作为一种展示结构化数据的常用手段,表格随处可见。比如:信息收集、商品明细、企业年报等。
随着无纸化办公的流行,企业或个人经常需要将纸质报表上的信息按图片中表格的样式原样生成xls文件,再转录到各自系统中去。
即便可以用OCR(Optical Character Recognition,光学字符识别)技术辅助提取纸张上面的文字,但若要提取表格结构,就需要人工创建表单再将文本一个个复制到单元格中,这可是不小的工作量。
表格识别应运而生。
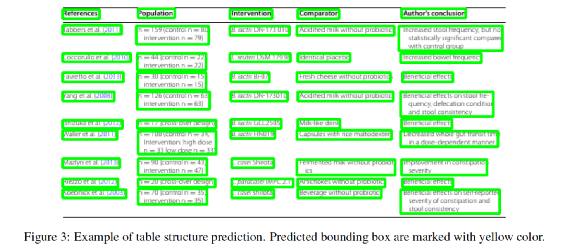
表格识别的任务是:识别图片中的表格结构,如表格的行数、列数、每个单元格的位置、所在行列及跨行跨列等信息,再辅以OCR的识别结果,还原表格的内容。如下图,左侧为原图,右侧为来也表格识别的可视化结果:在日常工作、学习中,常见的表格有如下三种,从左至右分别为有线表、半线表(三线表)、无线表:有线表最为直观,我们根据表格线即可区分不同的单元格。半线表和无线表则不然,他们的表格线部分缺失或完全缺失,我们需要依据表格内文本的空间分布来划分单元格,因此我们可以将半线表和无线表视为同一类表格,以下统称为无线表。目前两阶段OCR相比端到端OCR技术更成熟,效果也更好,所以工业界大多采用两阶段OCR。- 两阶段表格也是检测+识别,先检测图片中的所有表格区域,再逐一识别单个表格的结构
与OCR不同的是,我们暂时无法确定地说两阶段表格识别和端到端表格识别到底哪种方法更好,只能说两种方法有各自适应的场景。另外,还原单元格内的文本需要结合OCR的识别结果,不在本文的讨论范围内,本文仅讨论表格结构识别。值得一提的是,无论是学术界还是工业界,表格识别仍然是一个未解决的难题。基于两界现有的表格识别解决方案,我们调研了四种效果较好(比赛排名靠前)和技术成熟的表格识别方案。splerge解决的是两阶段表格中的识别任务,出自论文 "Deep Splitting and Merging for Table Structure Decomposition"。splerge由两个模型split网络和merge网络组成,这个名字也是分别取两个单词的前半部分和后半部分组合而成。pipeline如下图所示:首先由split网络预测表格中横线和竖线的位置,将表格切分成最细粒度的单元格(如上中图),再由merge网络结合split网络的输出和原图特征判断哪些单元格需要合并(如上右图,第一行的三个单元格需要合并,第一列第二、三行单元格需要合并),然后得出最终的表格结构。作者在论文中提出了projection pooling并应用在split模型中,简言之就是用整行(列)的池化取代一般的n*n池化,这样做有利于将行(列)的分隔特征扩散到整行(列),从而得出细粒度的行列分隔位置。