

本文总结了在OCR的核心任务--文本识别上应用自监督学习的近期进展,可与来也技术团队之前两篇公众号文章,《自监督学习在计算机视觉领域中的使用简介》和《MoCo系列自监督学习模型和在来也业务中的实践》一起阅读。
一、前言
用监督学习训练深度神经网络的效果受制于标注样本的规模,而收集和标注大量样本的成本是非常高昂的。自监督学习方法从可低成本获得的无标签样本中挖掘数据内在结构信息,作为监督信号来训练网络,更加类似于人类在幼年时自我学习的方式。由于自监督学习所具备的这些优点,它在过去的几年间已经在NLP和CV领域得到了迅猛的发展。自监督学习的范式分成两阶段,在预训练阶段使用无标签样本在设计好的代理任务上训练网络得到一个通用性特征表征,此后再将预训练得到的特征表征迁移到需要监督学习、而标签数据相对不充足的下游任务上,下游任务上的表现也就可以来衡量自监督学习特征表征的效果。
目前,视觉领域自监督学习主要集中于两个热点的方向。一类是基于对比学习(Contrastive Learning)的方法,如MoCo系列、SimCLR系列等,构建同一样本的不同增强视图作为正样本对,不同样本的视图作为负样本对,通过学习在空间中拉近正样本对、拉远负样本对来得到特征表征,沿着这一路线发展,更加简单不需要负样本的BYOL、SimSiam等方法也被相继提出。另一类是基于掩码图像建模(Masked Image Modeling)的方法,如BEiT、MAE、SimMIM等,这类方法通过学习重构随机遮掩的图像patch的token或像素的方式来获得特征表征。
OCR系统中最关键的两个环节是文字检测和文本识别。文字检测负责定位文本条目在图像中的位置,文本识别则负责将文本条目图像转换为对应的文字内容。在文本识别的问题上,由于一直以来合成样本的广泛使用,似乎监督学习对标注数据量的渴求问题被一定程度缓解了:如在自然场景文字识别任务上,有SynthText这样有名的合成数据集;在文档场景文字识别任务上,还可以从带文字信息的PDF文档中生成文本条目数据,如微软的trOCR模型在其第一阶段预训练中就使用了从两百多万pdf文档中合成的6亿多文本条目;在手写识别任务中,也经常会使用各种基于GAN网络的方法来生成的手写文本图像样本。然而,最近已经有越来越多的研究工作表明,合成样本与真实样本之间存在域间差异,过于依赖合成样本会限制模型在真实应用场景中的性能。因此,在文本识别任务中,利用无标签的真实文本图像做自监督学习逐渐为研究者所重视,近期也陆续出现了自监督学习相比完全监督学习更为优越的结果。本文就试图总结下近期几篇文本识别自监督学习的代表性工作。
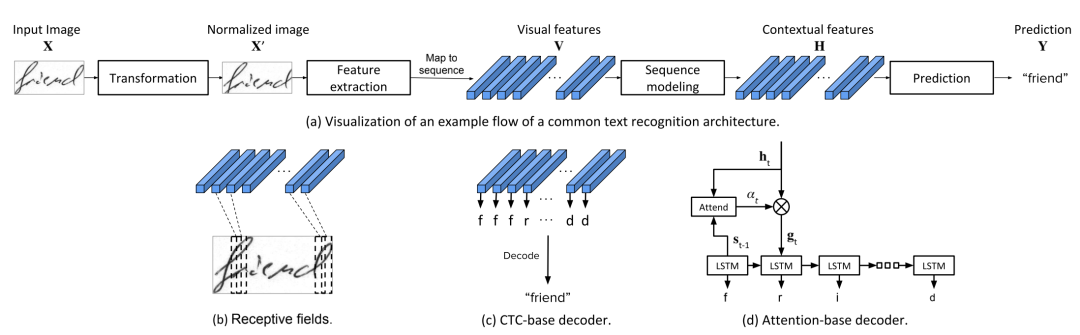
二、文本识别的主流模型架构
经过多年的发展,文本识别的主流方法是把它作为一个序列到序列(Sequence-to-Sequence)的问题来处理,在实践中其网络结构由如下的环节顺序组成:
Transformation(可选):比如通过TPS变换或STN网络, 对文本条目图像进行几何矫正使其规整化。
