

“ 小来说:安全无小事”
只要是有利可图(或者是单纯闲的发慌),总会有人试图攻击你的系统。
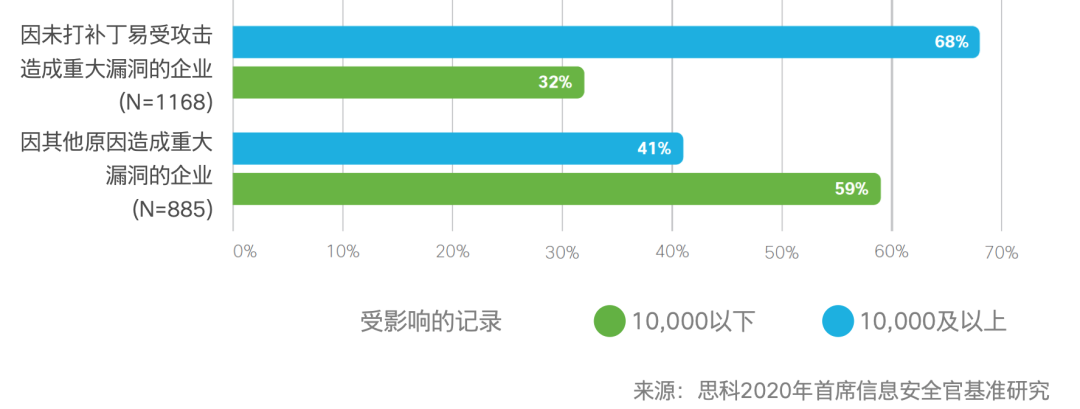
给大家展示一组数据,2020年(还没过完呢),46%的企业因未修补漏洞而受到了攻击:
对于绝大多数公司而言,保护好敏感数据和算法是底线。对于来也科技这样 RPA+AI 的公司而言,除了基础保护,我们还要保护自己的机器人不被别人盗用。
以“吾来对话机器人平台”(下文简称“吾来”)产品举例,作为一款对话机器人产品,我们该要如何保证敏感信息的机密性、完整性和可用性?又要如何保证自己的机器人不被别人包一层壳子,伪装成另一个产品进行利用?
来也科技从今年 Q3 开始全面启动安全方向的工作。在开始之前,我们首先梳理了已知的安全问题,进行了分析、归类。接下来,我们从面向应用和面向基础架构两个方向来阐述来也科技是如何开展安全工作的。
01.
应用
我们的 SLB 只对外开放 443 端口,这是应用提供服务的 https 端口。所以,保护好应用,相当于是堵住了入侵的入口。
曾经的吾来,从产品设计、开发测试到上线运维都毫无安全意识。这使得吾来在渗透测试面前不堪一击:弱密码,水平/垂直越权,SQL注入等一系列 OWASP Top10 的漏洞层出不穷。
整改弱密码:
首次渗透测试发现,吾来平台存在部分用户使用弱密码的情况,这使得攻击者很容易猜到密码,然后登陆用户账号。吾来平台上保存着大量的客户、机器人、对话等信息,这些信息敏感且重要,是不能被泄露或破坏的。
发现问题后,我们积极整改。首先是弱密码:除了在创建用户,修改密码时新增对密码长度和复杂度限制外,我们还对已存在的弱密码做了处理:
为了保证用户密码的安全性,使密码不被有权限看到数据的管理员所识别、利用。在来也科技后台,所有存储的密码都是经过加密的,且每个用户拥有自己单独的“盐”。
我们将“注册时间”或“最后一次修改密码时间”早于“吾来强制要求密码复杂性时间”的用户定义为“弱密码可能用户”。
首先生成一个明文弱密码库,然后循环遍历弱密码可能用户列表,用该用户的“盐”去逐一加密明文弱密码,并和存储的密码密文进行匹配。
如成功匹配,那么客服同学(以及部分程序员同学)就会打电话通知客户:为了保障您的账户安全,请大驾登录吾来平台,进行密码修改。
我们就是这样确保吾来平台上的密码都满足安全上的复杂性要求的。
密码复杂性要求:
长度必须8位及以上
必须同时拥有大小写字母、数字、特殊字符
密码重置时需要输入旧密码进行校验
即便是再复杂的密码,只要不停的尝试暴力破解,也是不够安全的。针对这种形式的攻击,吾来产品的防暴力破解方案如下:
人机验证:购买云上的专业产品,在saas版本上使用
验证码:部分私有部署的客户在局域网使用吾来,无法接入人机验证。所以我们同时开发了验证码版本:在用户名或密码输错3次后,需输入验证码辅助验证
账户锁定:验证次数过多,账户锁定
限流:使用漏桶和令牌桶算法进行敏感接口限流(包括但不限于登录接口)
整改SQL注入:
什么是SQL注入?