merge网络输出四个矩阵l、r、t、d,分别表示每个单元格是否应该向左、右、上、下合并。不过在论文的结尾,作者提出了一些规则用于替代merge模型进行单元格的合并,并做了对比实验,结果发现split+规则的效果并没有比split+merge效果差很多。文中的训练数据均是从pdf抽取后进行标注的,作者没有公开。- 模型后处理相对简单,基于规则的合并策略也可以case by case的逐渐扩充,比较灵活。
- split模型预测的是整行和整列的分隔位置,无法应对倾斜表格,虽然可以通过优化前置的表格检测模型,使得送入SPLERGE的表格相对横平竖直,但如果表格内的文字本身就是扭曲的,那么这个模型就无能为力了。
- 在有线表的场景下,无论是merge模型还是基于规则,都存在无法合并单元格或错误合并单元格的问题。
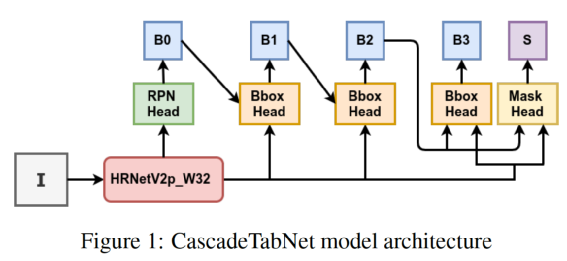
总的来说,SPLERGE适用于表格本身规整、文本无大幅度扭曲形变的pdf或文档这类场景。CascadeTabNet出自论文"CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents",由two-stage目标检测的老大哥CascadeRCNN针对性改造而来。为了尽可能保留表格内的细节,网络没有做过大的下采样并且选择了提取细节特征能力较强的HRNet作为backbone。网络结构如下图所示:CascadeTabNet是一个端到端模型,首先模型预测表格整体区域的proposals,之后送入Roi Pooling进行分类和bbox回归及mask分割。值得注意的是,bbox回归的并不是单元格的坐标,而是单元格内文本的坐标,这是因为有线表可以根据框线确定单元格位置,而无线表不行,因此模型由预测单元格改为预测单元格内的文本。
另外,文中提出了一种新的图片增强方法Smudge Transform,可以在保留表格结构的同时模糊文字,使得模型可以更加关注文字块的空间布局而不必过分关心文字特征: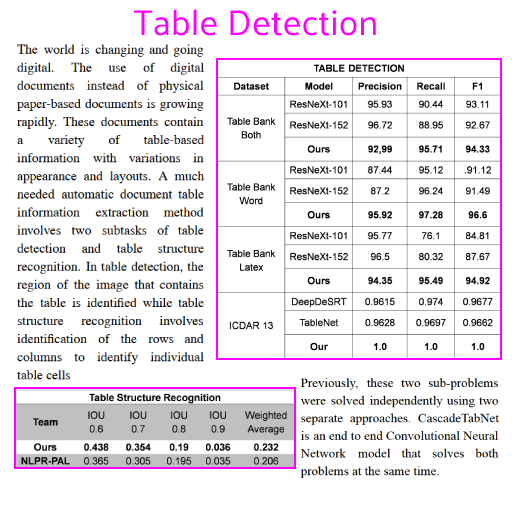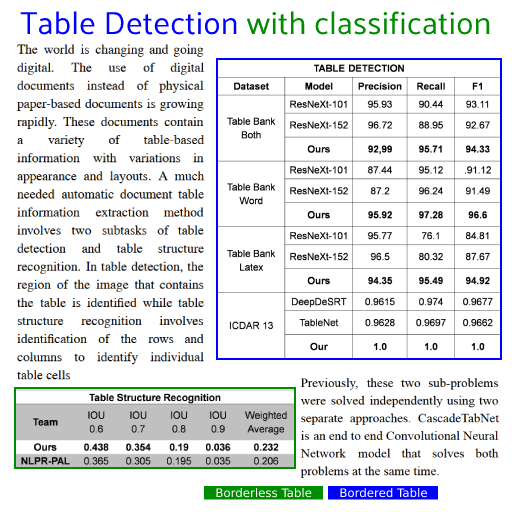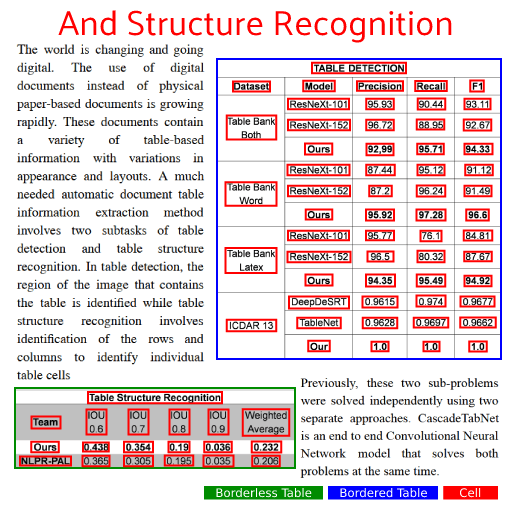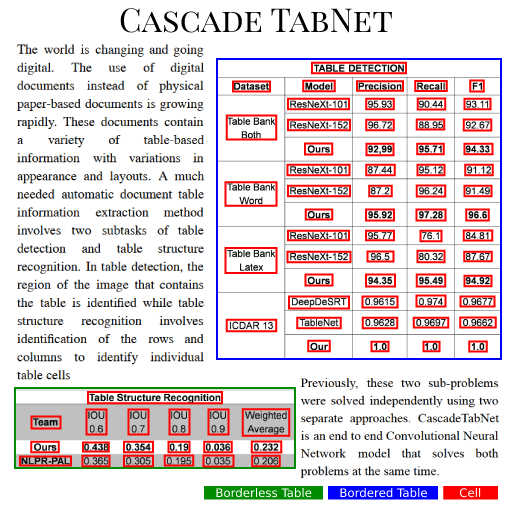
还原表格结构时,根据proposal的分类结果,有线表与无线表是两套完全不同的处理方式:有线表使用传统cv算法提取表格线还原结构,无线表使用回归的bbox推算表格的行列结构。
