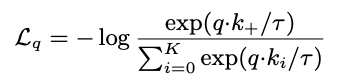机器学习算法目前可以分为监督学习、无监督学习、自监督学习和强化学习。
其中:
- 监督学习模型的性能在一定程度上依赖于有标记训练数据的数量,但是人工手动标注数据既耗时又昂贵;
- 自监督学习不需要有标记的训练数据,并可以通过微调使几乎所有下游任务受益,所以近年来自监督学习的研究越来越火热。
自监督学习是指不依赖于人工标注的标签,通过挖掘训练数据本身内在特征来进行网络训练的一种机器学习方法。其目标是:学习一种通用的特征表达,这种特征表达可以方便的迁移到下游任务。自监督学习的实现方法可以分为两大类:生成式(预测式)方法和对比式方法。- 生成式(预测式)方法通过模型对输入进行编码再解码,以期望获取和输入完成相同的输出为目标。例如NLP领域中Bert【1】的掩码语言模型(MLM,Masked Language Modeling),随机抹除输入中的部分tokens,通过自监督训练来预测出这些tokens;CV领域何恺明最新提出的MAE【2】(Masked AutoEncoders),将样本图像划分为多个patch,随机抹除大部分的patch,通过非对称式的Encoder和Decoder在像素级完成被抹除图像的重建。
- 对比式方法的基本指导思想是:通过自动构造正样本对和负样本对,学习一种特征表达,通过这个特征表达,使得正样本对在投影空间中比较接近,而负样本对在投影空间中尽量远离。
对比自监督学习的基本原则为:对于给定数据 ,其目标是学习一种编码器(特征表达) ,使得同类样本编码后的特征距离较近,异类样本编码后的特征距离较远。可以用如下公式表示:

为了优化上述编码器,我们可以构建一个基于softmax的交叉熵作为损失函数,公式如下:
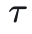 为超参数。在对比式监督学习中也叫做 infoNCE loss(Info noise-contrastive estimation),样本中只有一个正例和 K 个负例,本质上可以看成 K+1 类的分类问题。
为超参数。在对比式监督学习中也叫做 infoNCE loss(Info noise-contrastive estimation),样本中只有一个正例和 K 个负例,本质上可以看成 K+1 类的分类问题。
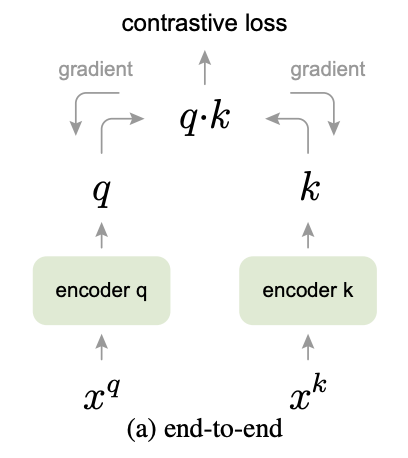
介绍完对比式自监督学习的基本原则和工作方式后,简单介绍下MoCo系列自监督学习算法。MoCo由何恺明团队提出,通过MoCo学习得到的编码器在图像分类、目标检测、实例分割等下游任务上都达到甚至超过了有监督学习模型的水平。由对比学习的基本思想可知,对比学习的关键是构建正负样本对,MoCo V1的正样本对为从同一张图像样本上随机裁切出的两张图片,负样本为从不同图像样本上随机裁切出的两张图片,MoCo关注的重点是样本对的数量以及编码器参数的更新策略。先介绍下最朴素的end-to-end模型结构,模型结构如下图所示: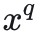 和
和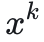 为样本, encoder q、encoder k 为编码器, q和 k 为样本经过编码器之后得到的特征( query vector 和 key vector ) 。
为样本, encoder q、encoder k 为编码器, q和 k 为样本经过编码器之后得到的特征( query vector 和 key vector ) 。
key vector 会被保存在一个字典(dictionary)中,假设字典的大小为 L,一个 query vector 只会和字典中的一个 key vector 构成正样本对,和 L-1 个 key vector 构成负样本对。
论文假设好的特征表达可以从一个巨大的字典中获取,并且字典的 key vector 应该保持连续。
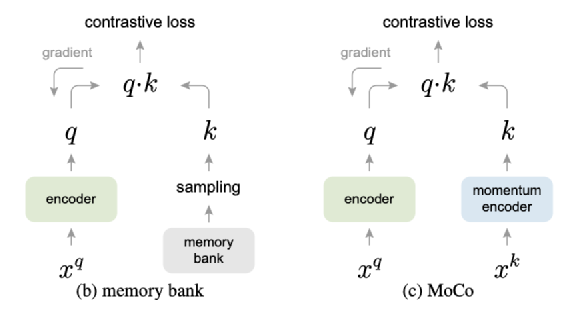
显然在 end-to-end 模型中,字典的大小取决于由显存控制的 batch size 大小,而且编码器 encoder q 和 encoder k 的参数同步更新,这与论文假设不符,为了解决这两个问题,作者介绍了 memory bank 模型和 MoCo 模型,模型结构图如下:
在左边的 memory bank 模型中,字典大小不再受限于 batch size ,即负样本不仅限于在当前批次的训练样本中选择,而是在一个 bank(可以是一个大型数组)中随机采样,但是编码器 encoder k 的参数还是会在每个 batch 之后更新,如果每一次更新重新编码一次所有样本,计算量较大,如果只是更新下一次采样的 k 个样本,bank中的的部分特征表示和参数更新不同步。右边的 MoCo 模型完美地解决了这两个问题。在 MoCo 模型中 memory bank 被一个队列取代(Dictionary as a queue),队列中的样本滚动更新,当前批次的样本会进队列,而最早进入队列的样本会被挤出队列,在更新参数时采取动量的方式,公式如下: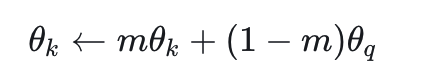
m 为动量参数
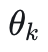 为 key 编码器的参数
为 key 编码器的参数
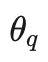 为 query 编码器的参数。
为 query 编码器的参数。
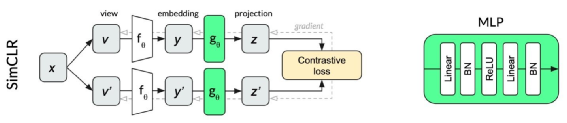
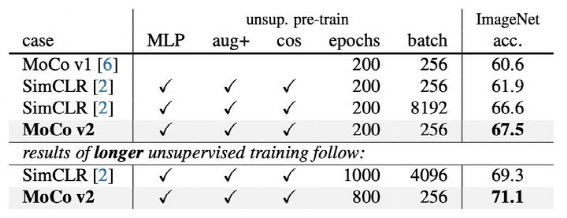