Feature Extraction:通常采用CNN网络作为基础的图像特征提取器。
Sequence Modeling: 在CNN得到的图像特征之后,使用RNN网络如常见的BiLSTM进行序列建模以获取文本行图像中上下文信息,也可以使用级联的Transformer Encoder Block来达到同样的目的。
Decoder: 根据不同的模型方法,有CTC Decoder , Attention Decoder, Transformer Decoder 等各种不同的选择。
在这个流程中,Feature Extraction 和 Sequence Moding这两部分可以看成文本识别中的Encoder,随着Transformer在图像领域的应用,传统的CNN+BiLSTM的Encoder结构也完全可使用一个VIT来取代。
三、文本图像上自监督学习要考虑的因素
一些简单辅助任务的自监督学习方法是可以直接从通用图像领域迁移到文本识别领域使用的。比如百度的ppOCR v3模型为提升识别效果所用的策略之一TextRotNet,就是将通用图像中预测0/90/180/270度图像旋转的自监督学习网络RotNet直接用于文本图像,获得识别率的提升。
而更多的自监督学习方法的设计则需要考虑文字的自身特点:
如对比学习方法想要使用在文本识别中,需要考虑文本行作为一个序列对象,是否适合直接作为对比学习中的实体,这也是下一章中SeqLR文章的出发点。
场景文字基于其产生的过程机制,具有与一般图像不同的特点,比如笔画宽度、颜色的一致性,后面SimAN的文章也是挖掘这一特点设计自监督任务。
前面讲了文本识别的Encoder包含了Feature Extraction和Sequence Modeling,具体到不同的自监督方法上,其预训练的特征表征可以用完整的Encoder,也可以把Sequence Modeling上下文建模的部分从Encoder中拿掉,只使用CNN Backbone做图像特征,在下游任务Finetune时再加回Sequence Modeling。
文本图像与通用图像上衡量自监督学习效果的做法也有一些差异。对通用图像来说,在预训练阶段获得Encoder特征表征之后,一般要在Linear probing 和 Finetune 两种模式下做下游图像分类任务来衡量效果。Linear probing指冻结Encoder参数,后面只接简单的线性分类器,来衡量特征表征的质量。Finetune模式指开放Encoder的参数可调节,用部分或全部标签样本去finetune整个网络,与使用同样这些标签样本从Scratch开始训练网络的监督方法比较效果。此外,还常常用目标检测、实例分割等其他不同类型的下游任务衡量通用图像的自监督学习效果。而对文本图像来说,设计自监督学习任务预训练得到表征后,下游要做的任务不再是分类,而是要加上decoder,在冻结Encoder和Finetune的不同模式下做文本识别,衡量文本图像表征的质量,其他类型的迁移学习任务则有文字图像分割、文字图像超分辨率,以及与文字、字体相关的生成类任务。