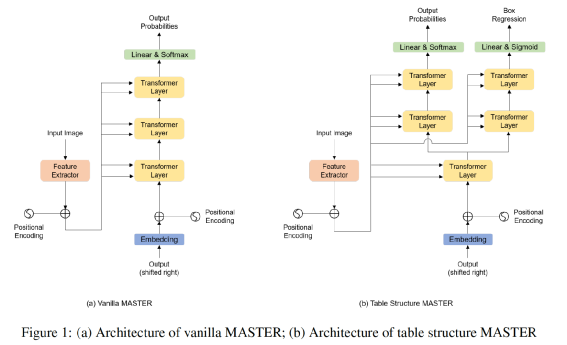
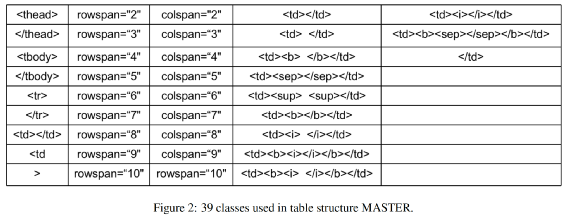
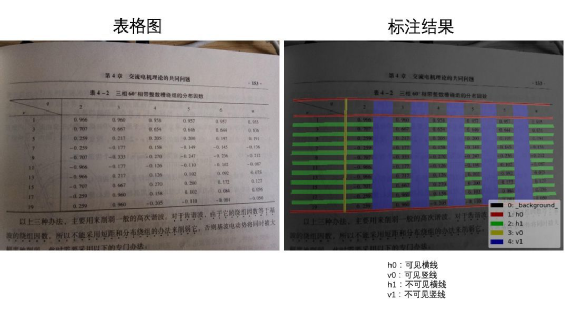
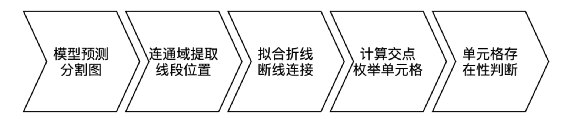
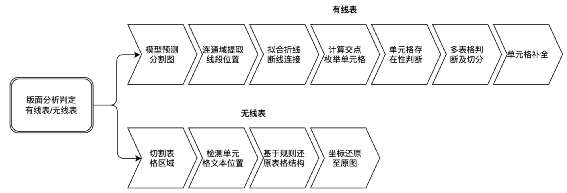
CascadeTabNet的效果十分出色,在ICDAR 2019的表格结构识别任务上取得了最高的精度。如果非要说CascadeTabNet缺点的话,可能就是过于重量级(cpu速度无法忍受,最好有gpu)、需要庞大的数据支撑,并且在部分有线表场景下,传统cv提取表格线的能力不尽如人意等等。首先不得不提到表格的另一种表示方式——html。如下左图,一个三行二列的表格对应的html文本如下中图所示。可以观察到,图中的绿色标签正是我们需要的表格结构:自然而然地我们想到,能否让模型依据表格图片直接输出其html序列呢?答案是肯定的!两阶段OCR中的条目识别就是从条目图片预测其中的字符,因此可以将预测表格html序列看成是一种另类的识别任务。TableMASTER出自论文"PINGAN-VCGROUP’S SOLUTION FOR ICDAR 2021 COMPETITION ON SCIENTIFIC LITERATURE PARSING TASK B: TABLE RECOGNITION TO HTML",此模型是ICDAR 2021表格解析比赛的第二名,来自平安科技团队。TableMASTER同样解决的是两阶段表格中的识别任务。TableMASTER模型由MASTER模型改造而来,MASTER模型正是两阶段OCR中的条目识别模型,同样来自平安科技团队。两个模型结构如下图所示。可以看出两个模型均采用了encoding-decoding结构,并且二者在encoding部分是一样的,区别在于decoding部分,TableMASTER增加了一个分支用于回归文本框的位置。作者使用公开的PubTabNet作为训练集(仅包含英文和数字,不含中文),在统计分析了其标签数据后,将模型的最大输出序列长度定为500,并设计了如下39个类别标签作为模型的输出,其中有两个,分别代表空单元格和非空单元格。模型的第一个输出OutputProbabilities的shape为(batch, 500, 41),其中41是上述39个类别加上额外的开始符和结束符,代表该特征位属于第i个标签的置信度。第二个输出BoxRegression同样是预测单元格内文本框的bbox而不是单元格,如下图所示,shape为(batch, 500, 4)。