SQL注入漏洞主要形成的原因是在数据交互中,前端的数据传入到后台处理时,没有做严格的判断,导致其传入的“数据”拼接到SQL语句中后,被当作SQL语句的一部分执行。从而导致数据库受损(被拖库、被删除、甚至整个服务器权限沦陷)。
对于SQL注入的整改,我们从两方面入手:
消灭语句上注入的可能性
限制SQL执行用户的权限
对于“消灭语句上注入的可能性”,我们采用了简单粗暴却非常有效的方式:所有应用使用ORM与DB进行交互。
为什么 ORM 能够防止 SQL 注入呢?这是因为大多数 ORM 使用了prepare 模式来执行 SQL 。以 golang 的 mysql driver 作为示例:
func ctxDriverPrepare(ctx context.Context, ci driver.Conn, query string) (driver.Stmt, error) {if ciCtx, is := ci.(driver.ConnPrepareContext); is {return ciCtx.PrepareContext(ctx, query)}si, err := ci.Prepare(query)if err == nil {select {default:case <-ctx.Done():si.Close()return nil, ctx.Err()}}return si, err}
而 prepare 是MySQL官方推荐的防止SQL注入方法:
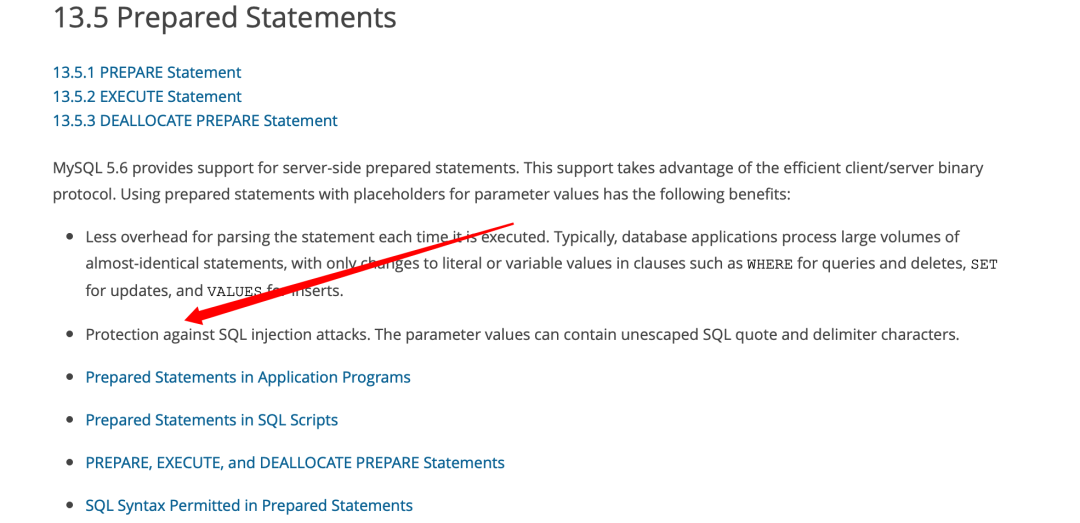
为了方便大家理解和记忆,我们简单介绍下为什么 prepare 可以防止 SQL 注入。以一条简单的查询语句为例:
select username, ismale from userinfo where age > 20 and level > 5 and 1 = 1;
prepare 会使得语句首先被解析成一颗“语法树”:所有条件,字段,关系已经被填充,值只可以被填充在固定的位置上。
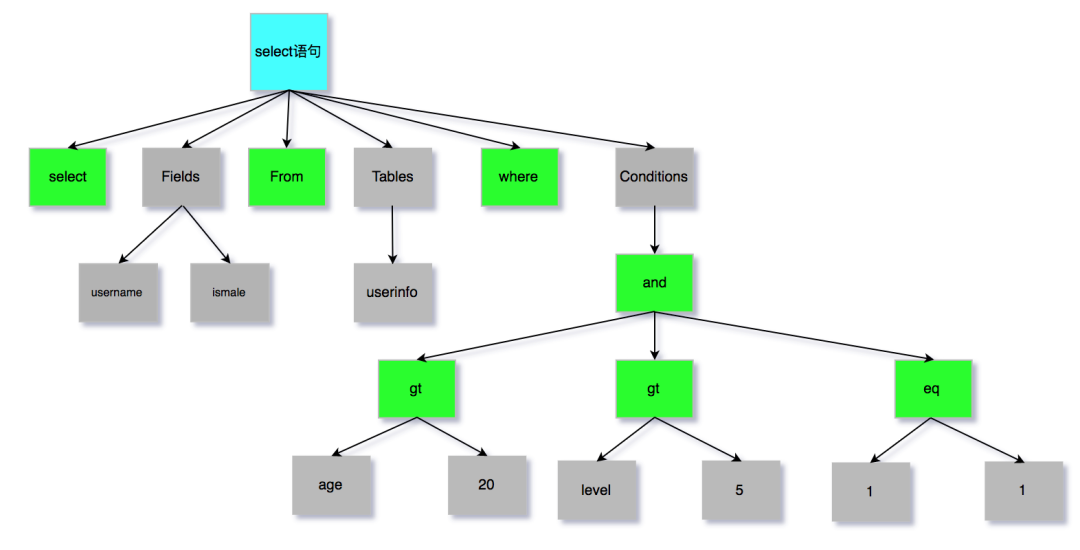
所以,无论用户输入多么具有“攻击性”的内容,永远会被当成一个字符串类型(或是整型,时间等)的值处理,绝不会被当做SQL语句的一部分执行。
除了硬性规定应用使用ORM外,我们还对应用使用的数据库用户进行账户和权限分离。
在来也科技内部,客观存在多个应用共用一个实例,甚至是一个DB的情况。针对这种情况,我们使用“配置模板 + 规则渲染”的方式为应用来自动生成数据库用户,设置密码,分配权限。流程如下:
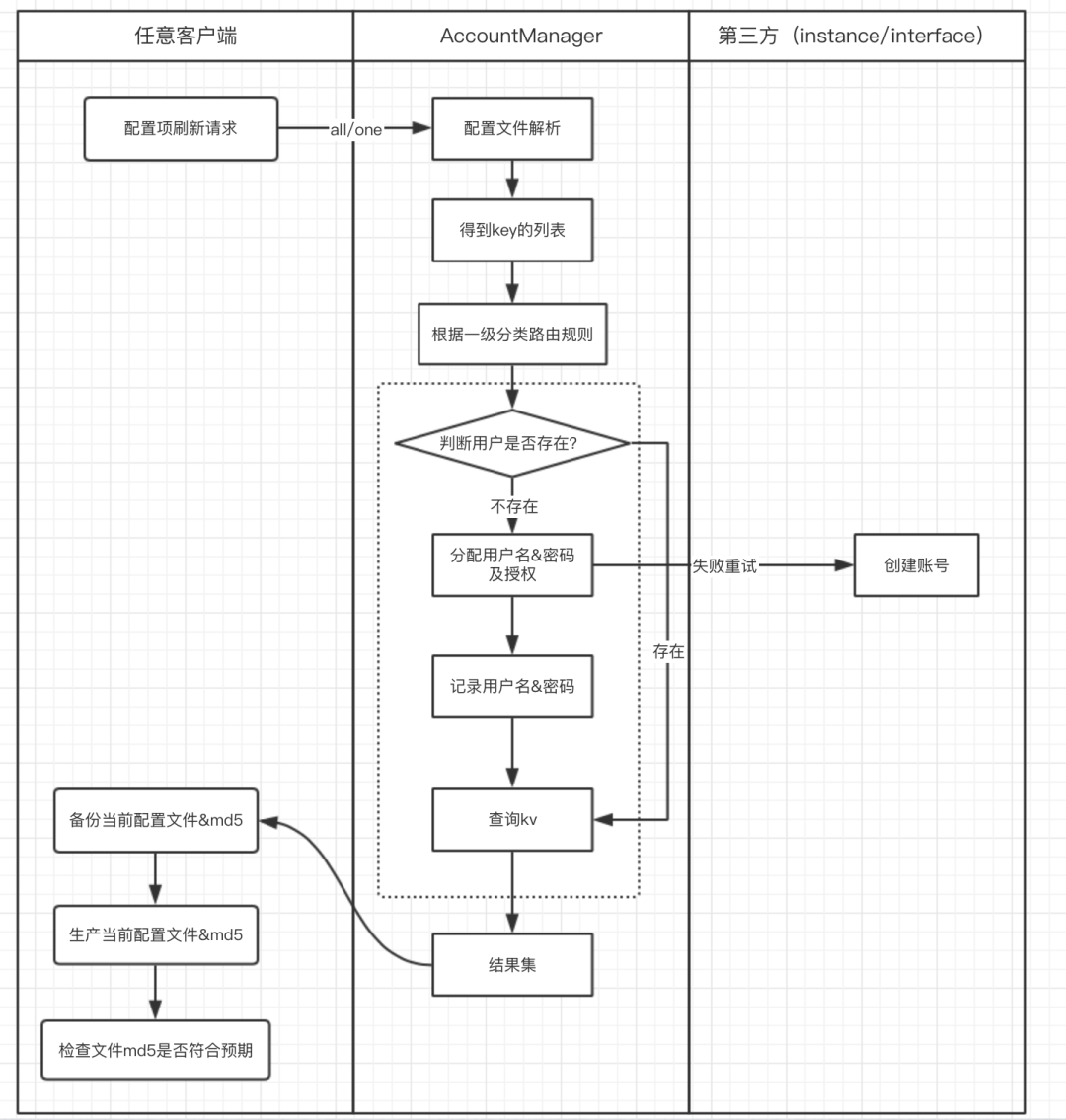
这样做的好处是:
即便是RD也不知道自己应用的线上用户名、密码,有效防止内部成员对DB安全造成威胁
每个应用拥有自己的用户和密码
一旦发现危险操作,可以根据数据库日志快速定位到是哪个用户发起的,进而定位到应用,立即联系项目负责人介入处理
我们可以针对这个用户,进行限流,禁用等操作,而不会影响到其他应用
我们可以定期更换数据库的账号密码,以保证数据库账户安全,而不必要求应用做任何修改(DBA自己发起替换后,渲染模板并串行重启应用即可)
限制单个用户的连接数和操作权限
不同的应用需要不同的权限,遵循“权限最小化”原则
避免恶意操作(或者是内部误操作)打爆连接数,影响DB实例的可用性
整改XSS
什么是 XSS?
XSS(Cross-Site Scripting)指跨站脚本攻击。攻击者通过在目标网站上注入恶意脚本,使之在用户的浏览器上运行。利用这些恶意脚本,攻击者可获取用户的敏感信息,如:SessionID ,进而危害数据安全。
XSS 分为如下三类:
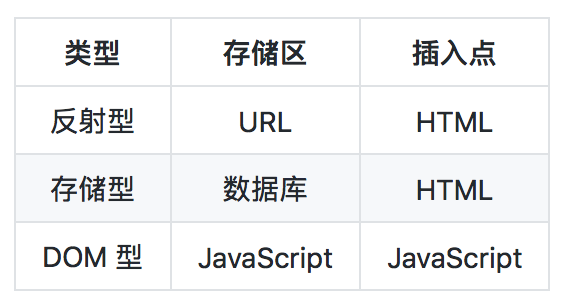
反射型 XSS 指:恶意脚本存储在 URL 上,当用户访问 URL 时,参数中的恶意脚本被渲染为 HTML 导致的攻击。这种攻击多存在于网站搜索、跳转等场景。
存储型 XSS 指:恶意脚本被存储至数据库,当数据取出时被渲染至 HTML 导致的攻击。但需要注意的是:如果有类似开放平台等公开接口,也需防范存储型 XSS。虽然接口本身只返回数据不会直接被 XSS 攻击,但接口调用方(多为客户)若没有防范 XSS,则有可能遭到攻击。
DOM 型 XSS 指:带有恶意脚本的 JS 或文本在页面中被执行导致的攻击。常见于对话、回复等需要把用户输入渲染至页面的场景。
传统意义上一般认为反射性和存储型的 XSS 属于服务端漏洞(页面由服务端渲染),DOM 型 XSS 属于客户端漏洞。在前端后分离的场景下,一个 XSS 可能会是两种类型的结合。举个例子:
在知识点的答案中攻击者加入了恶意脚本,保存。此时页面并未遭受攻击,但恶意脚本被存至数据库;当与机器人对话的用户询问到此知识点,页面中渲染答案时,恶意脚本会发起攻击。
在这个场景下,既存在存储型 XSS,又存在 DOM 型 XSS。
常见的 XSS 防范方式有:
内容过滤
CSP 策略
内容过滤,即:过滤数据中的恶意脚本。对于恶意脚本,我们可以通过转义的方式使其失去作用。