四、代表性的几篇文本识别自监督学习文章
以下列举了文本识别自监督学习的三篇paper,它们自监督任务的设计各有不同,SeqCLR是典型的对比学习,SimAN基于生成描述的路线,而最近的一篇DiG则试图结合对比学习和生成方法两者的优点。
1. SeqCLR
文章链接 https://arxiv.org/pdf/2012.10873.pdf
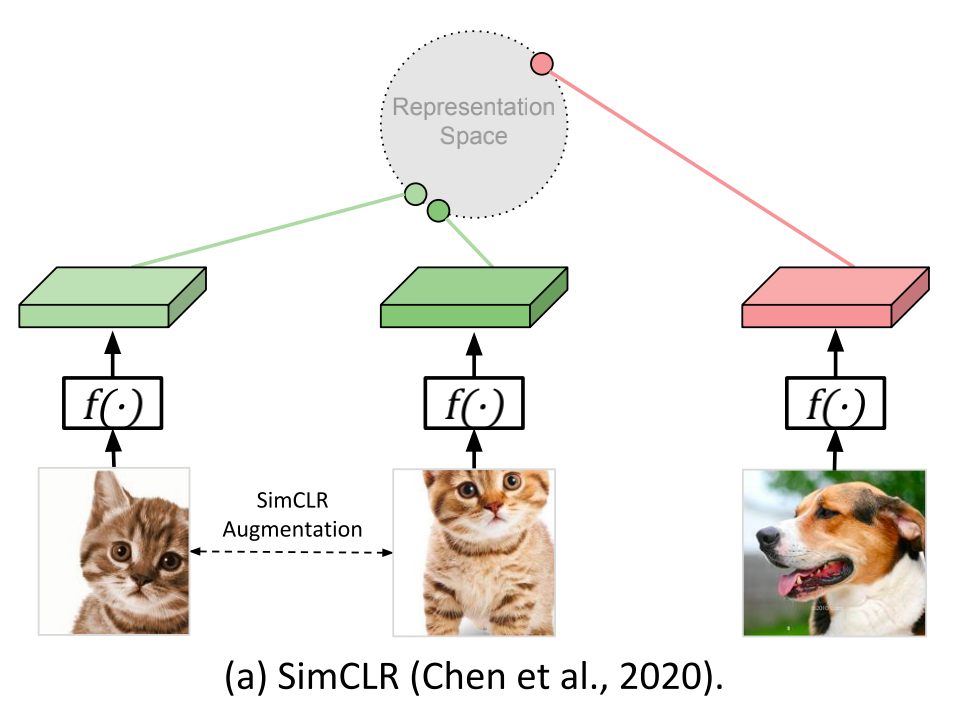
以色列科技大学和Amazon,发表于CVPR2021
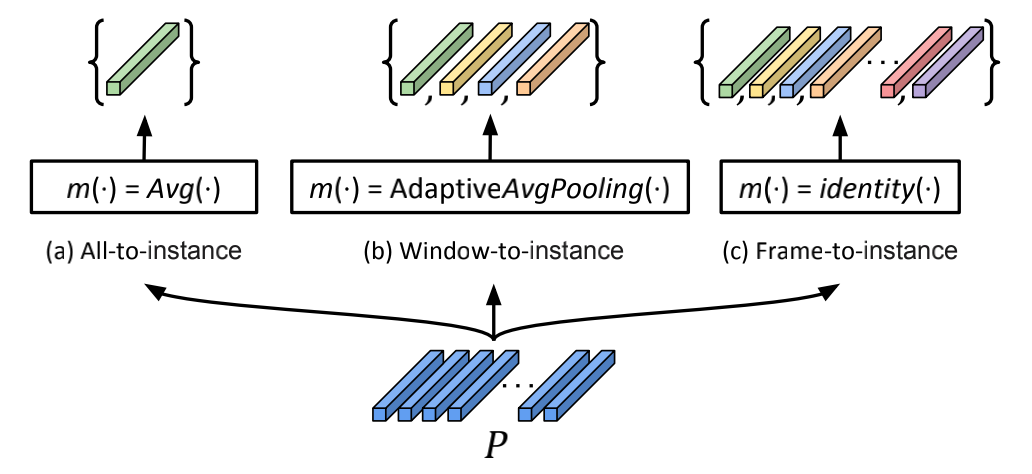
SeqCLR是较早将对比学习用于视觉序列识别的工作,作者说明了通用图像中的对比学习方法(如下图(a)中所示的SimCLR)并不适合于文本图像,因为文本图像具有序列性可看成由连续帧组成,不同帧可能对应不同的字符类别,对“全图”简单进行图像扩增比如翻转,或水平方向上大的裁切将破环帧之间的顺序,导致对比学习的效果不佳。SeqCLR的解决方法是将每个特征图划分成若干实例,让这些实例作为对比学习中的对象单元,从而使Batch中的每个图像都可以贡献几个正例对和多个负例(如下图(b))。 对文本图像的增强要保证实例在序列中的顺序关系稳定不变,因而需要对增强的具体类型做一定的筛选。
|
|
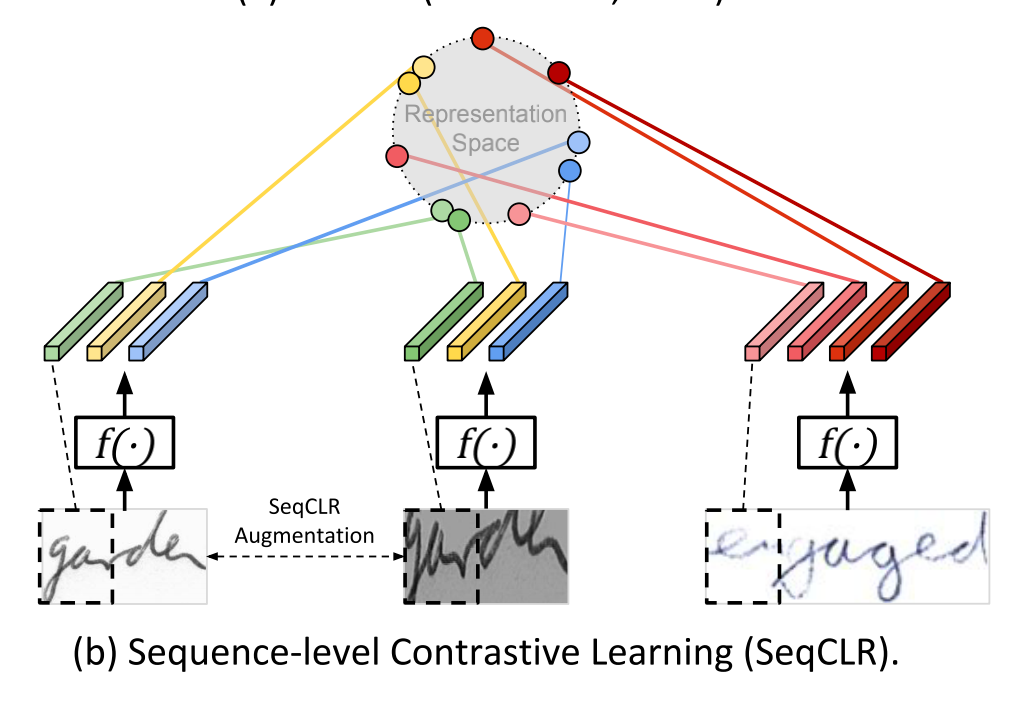
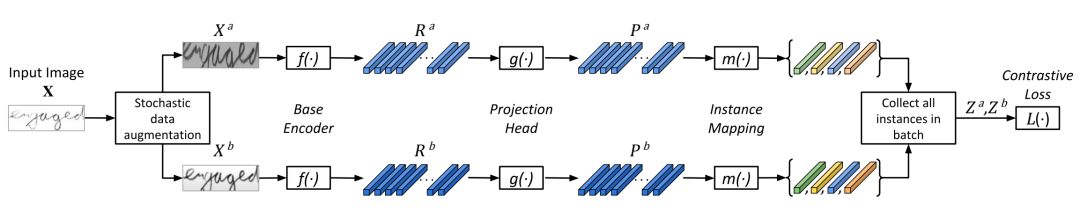
架构设计
SeqCLR主要由五个模块组成:
随机图像数据增强模块,旨在确保序列级的比对,该操作将一个Batch中每个图像 转换为两个增强图像 和 。图像增强由对比度拉伸、高斯模糊、锐化、裁切(主要做纵向裁切、横向裁切幅度必须小)、透视变换、 分段仿射变换几种操作随机组合而成;
图像Encoder 、对于每对增强图像,Encoder提取一对序列表征;
投影头 ,由小型MLP网络构成,并为适应不定长的序列输入做了专门处理;
一个实例映射环节 ,从文本图像特征图中的每几个连续帧中产生一个单独的实例,这些实例会成为对比损失中的原子元素;
对比学习的损失函数采用InfoNCE。
其中在实例映射( Instance Mapping)的环节,可以将所有帧映射为一个实例(All-to-instance),这样对图像增强带来的序列错配有一定的适应能力,但会大大减少一个batch内的负样本数量不利于对比学习;也可以将每帧映射为一个实例(Frame-to-instance)为对比学习获得更多的负样本;两者的折中是将连续若干帧映射为一个实例(Window-to-instance)。
实验结果
SeqCLR文章在手写数据集和场景文字数据集上,做了Decoder evaluation(如前所述,冻结Encoder参数,对应于通用图像自监督学习中的Linear evaluation)和分别使用5%,10%,100%的标签数据fineune的 Semi-supervised evaluation实验。
