

近日,DeepSeek-OCR模型在业内引发了广泛关注。DeepSeek-OCR采用了全新的光学上下文压缩(Optical Contexts Compression)技术,模型在处理文档时的Token效率实现了质的飞跃。同样处理一页文档,传统视觉语言模型(VLM)平均需要6000多个Token,而DeepSeek-OCR只需要100-800个Token,Token消耗减少90%以上,同时达到和传统模型接近的准确率。这种效率优势在大规模文档处理场景中转化为实实在在的成本和时间节省。
DeepSeek-OCR为高性能文档解析任务提供了一条全新的技术路径,让企业能够用更少的计算资源、更快的处理速度完成海量文档处理工作。单张GPU每天可以处理超过20万页文档,这对企业历史档案数字化、金融报表批量处理、法律文书检索、学术论文解析等场景来说,意味着单个文档的处理时间从分钟级变成秒级,效率大幅提升,同时成本大幅降低。
来也科技智能体文档处理平台(Laiye Agentic Document Processing,简称来也ADP)已集成DeepSeek-OCR模型,这一集成为客户提供了更多样化的文档解析模型选择,使得不同场景、不同需求的文档处理任务都能找到最适合的技术方案。下图展示了来也ADP在对合同、票据、手写体文档、多语言文档的解析效果。

准确还原文档中的章节、段落、表格、印章等
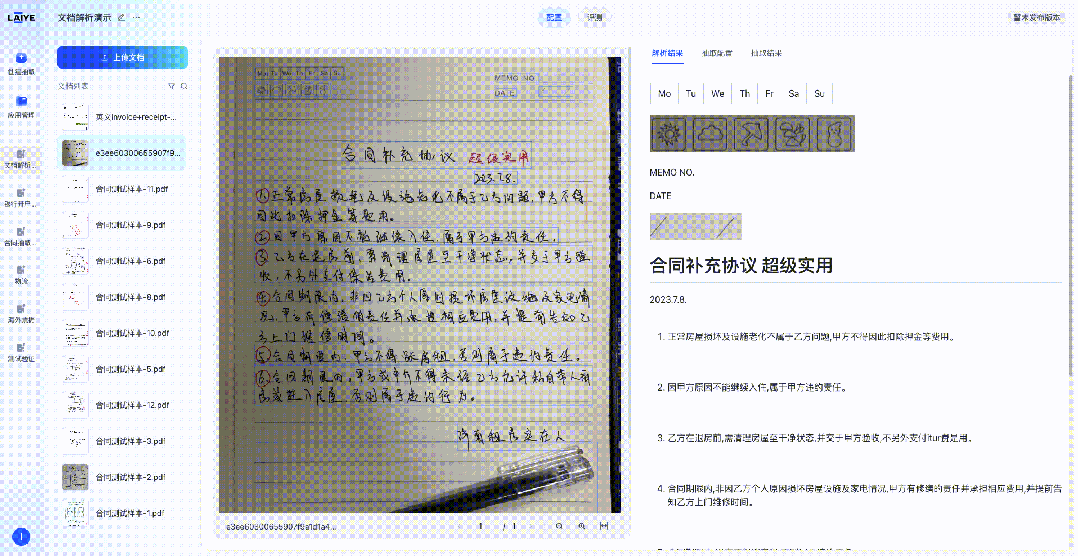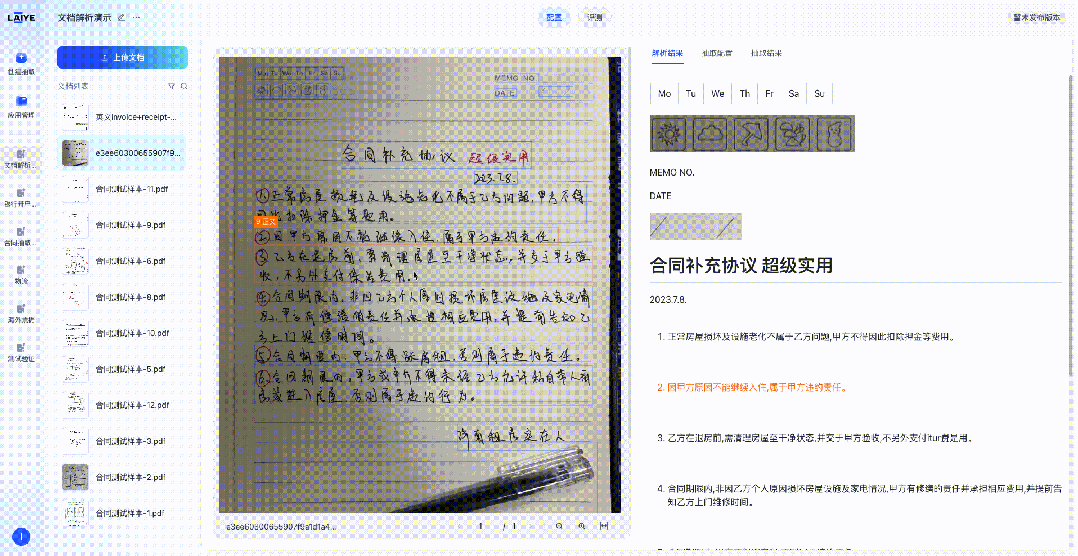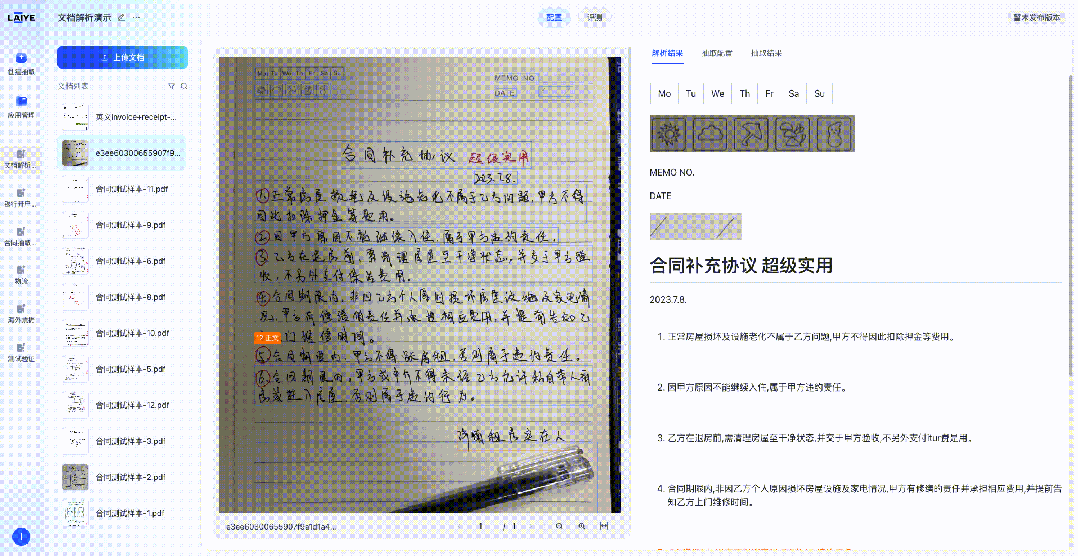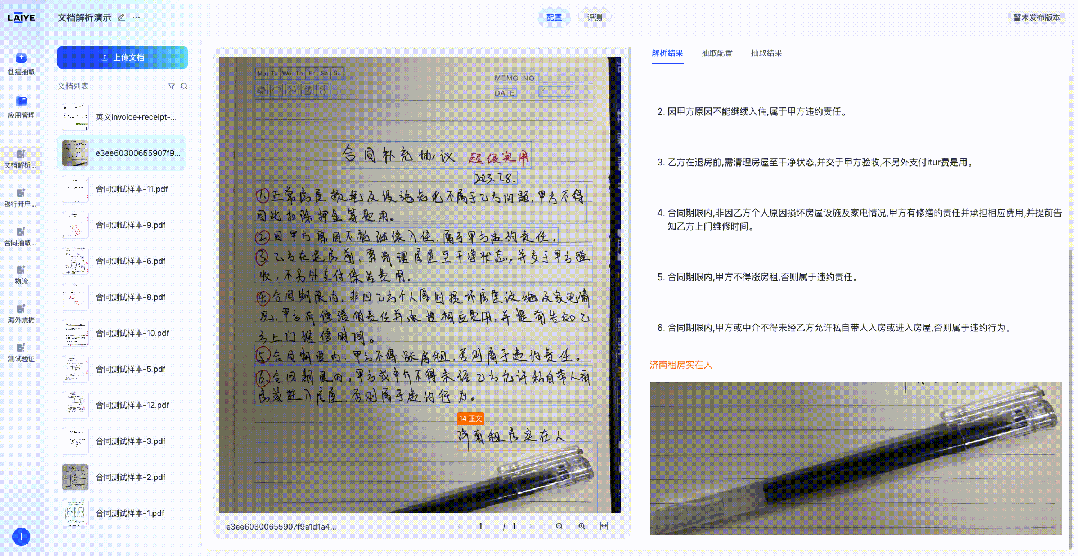
精准识别手写体
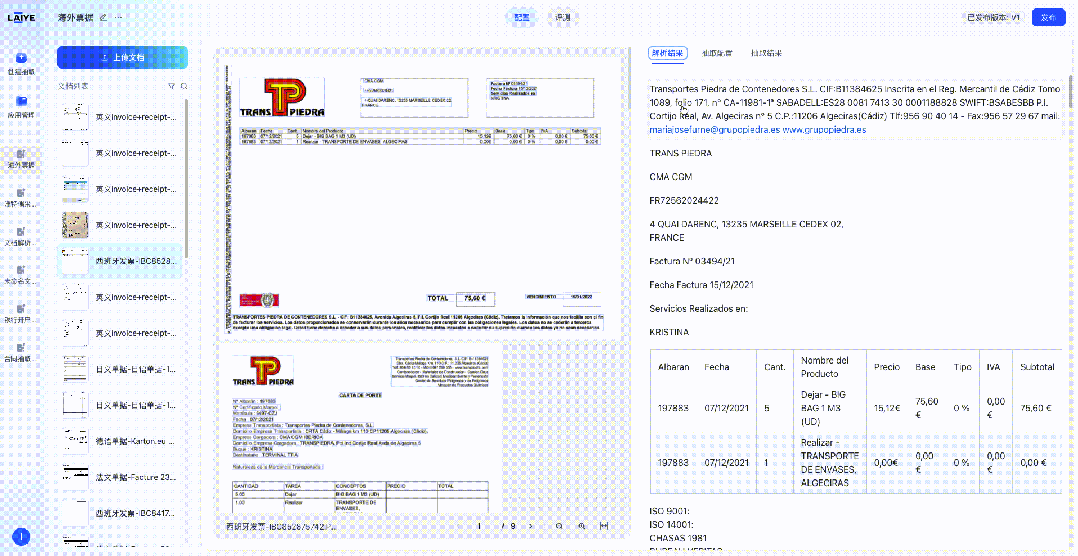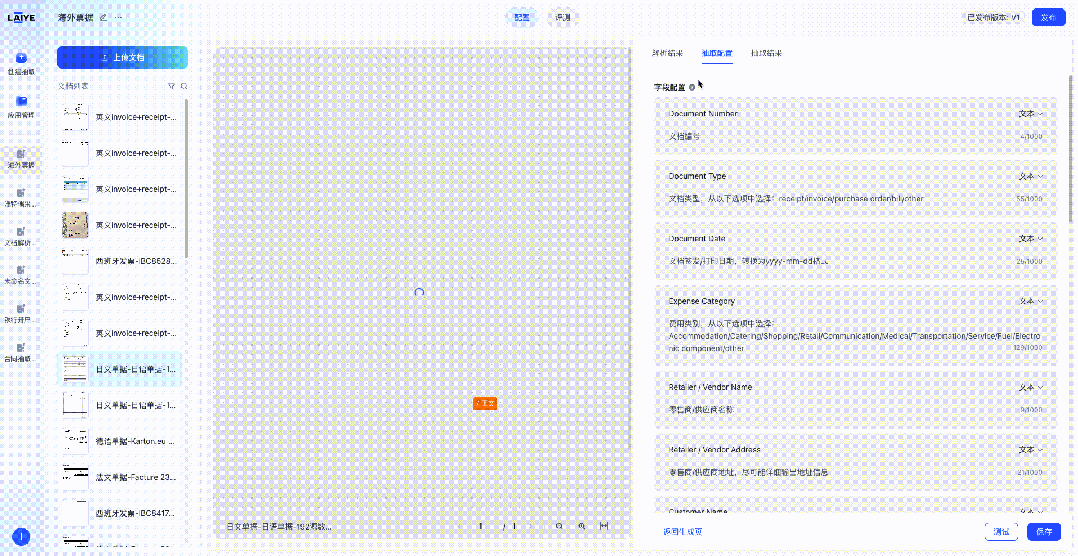