内容过滤并不是指对所有保存到数据库、所有传递至页面的数据都进行过滤。XSS 发生的核心是恶意脚本被渲染为 HTML,普通的数据输入、展示并不会导致 XSS,因此内容过滤没有通用的准则,需要根据业务详细判断。对于会渲染在页面上的内容,则必须进行输入(避免存储型 XSS)和输入(避免 DOM 型 XSS)的过滤。
因为内容过滤没有通用的准则,可能会发生遗漏。“CSP 策略”可作为兜底方案实施。至少要在页面的head中增加如下标签:
禁止加载白名单外的脚本,防止攻击者引入 JS 文件
禁止内联脚本执行,防止隐藏在内容中的恶意脚本被执行
需要注意的是:
CSP 可以拦截恶意脚本的执行,但本质上 XSS 已经发生。因此 CSP 策略只可作为兜底,应尽量在源头避免
CSP 策略有可能会阻碍业务需求,需要根据业务场景细化配置
内容过滤和 CSP 策略都需要手动配置,难免发生遗漏。因此我们将内容过滤和 CSP 策略这两种防范方式集成到我们的 CI 流程中:
输出时的内容过滤,在我们的 React 项目中,会在使用 dangerouslySetInnerHTML 时进行。为了强制提醒开发者谨慎使用 dangerouslySetInnerHTML,我们把 dangerouslySetInnerHTML 设置在 ESLint 的规则中用于提醒。
对于所有前端项目,理论上都必须加入 CSP 策略进行兜底。我们会在前端项目构建时,检查入口页面中是否包含 CSP 策略的 meta 标签,若没有则会构建失败。
整改CSRF
什么是 CSRF?
CSRF(Cross-site request forgery)指跨站伪造请求:攻击者诱导受害者进入第三方网站,在第三方网站中,向被攻击网站发送跨站请求。利用受害者在被攻击网站已经获取的注册凭证,绕过后台的用户验证,达到冒充用户对被攻击的网站执行某项操作的目的。
CSRF 一般有两个特点特点:
跨域。同域的 CSRF 可看作是 XSS 攻击范围
无法读取但可以使用源站的认证信息
从 CSRF 的特点可以看到,如果网站禁止跨域,可以很大程度防范 CSRF 攻击。但有一个例外:POST 表单是可以跨域的。
虽然 POST 表单是单向发送请求(不接收服务端的返回),如果通过 POST 表单有对数据的变更操作,就会有 CSRF 的风险。因此,尽可能避免 POST 表单的请求,同时禁止 POST 表单变更数据的请求。