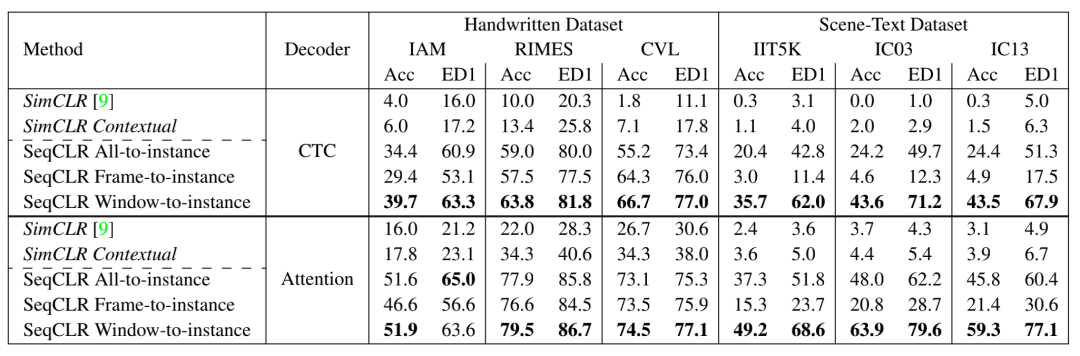
Decoder Evaluation
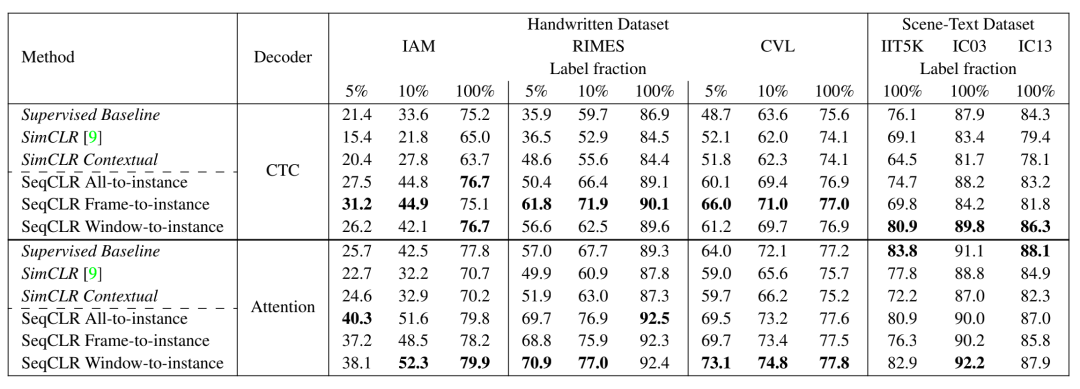
Semi-supervised Evaluation
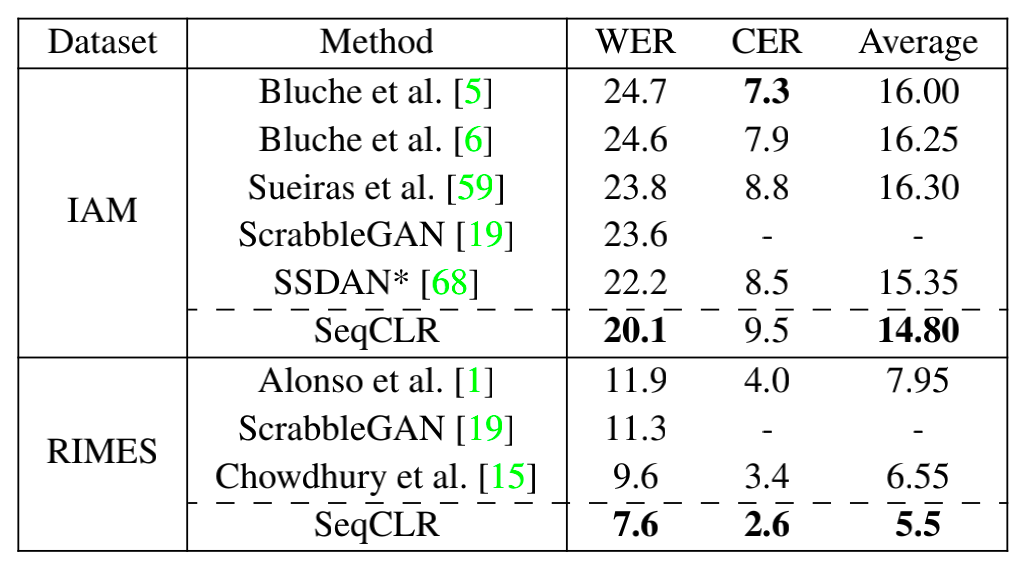
手写数据集上与SOTA方法的错误率比较
实验中的主要结论如下:
在手写文字和场景文字数据集上的实验表明,无论是在Deooder Evaluation 还是Semi-supervised Evaluation的实验设置下,SeqCLR的结果都要优于非序列的对比学习方法SimCLR。
在instance mapping方法的选择上,Window-to-instance 的策略表现最好,如前所述Window-to-instance 在增加对比学习负样本数量和鲁棒适应图像增强带来的序列失配两个因素上,达到了更好的折中。
此外,相对于场景文字数据集,SeqCLR在手写数据集上的表现更突出。当用100%标签数据Finetune时,SeqCLR在Benchmark手写数据集上达到了新的SOTA,其中在IAM上的单词错误率降低了9.5%,在RIMES上的单词错误率降低了20.8%。
2. SimAN
文章链接:https://arxiv.org/pdf/2203.10492.pdf
华南理工大学,发表于CVPR202
场景文字图像有其内在的特点,比如同一文本行中颜色、纹理、笔画宽度的一致性等。在深度学习流行之前的年代,OCR领域的研究者们曾经根据这些特点设计了很多有效的手工特征,比如基于连通域分析(CC)、笔画宽度变换(SWT)、MSER(最大稳定极值区域)的各种特征。现在利用这一特点,我们可以设计自监督学习任务解耦和重新组合图像patch中的风格与内容,实现自监督表征学习。
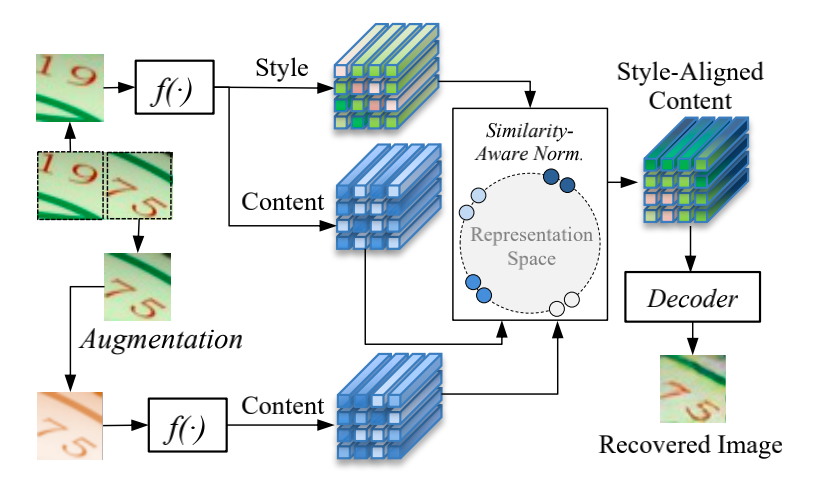
架构设计
从一个文本行图像上随机crop两个位置相邻的图像patch, 和 ;
对其中的patch 做图像增强得到 ,由于后面涉及到重建,因此在这里改变空间信息的图像增强方式都不能使用,而只能使用对比度拉伸、模糊、锐化、加噪等;
基于前述分析,可以由增强后的图像 在 风格的引导下重建 。在这个辅助任务中训练得到的图像Encoder,就能成为场景文字的一个高质量表征。
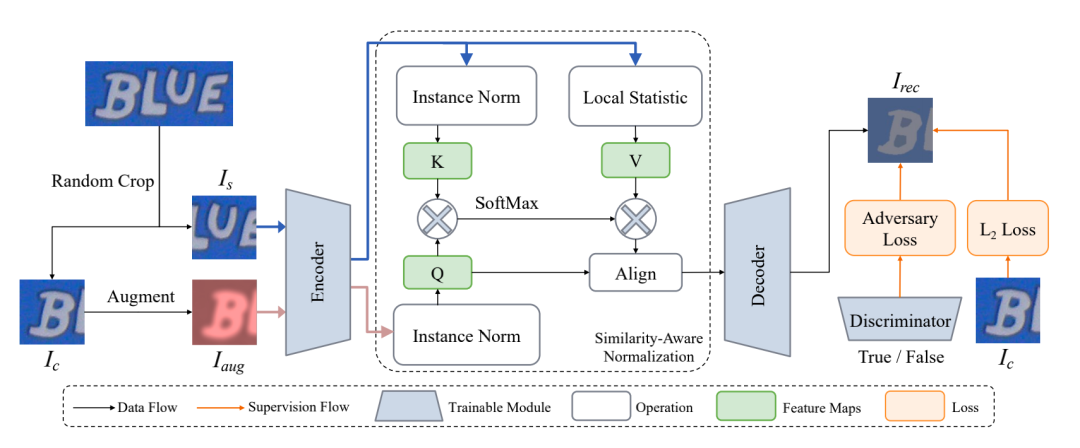
为了实现此目的,文章在Encoder-Decoder(在文章中 Encoder为ResNet-29, Decoder为FCN)的结构中加入一个SimAN模块,根据相邻图像patch内容的相似性对齐风格:
对特征图 ,使用Instance normalization得到内容的部分
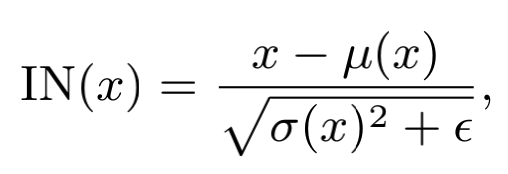