对比式自监督学习的另一个代表模型是由 Chen Ting 提出的 SimCLR【5】(A Simple Framework for Contrastive Learning of Visual Representations)。SimCLR在ImageNet的分类任务上表现优于 MoCo V1。与 MoCo V1 相比,SimCLR 更加关注正负样本的构建方式和非线性层(MLP)对自监督学习的影响。其结构类似于上文中的end-to-end模型,不同的是SimCLR在编码器后接入了一个非线性层,结构示意图如下:SimCLR研究了不同的数据增强方式并取得有效增益,在SimCLR之后,MoCo团队对MoCo V1做了如下改动:增加使用高斯模糊来进行增强,并使用大的 batch size 。
在编码器之后增加MLP层,实际使用时丢掉MLP只使用编码器。
这就是MoCo V2。V2以更小的 batch size 和训练轮数,先在 ImageNet 不使用标签做自监督训练,然后再利用标签 finetune,最终 top-1 精度超过了SimCLR:我们知道 Transformer 是一种基于自注意力体系的模型,其在 NLP 领域的大放异彩,Google 遵循 Transformer 架构提出了适用于 CV 领域的 Vision Transformer(ViT)模型。MoCo V3研究的就是采用自监督框架进行ViT模型的训练。MoCo V3主要研究了batch size,learning rate 以及 optimizer 对 ViT 模型训练的影响。下图为MoCo V3在4个数据集上与随机初始化和有监督模型的对比效果,可以发现MoCo V3对ViT模型有一定的提升。MoCo V3中并没有采用之前版本的 memory queue,而是简单粗暴的使用较大的batch size来保证负样本的多样性,所以训练时对硬件要求较高。本次在两个任务中使用了自监督预训练模型,一个是文档图像的3分类任务,另一个是文档图像中文本行检测任务。在我们的实际业务中需要将票据、报关单、普通文档这三种类型的文档区分开,为此我们构建了一个3分类模型,分别采用 MoCo 自监督训练得到的 ResNet18 网络和在 ImageNet 上预训练得到的 ResNet18 网络作为骨干网络,并对比了两种不同骨干网络下模型的效果。1.采用SGD+0.9 momentum优化器;初始学习率0.03,MultiStepLR更新策略,milestones设置为【160,280,640】;batch size 设置为512;MoCo需要的队列大小设置为65536;在140万文档图像数据集上训练了388epoch我们使用分类准确率来衡量模型的效果。使用自监督骨干网络的模型比使用在ImageNet上训练骨干网络的模型,平均分类准确率高3.7%。文本行检测是OCR的重要组成部分。同样,我们对比了采用MoCo自监督训练得到的ResNet18网络和在ImageNet上预训练得到的ResNet18网络对文本行检测模型的影响。1. 采用SGD+0.9 momentum优化器;初始学习率0.03,MultiStepLR更新策略,milestones设置为【160,280,640】;batch size 设置为512;MoCo需要的队列大小设置为65536;分别在15万和45万文档图像数据集上训练了1000epoch。2.在ICDAR15数据集上,使用ADW优化器,学习率为1e-4 ,batch size为40,训练800轮。我们计算了基于IOU的准确率和召回率,并使用F1来衡量模型的效果。对比结果如下表:其中:当文本行检测模型采用45万样本预训练的ResNet18网络作为骨干网络(ResNet18(MoCo45w))时,F1达到了80.86%,当采用有监督训练的ResNet18网络(ResNet18(ImageNet))作为骨干网络时,模型的F1为81.10%,前者仅比后者差0.24%。【1】Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In NAACL, 2019.【2】Kaiming He,Xinlei Chen, Saining Xie, Yanghao Li,Piotr Dollar, and Ross Girshick. Masked autoencoders are scalable vision learners. arXiv preprint arXiv:2111.06377, 2021.【3】He, Kaiming, et al. "Momentum contrast for unsupervised visual representation learning." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.【4】Chen, Xinlei, et al. "Improved baselines with momentum contrastive learning." arXiv preprint arXiv:2003.04297 (2020).【5】Chen, Ting, et al. "A simple framework for contrastive learning of visual representations." International conference on machine learning. PMLR, 2020.【6】Chen, Xinlei, Saining Xie, and Kaiming He. "An empirical study of training self-supervised visual transformers." arXiv preprint arXiv:2104.02057 (2021).