当前主流的开发模式中,POST 表单的场景可能很少了,大家通常使用 Ajax/Fetch 发送和接收请求。但上传文件依旧是需求通过 POST 表单进行的。上传文件虽然不直接变更数据,但上传至服务器的文件本身就是一种风险。关于文件上传的安全防范在后面详述。
对于跨域的请求,我们必须至少做以下 CSRF 防范措施:
服务端的同源检测
CSRF Token
关于 CSRF Token,很多文章描述的流程都是:
将 CSRF Token 输出到页面中
页面提交的请求携带这个 Token
服务器验证 Token 是否正确
这个流程是正确的,但前提是页面是由服务端渲染。在主流的前后端分离架构下是不适用的,因为页面是提前生成的,Token 无法在每次请求提交前输入到页面中。
在前后端分离的架构下,可行的方法是:
在服务端第一次请求(比如登录)的返回中,加入 Token
将 Token 保存在浏览器中(Meta 标签、WebStorage)
页面提交的请求携带这个 Token
服务器验证 Token 是否正确
这样的方案看似是有缺陷的,因为 Token 一旦保存在浏览器中就会长期不变,儿且有 XSS 风险。但只有这样才能做到以 Token 方式防范 CSRF 攻击,因为无论是 Meta 标签还是 WebStorage,跨域页面都是访问不到的。(引入了 XSS 风险?—— 没有引入就不防范 XSS 了吗  )
)
此外还有注入双重 Cookie 验证等需要特定场景支持的防范方法,一般的介绍中都会提到,这里不再赘述。
综上,我们以一个流程图来判断网站是否有 CSRF 风险:
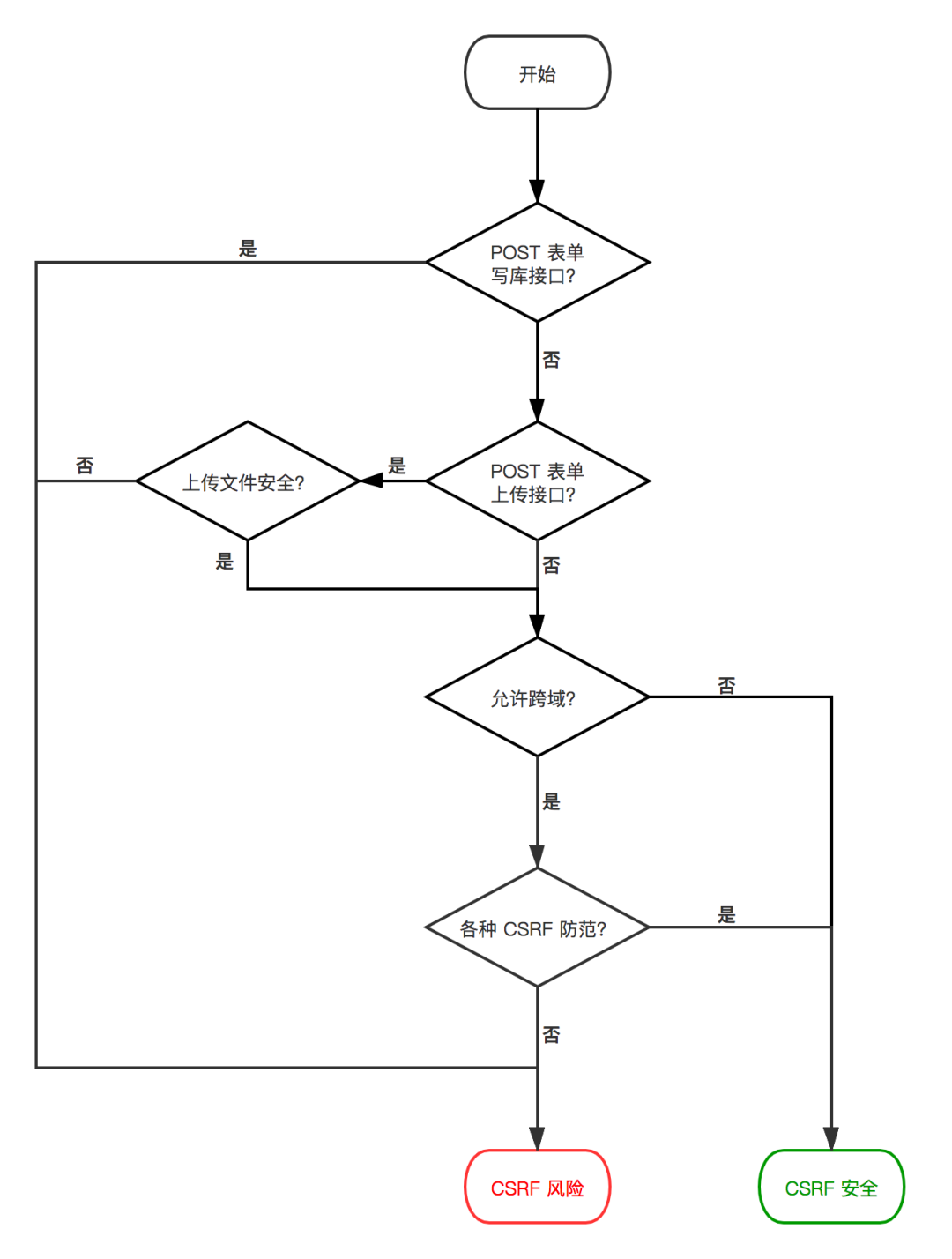
整改文件上传
上面提到,CSRF 攻击中,POST 表单是可以跨域的。而文件上传正式通过 POST 表单,因此文件上传需要严格防范。防范措施包括但不限于:
设置文件类型白名单
校验文件格式
文件重命名
文件名长度限制
文件大小限制
上传接口鉴权
将文件上传至独立服务器,如:对象存储,需要特别注意的是,若从浏览器直接上传,一般会使用服务端返回的签名。这个签名需要严格限制权限,例如:
只允许上传至配置的文件夹,其它遍历、删除等操作一概禁止
最小化签名有效时间,需要根据业务决定
整改垂直 & 水平越权
垂直权限又称功能权限。用户操作了没有权限的功能,就是垂直越权。垂直越权分一般发生于以下两种场景:
浏览器端存储的权限被篡改
在浏览器端控制页面权限
一般用户角色等信息是在登录后由服务端返回给浏览器,之后的请求中携带状态至服务端进行鉴权。如果这个状态不被篡改,就可以基本杜绝垂直越权。
浏览器中存储登录状态的常见方式有以下:
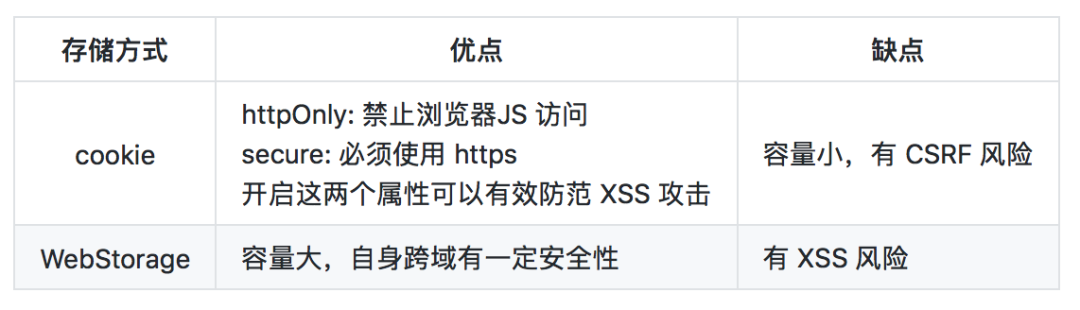
cookie 和 WebStorage 各有安全风险,考虑到 XSS 比 CSRF 更难防范,我们选择在 cookie 中存储登录状态。
在当前主流前后端分离的架构下,接口基本都会有鉴权,容易被忽视的是页面的鉴权。举个例子:用户 A 无权访问页面 B,但在浏览器中手动输入页面 B 的 URL,可以加载页面 B,此时页面 B 中的接口鉴权失败,导致用户 A 无法获得页面上的数据,或者跳转至登录页。但页面 B 的框架已经展示出来,依旧使无权限的信息被暴露了。
解决这个问题有两个方案:
在前端定义全部页面路由,页面跳转前判断权限,如果没有权限直接跳转至登录页
通过服务端获取的页面列表动态生成页面路由,访问没有权限的页面路由会直接跳转至 404
这两个方案看似都可以解决问题,但方案 1 如果发生了上面提到的浏览器端存储的权限被篡改,依然无能为力。因此最稳妥的方式是方案 2,权限交给服务端控制。
水平权限又称数据权限。区别于垂直权限,用户有操作数据的功能权限的,但若操作的数据不在自身权限内,就造成了水平越权。
举个例子:用户 A 和用户 B 分别是两个公司的员工,分别创建了 AA 和 BB 知识点。若用户 A 编辑知识点 AA 时,知识点 ID 被篡改为 BB,就造成了水平越权。
针对水平越权,来也科技内部做了两个层面的防范:
增加业务维度的全局 Hash
使用 GraphQL 自定义标量,将所有可枚举的 ID,做浏览器端 String
吾来系统中,对话机器人是最核心的业务,我们给每个机器人生成一个唯一的 Hash。机器人相关的全部业务接口请求中都必须携带这个 Hash,请求的中间件会判断当前登录的用户与这个 Hash 对应机器人的权限关系,如果 Hash 不存在或用户无权操作当前 Hash 对应的机器人,则抛出异常。
全局 Hash 可以防止大业务间的水平越权,但对于业务内部更细粒度的越权则无能为力。例如:用户 A 编辑知识点时,同时修改知识点的问题和答案。这个请求拥有正确的 Hash,但攻击者把答案 ID 篡改为其它知识点下答案的 ID,就可以把用户 A 本无权操作的知识点答案修改。
可以看出,因为答案 ID 一般是 Int 型(如果使用关系型数据库自增主键),很容易被枚举,才让攻击者有修改 ID 的机会。使用 ID 做更新的操作本身没有问题,我们需要把传递给浏览器的 ID 转换加密字符串,使其不可枚举。