其中统计值 和 在每个样本的每个channel上计算。
和 经Encoder编码和instance normalization分别得到表示patch内容的 ,
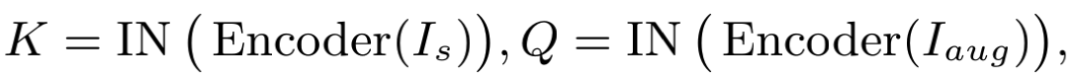
在 上计算特征图的局部统计量 和 ,作为表示patch风格的
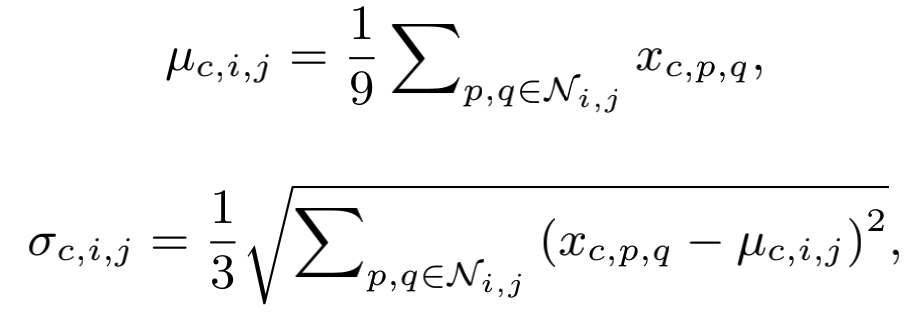
SimAN使用Scaled dot-product attention的方式将风格对齐后的结果为
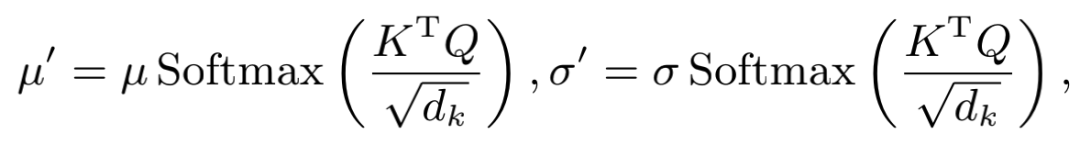
然后做instance normalization的逆变换,将对齐后的风格参数 和 加诸于Q之上
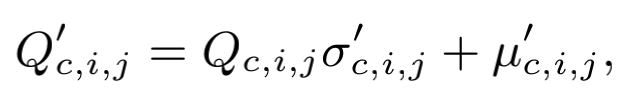
这一系列操作与图像风格迁移任务中的AdaIN有些形似,但AdaIN是使用特征图的全局统计量直接把一张图像的风格嫁接在另一张图像上。在文章的附录中作者也在probe evaluation实验中比较了SimAN与AdaIN两种方式,实验证明SimAN的效果更好,其所做的相似度估计有助于对特征表达的学习。
最后Q'经过Decoder得到重构的图像Patch 。
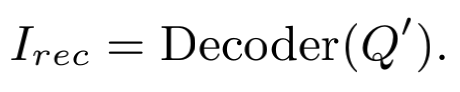
把从真实图像patch 到重构图像patch 的网络看成Generator,用一个Discrminantor来区分输入图像patch是来自真实图像还是Generator。整个网络训练的损失函数为Adversary loss与L2 loss的加权。在训练时,需交替优化Discrminantor 和(Encoder, Decoder)的参数,即
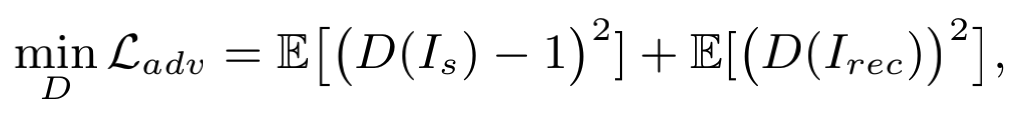
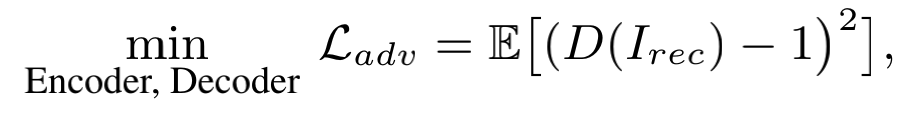
文章中阐述,只有当自监督学习Encoder提取出的特征表征足够强,能够同时很好的表达图像patch的内容和风格时,SimAN模块才能有效的辨识内容并正确对齐风格,进而才会得到好的图像patch重建结果。那么其实反过来,对上述网络损失函数的优化也就强迫了Encoder去学习更好的特征表达。
实验结果
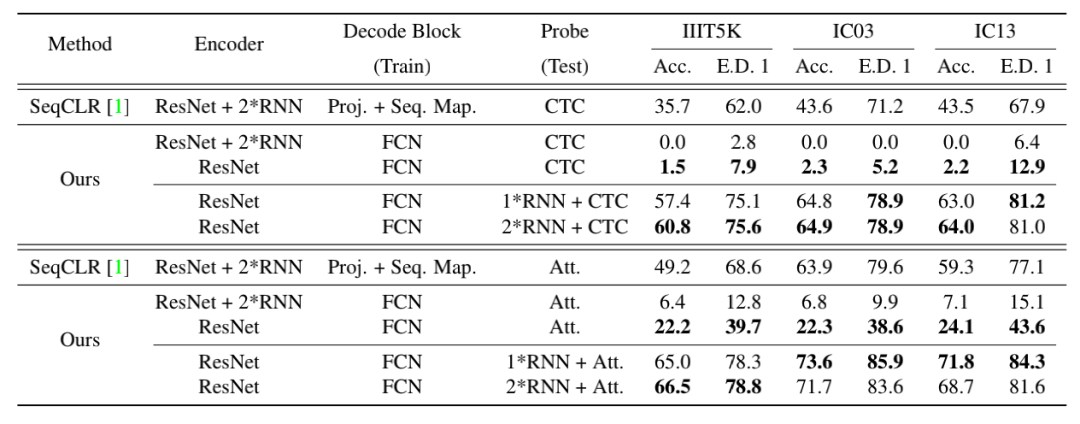 Probe Evaluation
Probe Evaluation
 Semi-Supervision Evaluation
Semi-Supervision Evaluation
文章仍然是做了Probe evaluation(冻结Encoder)和 Semi-Supervision evaluation,预训练阶段使用SynthText数据集的图像但不用标签,Finetune的时候再使用标签。实验中获得的结论如下:
Probe evaluation的实验表明,对本文设计的自监督网络结构而言,把Sequence Modeling(2*RNN)的部分放在Encoder里会降低特征表征的效果,因为重建图像patch是依赖local pattern的,而sequence modeling引入的上下文信息会扰乱这种学习,所以文章在Encoder里只保留CNN backbone。相反的,在做evaluation的时候是需要加上sequence modeling模块的。
此外,在预训练阶段如果使用的不是合成数据集SynthText,而是真实无标签数据集 Real300K,probe evaluation效果会提升很多,这也说明真实样本的多样性有助于学到更好的特征表征。
与之前的自监督方法SeqCLR的比较:无论是Probe evaluation还是Semi-Supervision Evaluation, SimAN都取得了更好的结果。而在Semi-Supervision Evaluation实验中,各个场景文字数据集上SimAN finetune的结果都稳定超过相应的全监督学习结果,且提升的效果与SeqCLR相比更加稳定。
除了在场景文字识别上的实验证明了SimAN的自监督学习的特征表达能力。在其他类型的下游任务,如文本图像数据合成、文字替换编辑、字体内插任务的实验中,也都表现出这一方法更广阔的应用可能。
3. DiG
文章链接:https://arxiv.org/pdf/2207.00193.pdf
华中科技大学和华为,收录于2022 ACM MM
人类认知文字的过程是同时通过“读”和“写”来进行的,受此启发这篇文章提出了将对比学习和掩码式图像建模融合在一起的自监督框架,以同时学习文本图像中的区分性特征和上下文信息。该框架有两个分支,其中对比学习的分支用于学习文本图像的区分性特征,模仿人类"读"的行为;而掩码图像建模分支用于学习文本图像的上下文生成,模仿人类“写”的行为。
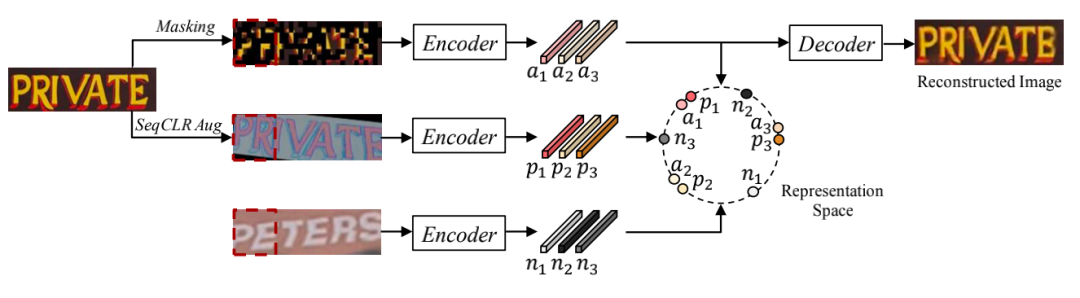
架构设计
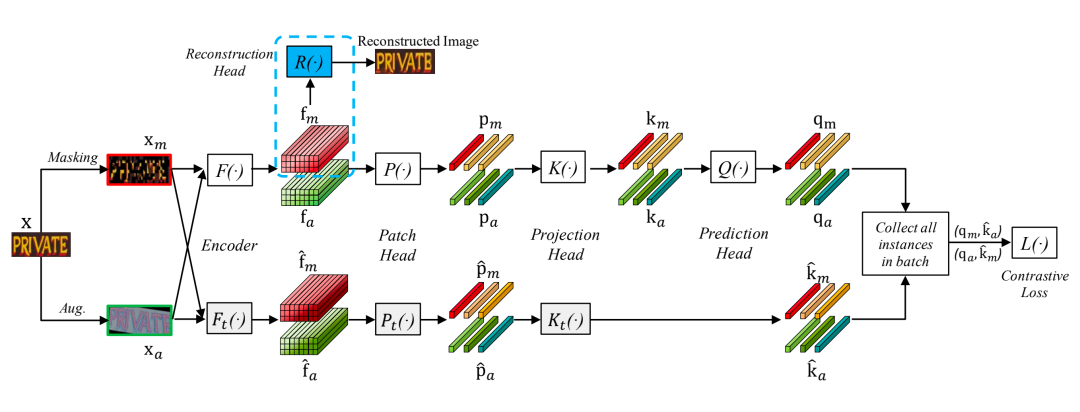
在DiG网络中,原始的输入文本行图片 通过处理,分别得到一个随机掩码的图像 和一个经过增强的图像 。两张图像被送入ViT图像Encoder 后分别得到掩码图像和增强图像的特征表征 和 。在掩码图像建模的分支,掩码重建模块用于恢复掩码区域的像素值。在对比学习分支, 和 依次通过Patch head、Projection head 和 Prediction Head得到 和 。同时,从包含图像Encoder,Patch head和Projection head的动量分支中得到 和 。最后,同一个batch中的query和key被收集起来计算对比学习的loss。
对比学习分支基于MoCo v3的结构,并做了一些小的改动:
数据增强:除了SeqCLR使用的数据增强方式之外,文章还增加了颜色抖动、灰度化等方式来增强预训练模型的特征表达能力。
