‘小来早晚安’ 是来也科技旗下最为火爆的公众号(累计用户几千万 ,日活几百万),由小来无限团队独立运营。每当用户说完早晚安后,公众号都会推送给用户一张精美的打卡图。

为了更好的服务用户,我们用算法计算客户的喜好,为每个人推送个性化打卡图。个性化的关键特征之一就是 -- 用户性别。以前,用户关注公众号时,我们可以通过微信的接口获取到注册性别。但现在,随着国家数据安全法的实施,微信会把性别当做敏感信息屏蔽掉。于是,我们选择利用可获得信息进行性别预测,克服千难万阻也要给用户推送让他欢喜的图片~已知我们当前可利用的数据有:(模糊不清的)微信头像,微信昵称。我们利用这两类数据作为输入,预测出客户性别。一旦发现某一类数据有较明显的性别特征,就增加其权重,以提高预测准确性。
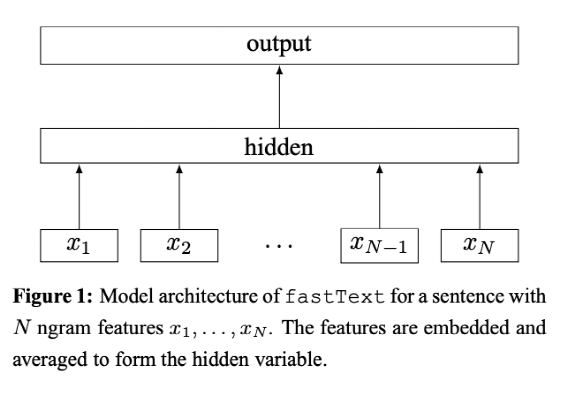
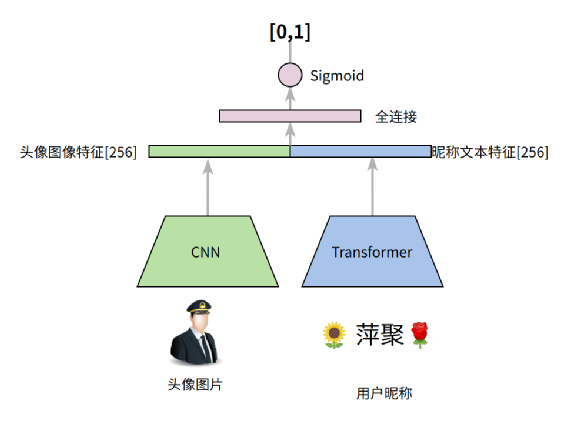
二. Baseline 模型 -- FasttextFasttext 属于一个非常简单的浅层神经网络,和 Word2Vec 中的 CBOW 模式很像,输入的自然语言通过 N-Gram 特征工程变成 Token,接下来 Token 通过 Embedding 查表得到对应的 Token 向量,所有 Token 的向量取平均进入全连接网络和分类网络得到结果,模型架构如下图:在性别预测中,最终目标为二分类(男、女)。只用户昵称作为输入,利用1500万数据进行训练,模型的准确率可达到 74% 。在 baseline 中,我们没有输入用户头像。不可否认,很多用户头像清晰地展现了性别特征,应该作为我们的重要输入。对此,朴素的想法就是融入多模态特征 m,图像和昵称一起作为模式输入,基于这个思路,我们设计了第一版模型:
- 昵称文本数据经过 transformer encoder 得到文本特征
- 文本特征和图像特征进行concat进行全连接得到预测结果
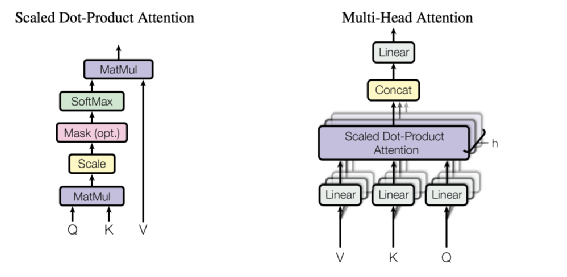
其中 CNN 经过思考选择了 DenseNet121,将 DenseNet121 的 “avg_pool” 层的输出通过全连接非线性变换降低到 256 维作为图像特征。DenseNet 的核心思想是将 CNN 前后的特征进行密集 concat,得到高层抽象特征的同时又能保证像素级别的特征。下图就是一个 DenseNet 的 block 的示意图,可以清楚看到每一次卷积的输出都会 concat 到后边卷积层的输出上:其中 Transformer 采用标准的四层 TransformerEncoderLayer 堆叠。最大字符长度32位,head_num选择4,字符的 embedding 的维度选择128,最终将第 4 层 layer 的输出特征 32X128 经过在 32 个 step 上取平均得到 128 维的向量。再经过非线性变化得到256维的向量作为昵称的文本编码特征。Transformer 很大的优势是通过MultiHeadSelfAttention 可以捕获长距离字符间的相关性。MultiHeadSelfAttention 示意图:虽然是字符,但是由于昵称中掺杂了大量的“火星文”。为了兼顾计算效率和效果,我们本次只采用头部字符作为词表。但在特征工程统计后发现:emoji 表情有很明显性别相关性。比如:????,女性用的比例要比男性高的多,所以我们找了全部的 emoji 表情加入了字符表,避免 Emoji 字符 OOV。采用 300 万数据做训练、10 万数据做训练,但是多模态 baseline 模型的准确率只有 67% ,比只利用昵称的 Fasttext 效果还差。于是我们仔细分析图片数据,进入了第二个版本的模型优化。人工分析了 300 张数据,发现一些规律。正是这些数据的存在会导致模型收敛不好:

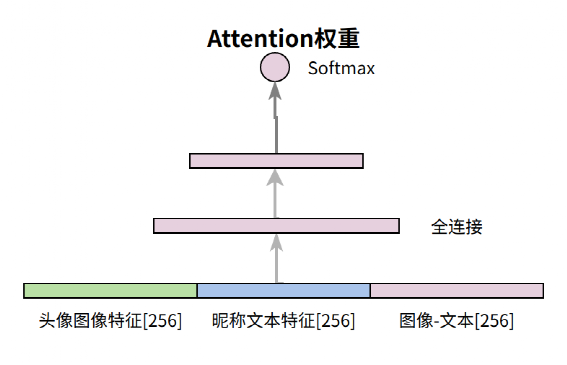
上述的第 2 种情况,两张图片经过 CNN 之后图像特征基本类似。但是对于“X国强”这个昵称来说,我们希望图像特征被弱化,昵称文本特征得到加权。基于这个思路,我们采用了视觉和文本特征的 Attention 机制进行融合,而不是 baseline 中基本的 concat,这个时候模型的架构如下:头像图像特征、文本昵称特征、头像和昵称特征逐位作差,三个向量Concat后得到768维的向量,再经过全连接网络和非线性变换后得到 2维的激活权重,代码如下:
def _attention(self, img_feature, name_semantics): features = [img_feature, name_semantics, img_feature - name_semantics] features = tf.concat(features, axis=-1) f = self.att_dense1(features) weight = self.att_dense2(f) weight = tf.reshape(weight, [-1, 1, 2]) concat_feature = tf.concat([img_feature, name_semantics], axis=-1) feature = tf.reshape(concat_feature, [-1, 2, self.feature_norm_dim]) self.log.info("concat feature shape is (%s)", feature.shape) feature = tf.matmul(weight, feature) self.log.info("after attention feature shape is (%s)", feature.shape) feature = tf.reshape(feature, [-1, self.feature_norm_dim]) return feature
在加入 attention 后预测的准确率达到 83%,采用 ImageNet 的预训练权重作为 CNN 的初始权重,最终的准确率可以达到了 85% 。
在上一小节提到,其中有约25%的数据无法通过头像以及昵称区分性别,所以在模型训练最终阶段 loss 抖动会比较明显。仔细分析后发现这些数据 Sigmoid 的概率区分不大,基本分布在 [0.45,0.65] 之间,这个时候一种方法是人工将预测置信度比较低的数据再次筛选一遍,考虑到数据量巨大而且存在部分性别确实无法预测的可能(对模型的准确率要求不是过高),所以采用了 mask loss 的办法,在模型训练后期将 sigmoid 置信度在一个区间的 loss 直接扔掉,代码如下:
''' 将sigmoid低于阈值的idx mask掉 eg:threshold=0.8 需要将prob>0.8 和prob<0.2 的保留 probs=[0.81,0.7,0.4,0.19,0.3,0.7] 的得到mask=[1,0,0,1,0,0]'''def get_mask(self, probs, threshold): probs = tf.reshape(probs, [-1]) mask1 = tf.math.less(probs, 1 - threshold) mask2 = tf.math.greater(probs, threshold) return tf.math.logical_or(mask1, mask2)
def mask_loss(self, loss, probs): mask = self.get_mask(probs, self.mask_loss_thres) mask = tf.cast(mask, loss.dtype) recall = tf.reduce_mean(mask) loss = loss * mask ''' 扔掉了一部分数据的loss,所以需要将剩下的loss放大 防止模型将结果全部预测到这个区间 ''' loss = tf.math.divide_no_nan(loss, recall) return loss