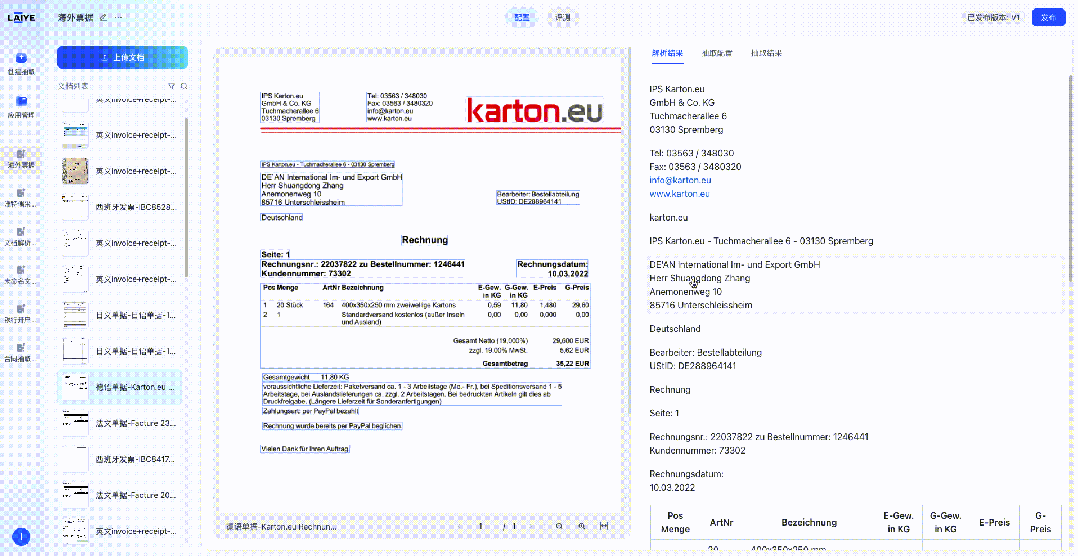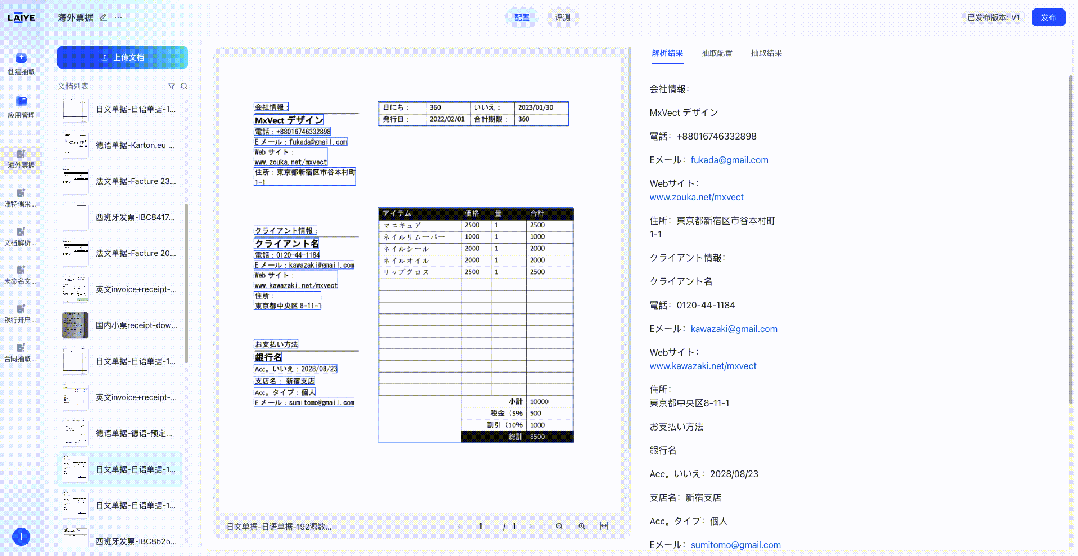
支持超过100种语言
目前,来也ADP已经集成了DeepSeek-OCR在内的多种模型,包括主流的视觉语言模型、大语言模型和经过微调的文档处理专用模型。客户可以根据具体业务需求,选择最合适的模型组合:对于追求极致性能的场景,可以选择DeepSeek-OCR实现秒级处理;对于需要极高准确率的场景,可以选择精度更高的模型;对于复杂文档,还可以组合多个模型协同处理。
这种多模型集成的策略,正是来也ADP的核心优势所在。
以企业常见的合同审核流程为例,就能看到多模型协同的必要性:一份完整的采购合同可能包含数十页内容——既有标准格式的文本条款,也有复杂的价格表格,还可能附带技术规格说明书、资质证明等各种附件。处理这样的复杂文档,需要多种模型各司其职:
文档分类模型:识别这是采购合同还是销售合同,主合同还是补充协议