TableMASTER从一个非常新颖的角度来解决表格识别问题,是一次大胆的尝试,并且效果也是十分出色。PaddleOCR也用相似的思路开源了一个十分轻量的表格识别模型,并提供了PubTabNet数据集的预训练模型,略有不同的是paddleTable采用了RARE和GRU而不是MASTER和transformer。鸡蛋里面挑骨头的话,目前还没有足够的公开中文数据集来支撑模型训练,而且由于html序列里面是多个标签对应一个单元格, 因此能够预测的单元格数量实际上是远小于序列长度500的,并且网络结构中含有transformer和fc,需要固定输入图片尺寸,若是密集表格的场景,就需要提升序列长度上限和图片尺寸并重新训练模型。传统cv技术在表格识别方向曾经取得了一些成果,只是在深度学习兴起后,传统cv的效果就显得没那么突出了,主要是传统方法提取表格线开始无力应对日渐复杂的表格场景。但是提取表格线后重建表格的经验还是很有价值的,因此,我们可以考虑,用深度学习来提取表格线,重建表格则继续复用传统cv的经验。在腾讯cv组研究员撰写的一篇博客中提供了如下思路:有线表使用横竖线来区分单元格,半线表、无线表依靠行列间的空白区域区分单元格,因此模型的任务是将图像分割成四类:可见横线、可见竖线、不可见横线(区域)、不可见竖线(区域)。注意到,横线和竖线相交处的像素点是属于多个类别的。示例标注如下图所示:模型backbone是轻量的mobilenet,head也选择了收敛较快的unet。并且考虑到线条大多是横向和纵向的,为了使模型更加专注于提取横竖方向的特征,经实验,将模型的部分卷积核由3*3替换为5*1或1*5能够取得更好的效果。整体流程如下图所示:模型其实只做了检测表格线的工作,仍然有大量的计算工作集中在重建表格上,我们姑且将UnetTable视作端到端表格识别。基于表格线检测的表格识别同样有其固有的缺陷存在,最为常见的如纸张折痕干扰、打印复印的条形墨迹污渍干扰、密集表格后处理计算量大等等,但优点在于分割的线条或区域特征单一,模型的适用性会更广一些。综合了上述几种方案和我们目前的OCR流程以及客户的真实需求后,我们采用了UnetTable方案。主要流程如下:- 加入前置的版面分析判断图片有无表格,及有线表或无线表。
- 去掉了unet模型的不可见横线和不可见竖线分支,仅处理有线表。在实际训练中发现,客户的真实无线表并非理想中的长短相近的短文本,例如同一列的文本长度参差不齐,这时列间的不可见竖线区域就不能表示成规则的矩形或四边形,并且在无线表中有较大空白时,相邻的行列分割区域很容易粘连从而导致不能正确提取分隔线的位置,这甚至影响到了可见横竖线的表现,因此我们去掉了该分支。