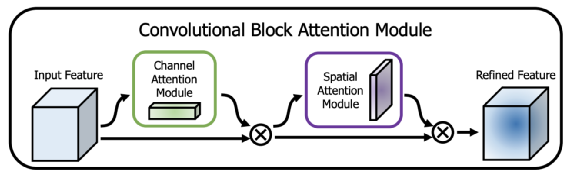
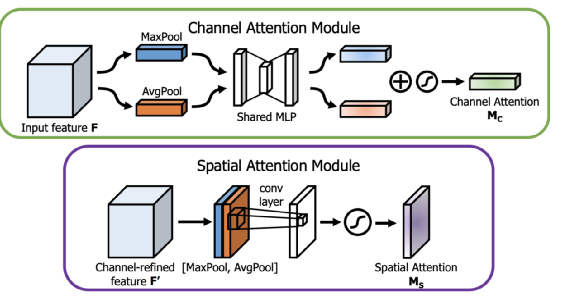
其中在对 loss 进行 mask 时,需要注意:mask 部分样本的 loss 后,需要将剩下的 loss 根据 recall 的数量等比放大。不然深度学习模型会取巧,会将易于区分的样本也预测成中间置信度。这样的预测结果会因为 mask loss 的原因使 loss 等于 0。基于前边的数据分析:有80张图片无法通过头像和昵称区分性别,所以模型预测的准确率上限在 (220+80/2)/300=86.7%。模型的准确率和上限基本一致(已经很准确了)。CBAM 是视觉任务上非常优秀的一个注意力机制,既考虑了通道上的注意力机制又考虑了空间上的注意力机制,而且输入和输出的特征维度完全一致可以即插即用。在常见的计算机任务中经过CBAM的特征处理后,基本上都能获得不错的效果提升。我们尝试在 DenseNet 的每一个 Dense Block 输出的特征插入 CBAM,但准确率并没有提升。猜测是图像只是二分类,和 attention 的细粒度特征关系不大。梯度中心化是阿里达摩院提出的一种优化器策略,通过简单的将梯度向量中心化为零均值,从而提高模型训练的稳定性和提高最终的结果,使用也非常简单,只需要在优化器中加入很少的代码即可,比如以下是对 AdamW 进行梯度中心化的代码:
class GCAdaW(tfa.optimizers.AdamW): def get_gradients(self, loss, params): grads = [] gradients = super().get_gradients() for grad in gradients: grad_len = len(grad.shape) if grad_len > 1: axis = list(range(grad_len - 1)) grad -= tf.reduce_mean(grad, axis=axis, keep_dims=True) grads.append(grad) return grads
此外,经过对昵称的特征分析后,发现女性用 emoji 的比例偏高,所以又手动设计了一些昵称特征:该四维向量除以 32(最大昵称长度)作为特征,直接和头像昵称的网络特征拼接输入到全连接网络。加入手工特征后,模型准确率没有提升,说明 Transformer 已经很好的捕获这类特征关系。最终训练好的模型导出 Protobuf,通过 CPU 版本的 Tensorflow Serving 提供 Restful API 供业务方调用。性能说明:在 8 核 2.3GHz 的 I9 Macbook 上,单次请求的平均耗时在 85ms。为了提高预测速度,做性能优化如下:将 CNN 的 DenseNet121 替换为 MobileNet V2,准确率降低 0.8% 但是耗时降低到了 25ms。
https://arxiv.org/pdf/1607.01759.pdf
https://arxiv.org/pdf/1607.01759.pdf
https://arxiv.org/pdf/1706.03762.pdf
https://arxiv.org/pdf/1807.06521.pdf
https://arxiv.org/pdf/2004.01461.pdf
https://arxiv.org/pdf/1711.05101.pdf
https://arxiv.org/pdf/1801.04381.pdf