高速文档解析模型(如DeepSeek-OCR):快速提取标准文本段落中的关键信息
视觉语言模型:理解复杂的价格表格结构、识别表格中的数字和单位
大语言模型:进行语义理解和业务推理,比如判断合同条款是否存在法律风险、价格是否符合历史采购数据、付款条件是否合理等
更重要的是,真实的合同审核工作流不仅需要模型,还需要各种工具的协同:查询ERP系统对比历史采购价格,调用供应商管理系统核实资质,使用计算工具核算总价,调用法务知识库检查条款合规性,发送审批通知给相关人员等。传统方式下,这些模型和工具的串联依靠人工编写规则或代码实现,不仅开发成本高,而且缺乏灵活性,业务流程一旦变化就需要重新编码。
来也ADP的核心优势在于智能体编排能力——能够智能编排多个模型和工具协同工作。在复杂文档处理场景中,ADP智能体能够理解任务目标,自主规划需要调用哪些模型和工具、按什么顺序调用、如何处理中间结果,并在遇到异常时自适应调整,最终输出业务所需的结果。
DeepSeek-OCR带来的不仅是技术指标的提升,更重要的是展示了一种新的可能性——通过光学压缩实现长上下文的高效处理。这对于智能体系统尤其重要:智能体在完成复杂任务时,上下文的长度往往会超过模型可处理的最大Token数,而利用这类技术可以对上下文进行几乎无损的压缩,大幅降低Token消耗。
来也ADP通过集成DeepSeek-OCR以及更多主流模型,并通过智能体编排技术实现多模型和多工具协同,为企业文档处理提供了一个完整的解决方案。这种"基础模型+智能体编排"的架构,使得ADP能够快速适应新模型的出现,持续为客户提供最优的技术能力和解决方案。
在即将发布的来也ADP白皮书《文档处理进入智能体时代》中,我们将深入解析智能体文档处理的技术架构与落地路径。请持续关注来也科技官网、公众号后续发布的白皮书全文,您将看到更完整的技术细节、更丰富的行业案例,以及更清晰的实施路线。期待与您一起,迈出企业智能体落地的第一步。