Encoder :文章采用了ViT作为特征编码器。输入图像被分为不重叠的4x4块,然后通过线性映射编码和位置编码,输入到随后的Transformer层。
Patch head :参照SeqCLR对序列的处理,将文本图像的特征图按照水平方向分成了4块,并将每一个块作为对比学习的实例对象。
Projection head :该模块为一个3层的MLP。
Prediction head :该模块和Projection Head结构一样,但只是两层的MLP。
动量分支:该分支由图像Encoder , Patch head 、Projection head 组成, 、 、 与对应的 、 、 结构相同,只不过采用指数滑动平均策略对其参数进行更新。
掩码图像建模分支基于SimMIM实现:
掩码策略:采用Patch对齐的随机掩码策略,对输入VIT编码器图像中的60%的Patch打上掩码,用可学习的mask token vector代替每个掩码区域。
Encoder:掩码图像建模分支和对比学习分支共享同一个ViT编码器。
预测模块:参照SimMIM的做法,在Encoder后接了一个轻量的线性层对掩码区域像素值进行预测。
重建目标:掩码区域的原始RGB像素值
损失函数是两部分损失 和 的加权, 加权系数
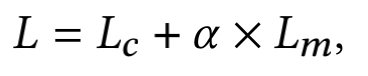
其中 是对比学习分支的损失函数,采用infoNCR loss:
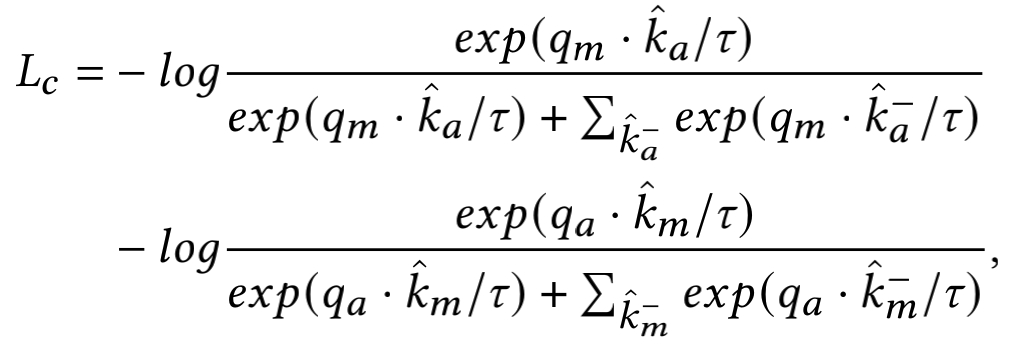
而 为掩码图像预测分支的损失函数,采用L2 loss:
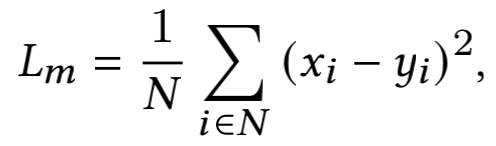
其中 分别为预测像素值和为目标像素值, 为被Mask掉像素的总数量。
实验结果
文章首先展示了自监督学习中掩码图像的重建效果,可以看到即使原图上的文字被遮挡或者已经模糊,重建结果中的文字仍然清晰,这意味着模型学习到了通用的特征表征。

接下来,文章做了Feature representation evaluation(冻结Encoder,只训练文本识别Decoder) 和 Self-supervised evaluation的实验。在特征表征质量的评估中,得益于区分性学习和生成式学习的优势互补,DiG-ViT-Small在所有数据集上均取得最好的表现,并分别超过单单使用其中一个分支的Gen-ViT-Small和Dis-ViT-Small 11.8%和4.1%。在Self-supervised的评估中,当使用100%的标注数据微调时,自监督学习版本Gen-ViT-Small、Dis-ViT-Small、DiG-ViT-Small的准确率指标分别比从头训练的监督学习版本Scratch-ViT-Small指标超出6.8%,6.5%和7.3%。而随着有标注数据量的减少,DiG-ViT-Small的优势更加明显。实验结果表明,无论是对比学习还是掩码图像建模的自监督方法都可以提升文字识别的准确率,而将两者结合起来的DiG可以获得更好的性能。