- 我们的模型采用了u2net+cbam。在RPA的使用场景中,时常有线条颜色极浅的表格,因此我们加入了注意力机制来提取更细微的图像特征。
- 有线表后处理中我们加入了多表格切分和单元格补全逻辑。我们的真实使用场景中存在一图多表的情况,因此我们在后处理中加入了策略来切分多个表格。另外模型难免会有漏检线条,我们加入单元格补全机制来提高模型的召回率。
- 无线表分支基于检测单元格文本的思路,我们暂定使用了yolox,来应对长宽比不固定的情形。
在有线表格中,线的特征相比于文字特征来说更容易被网络学习到,因此通过适当的图像增强方法,就可以使得模型具有较强的泛化性,通过加入真实数据对模型进行微调也可以快速使模型适应更多的场景。有线表数据可以从标准pdf直接提取出来,因此训练数据是非常容易获取的,经试验,不使用任何真实数据训练出的模型与使用真实数据训练出的模型相差无二,某些场景下甚至更优。无线表格由于是检测单元格的文本,相比于有线表,无线表模型对数据的需求显然要更大些。我们的无线表模型还在不断优化中,敬请期待。由于表格不会脱离文字单独存在,因此我们设计了两个评价指标来衡量总体的表格识别效果:- 表格结构F1:IOU(标注单元格,识别单元格)≥0.9 视为识别单元格正确。即识别的单元格与标注的单元格iou超过0.9才认为单元格识别正确。由此可以计算一个表格的单元格准确率和召回率,进而得到表格结构F1。
- 表格结构+文字F1:IOU(标注单元格,识别单元格)≥0.9 且单元格内的文本与标注文本完全相同才视为单元格正确。即不仅单元格的iou要达到阈值,结合OCR后单元格内的文本也要和真值完全相同,这时才认为该单元格识别正确(错一个字也视作单元格识别错误)。由此可以计算表格+文字的准确率、召回率,进而得到结构+文字F1。此指标综合考虑了表格识别能力和OCR能力,较为严苛。
我们的测试集涵盖了超过70个场景的真实数据,在中文场景上,我们的“表格结构F1”和“表格结构+文字F1”均超过了 OCR 头部厂商: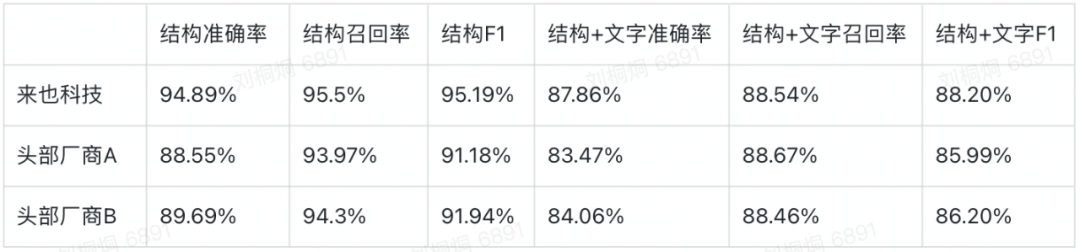
- https://github.com/pyxploiter/deep-splerge
- https://github.com/DevashishPrasad/CascadeTabNet
- https://github.com/JiaquanYe/TableMASTER-mmocr
- https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.4/ppstructure/table
- https://cloud.tencent.com/developer/article/1452973