借助 GraphQL 的自定义标量,我们可以实现 ID 在服务端和浏览器端的类型转换:
const { GraphQLScalarType, Kind } = require('graphql')const IDScalar = new GraphQLScalarType({name: 'ID Scalar',description = 'ID 类型转换: 服务端 number/*** server --> client* @param value*/serialize(value: number): string {return number2string(value)}/*** client --> server 参数从 query 传递* @param value*/parseValue(value: string): number {return string2number(value)}/*** client --> server 参数从 GraphQL 行内传递* @param ast*/parseLiteral(ast: ValueNode): number {if (ast.kind === Kind.STRING) {return string2number(ast.value)}return 0}})
代码安全规范审核
从Q4开始,我们增加了代码的安全规范审核,在push代码的时候,自动执行。审核内容包括但不限于:
敏感字符,如:线上的密码,key等
所有项目都必须使用规范化的模板配置,如“{{MongoDBApiTest.user_rw}}”,不允许直接写出线上敏感信息
无论是代码中,还是本地配置文件中,都不可以出现线上敏感信息。保持代码仓库和提交历史的干净清洁
如发现敏感字符,push失败,并清除commit历史
使用raw sql:历史上发生了太多SQL注入的血的教训,如上文所述,我们全体使用ORM。如果审核发现raw sql,也会终止push代码。
包版本扫描:有些包自带漏洞,禁止使用。
硬编码扫描
未配置 secure 和 httpOnly 的 cookie 扫描
对于应用安全的评审,我们除了定期购买渗透测试外,还采购了“雳鉴”作为日常迭代中安全测试的一部分。
雳鉴是一款IAST(交互式应用程序安全测试)扫描工具。主要通过采集、改写、扩散流量来发现应用中的种种问题,对于常见的低级漏洞支持良好。比较大的问题是,当前对于前后端分离的架构,无法有效的发现的越权漏洞。所以测试同学还是有必要人工的执行部分安全测试,尤其是要注重复测那些曾经出现过的漏洞。
02.