 Feature representation evaluation
Feature representation evaluation
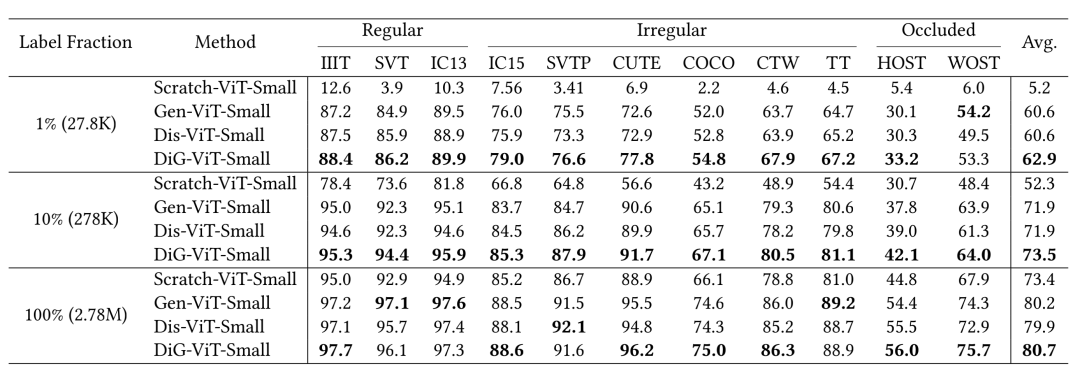
Self-supervised evaluation
然后,相较于之前的自监督文字识别方法,包括前面已经列出的SeqCLR,还有腾讯发表的另一个方法PerSec,DiG在场景文字和手写数据集上都有稳定的准确率提升。文章还与已发表的众多先进的文本识别方法进行了比较,在用于训练的标注数据集相同,且模型参数量大致相当的条件下,DiG在11个场景文字数据集上取得了整体5.3%的准确率指标提升,大幅提升了SOTA。
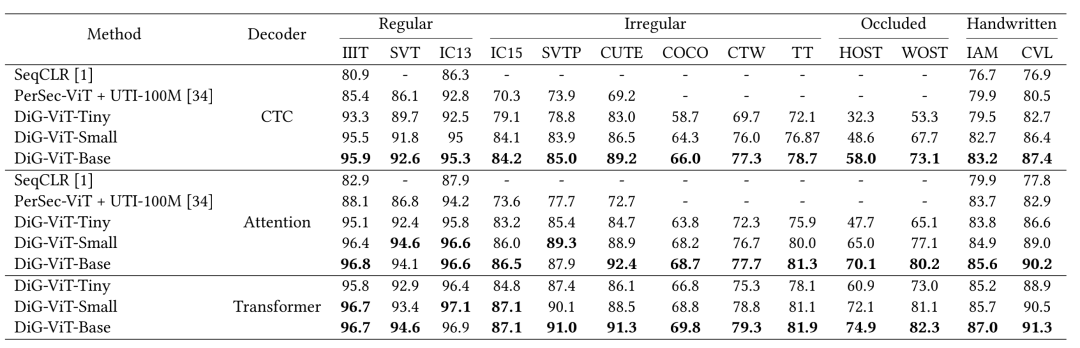
DiG同已有文字识别自监督学习方法的比较

DiG在场景文字识别数据集上同已发表方法的比较
最后,文章也通过实验验证了DiG自监督学习得到的特征表征还可以直接被应用到文字图像相关的其他下游任务,例如文字图像分割和文字图像超分辨率中,并且取得明显的效果提升。
五、结语
继在通用图像识别领域的火爆之后,自监督学习在文字识别领域也已经显现出其潜力,本文就回顾了在这一领域近期涌现出的几篇代表文章。在实践中不断挖掘自监督学习这一范式带来的价值,也是来也技术团队未来会和大家一起探索的事情。
参考文献
1.MoCo (FaceBook): https://arxiv.org/pdf/1911.05722.pdf
2.SimCLR (Google):https://arxiv.org/pdf/2002.05709.pdf
3.MoCo v2 (FaceBook): https://arxiv.org/pdf/2003.04297.pdf
4.BYOL(Google) https://arxiv.org/pdf/2006.07733.pdf
5.SimCLR v2 (Google):https://arxiv.org/pdf/2006.10029.pdf
6.MoCo v3 (FaceBook): https://arxiv.org/pdf/2104.02057.pdf
7.MAE (FaceBook): https://arxiv.org/pdf/2111.06377.pdf
8.SimMM (MSRA): https://arxiv.org/pdf/2111.09886.pdf
11.PP-OCRv3 (百度) https://arxiv.org/pdf/2206.03001.pdf
12.SeqCLR(以色列大学&Amazon): https://arxiv.org/pdf/2012.10873.pdf
13.SimAN (华南理工大学): https://arxiv.org/pdf/2203.10492.pdf
14.DiG (华中科技大学&华为): https://arxiv.org/pdf/2207.00193.pdf
本文作者:hailong



