(N为识别的字符表个数),从分类网络的损失函数来说,预测的一个字符越准确,那么这个字符在分类任务的softmax概率p也会越高。我们经过详细的测试发现这个推论在我们场景是成立的。具体的做法如下:在测试集合上,我们得到每个字符的识别概率,将概率阈值从1.0逐渐下降发现剩下字符的准确率确实在提升。通过这个做法不但验证了推论,还得知最佳概率阈值f(既低于这个阈值剩下字符的准确率提升不大)经过上述的实验说明,在OCR纠错场景只用字符softmax概率p作为先验知识来进行错误字检测就非常有用,不再需要额外的错误检测模型。在我们的方案中,字符的softmax概率p超过阈值f就认为识别无误,反之就进入下一阶段纠正字召回。经过统计分析,在绝大多数的OCR识别的错误场景中,一句话只有一个错误字符,再加上前边提到缺乏有监督的标注样本对,所以我们决定采用MLM(Mask Language Modeling)的方式,采用自监督训练任务来实现这个模型。对于模型设计,我们尝试两种方案,一种是只预测Mask掉的字符、类似完形填空的任务;第二种是预测整句话的所有字符,类似机器翻译。经过实验发现第二种效果会更好。举例 “中国浙江省杭州市临安区”这条训练语料会设计以下的任务(左侧是模型输入,右侧是模型输出) : 中国浙[mask]省杭州市临安区 -> 中国浙江省杭州市临安区 中国浙[随机字符]省杭州市临安区 -> 中国浙江省杭州市临安区在模型架构设计上,为了考虑减少延迟,所以我们计划采用非自回归的任务,废弃了Bert的Decoder 部分、只采用Encoder部分,综合性能和效果,采用标准的六层TransformerEncoderLayer 【5】堆叠,最大字符长度32位,head_num选择6,字符的embedding的维度选择128,最终将第6层layer的输出特征 在32个step上分别通过softmax分类得到预测字符。Transformer 很大的优势是通过 MultiHeadSelfAttention 可以捕获长距离字符间的相关性,下图为MultiHeadSelfAttention的示意图:图片来源:https://arxiv.org/pdf/1706.03762.pdf在训练语料上,我们抓取维基百科和全网的新闻数据,拆分了超过2亿条训练语料。不同于在原始训练数据前做Mask这种方式,我们改成在训练过程中做随机Mask,10%的概率将矩阵中一个任意字符换成随机字符,10%的概率将任意字符换成Mask字符。此外在训练数据上我们也做了一些更细节设计,主要有以下:最终的Loss上采用交叉熵,在Loss上我们也做了一些改进如下:在线调用时,我们将OCR识别的结果中,将softmax概率p低于f的字符换成OOV的字符,如句子的字符数超过32个,我们会对句子进行首尾截断确保这个Mask的字符位于句子中间部位。虽然识别的结果包含预测的所有字符,我们只使用这个低概率字符的预测的Top20字符作为召回,忽略其他位置的字符。通过前边的介绍可以看到,整个召回的部分是一个纯语义的模型,只用模型召回的Top1准确率会不够,例如输入 “山[mask]省经济增速下降”,预测的字符“东、西”随便用哪个都可能有错误,所以需要一个带有先验知识的排序模块选择最准确的字符。因为前边有提到错误的主要原因就是形似字或者字符有干扰,所以在我们这个任务最好的排序指标就是字符形状相似度,例如以下不同识别结果对应的纠错结果:所以排序这里的核心任务是如何计算字符的形状相似度,在这里我们尝试三种方法我们用宋体字符,将每个字符铺满绘制到白底的128*128的图片上,然后两两计算图片相似度作为字符相似度,在这里还做了其他尝试,比如利用AutoEncoder【8】得到字符图片的表征向量也计算过字符相似度。将OCR最后一层的softmax矩阵拿出来作为字符的表征向量进行相似度计算,这个矩阵的Shape为N X D,N为字符数,可以认为这个矩阵的每行D维向量就是对应的字符的表征向量,通过这个方法得到部分结果如下图(第三列为字符形状相似度):
有了字符形状相似度,所以排序的逻辑非常简单,召回的字符和待纠错的字符相似度若超过一定阈值,那么选择这些字符中得分最高的作为结果即可。纠错模型上线后,在我们内部70万字符的测试集合上,目前F1已经很高的情况下,任然对整体结果有超过0.03%的提升。以下为一些实际样例展示:因为文本行检测导致字符下边部分被裁切,“提”被识别“摆”,通过纠错模型可以正常纠正。字符过小,“绕”被识别为“统”,经过纠错模型可以正常纠正。因为红章干扰,“通”被识别为“涌”,经过纠错模型可以正常被纠正对。【1】 https://openaccess.thecvf.com/content_CVPR_2020/papers/Yu_Towards_Accurate_Scene_Text_Recognition_With_Semantic_Reasoning_Networks_CVPR_2020_paper.pdf【2】https://ydwen.github.io/papers/WenECCV16.pdf【3】https://openreview.net/attachment?id=bw5Arp3O3eY&name=supplementary_material【4】https://arxiv.org/abs/2005.07421【5】https://arxiv.org/pdf/1706.03762.pdf【6】https://mp.weixin.qq.com/s/6n9046pY8kd4GUss99nFNQ【7】https://zh.wikipedia.org/wiki/%E5%9B%9B%E8%A7%92%E5%8F%B7%E7%A0%81【8】https://www.jeremyjordan.me/autoencoders/