基础架构
来也科技同时拥有toB和toC的业务,我们合作的客户很多都是政府、银行、军工等对安全规范要求较高的公司。所以除了我们的saas产品需要过等保审核外,我们还需要保证给客户部署的集成方案符合等保规范。
除了WAF,访问控制(线上服务器不允许密码登录),最小权限等常规手段,我们还特意购买了漏扫设备。对于基础架构的漏扫,我们是基于绿盟的NSFocus来实现的。NSFocus是一款基于配置的扫描工具,对于常见的CVE漏洞支持良好,同时配置模板模块,该模块可以检测系统、中间件等配置是否符合等保要求。
对于saas服务而言,我们保证每个使用中的系统、中间件,无高危漏洞且配置规范。为了达到这个目标,我们设置以下扫描频率:
每次漏洞库更新后扫描(平均每两周一次)
每次新增/替换服务器扫描(新增的服务器)
每次新增/替换中间件后扫描(新增的中间件)
每次更换中间件版本后扫描
以操作系统为例,我们的漏扫及修复策略是:
首先选取稳定且被广泛认可的版本
对于这个版本进行全面扫描,并将漏洞记录到tapd
对于扫描出来的漏洞执行修复操作,并记录解决方案
重新扫描修复后的操作系统,如有漏洞,从步骤3开始重复,直至所有漏洞修复完成
如漏洞库有更新(新的0-day漏洞提交),或是操作系统要进行必要的升级,则从步骤2开始重新扫描
我们按照以下维度,对漏洞进行打标签处理。修复的过程中,我们会按照标签分类来分批修复,维护补丁集合:
漏洞类别:系统、中间件。。。
漏洞的严重程度:高危、中危、低危
修复的影响范围:比如gcc影响范围极广的,不要轻易动
是否需要重启:重启服务器,重启中间件,不需要重启
对于可以使用镜像的场景,诸如:新的私有部署需求,新增服务器或中间件等。我们选择使用打过补丁的镜像直接发布。由于不同的业务可能适配不同版本的操作系统或中间件,所以我们需要在镜像仓库中维护多个版本的“修复镜像”。比如:镜像仓库中,同时维护了“MySQL5.6的修复版本镜像”和“MySQL5.7的修复版本镜像”。(理论上MySQL5.7应该修复了MySQL5.6的通用漏洞,但是不(hao)可(wu)否(yi)认(wen)的是,新的版本也会引入新的漏洞,更别提那些还没有被白帽子(或黑客)发现的0Day。所以,升级版本不是解决一切万能大法)
无论是saas,还是私有部署,需要再次部署MySQL时,直接从镜像仓库中获取修复版本镜像即可。
倘若漏洞库更新,发现了新的漏洞,那么除了对正在使用的MySQL打补丁外,还需要更新镜像仓库中的MySQL为最新修复版本镜像。对于可以直接替换的,比如k8s中的docker镜像,则在修复镜像后,串行替换即可。
对于不能使用镜像的场景,诸如:不停机的升级操作系统或中间件。我们使用脚本去打补丁,补丁集合分类存放在oss上。
经过一个多Q的努力,来也科技正在将安全CI化。除了日常进行安全培训,提高大家的安全意识外。我们也将安全开发、安全测试、安全运维,作为日常工作的一部分来执行。来也科技安全上线的流程:

安全无小事。在未来,我们将更加完善自己的安全体系,SDL,蜜罐,SRC等一系列安全发现也预防机制都会逐渐建立。
本文作者:刘桐烔,byteyang
本文编辑:刘桐烔



