

一.前言
在前边我们分享了智能文档核心需要解决的场景,以及在深度学习的范式下,比较有代表性的深度学习模型,参见我们已经发表的博客 《智能文档核心概念解读》【1】
在来也科技,智能文档处理是我们核心产品之一,我们智能文档处理产品(IDP)【2】在中国信通院首轮“可信 AI ”智能文档处理产品评测,在技术能力模块、产品能力模块、应用能力模块均获评最高级“5”级【3】。
为了解决智能文档中的SER: 语义实体识别 (Semantic Entity Recognition)和RE: 关系抽取 (Relation Extraction)问题,综合了目前现有的各种方案,基于可解释性、人工特征注入的便捷性、模型的推理速度、预训练模型等因素,我们选择了基于图卷积的模型来解决上述的问题,在下文我们将从图卷积原理、特征工程、来也的图卷积模型、自监督任务设计、其他优化几个方面阐述我们所做的工作。
二.图卷积基本原理简介
在图卷积的原理上有一篇非常好的文章【4】,入门的同学可以精读这篇文章。
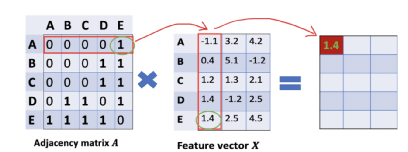
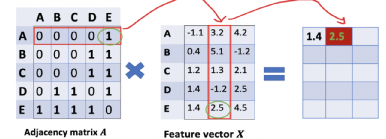
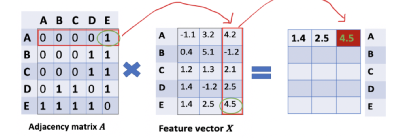
基本的出发点:对于图G上的节点,每个节点的特征是由邻居节点决定的,最简单的做法可以认为一个节点特征是其邻居节点特征的和。
假设一个图G有n个节点,每个节点输入特征维度为d,定义邻接矩阵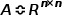 ,节点的特征矩阵
,节点的特征矩阵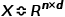 ,度矩阵
,度矩阵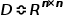 其中
其中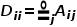
用数学的方法来描述如下节点特征X迭代
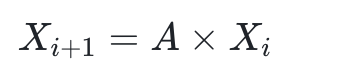
如下图可以看清楚原理
但是上边做法有两个缺陷:
1.忽视了节点本身的特征
2.没有进行特征值归一化,这样边越多的节点特征会在迭代过程放大
所以做两个改进:
1.对邻接矩阵加上单位矩阵,这样就可以保留节点自身的特征,对于新邻接矩阵记作
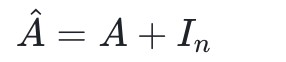
2.归一化可以采用乘以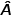 度矩阵
度矩阵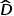 的倒数
的倒数
所以得到的迭代公式如下
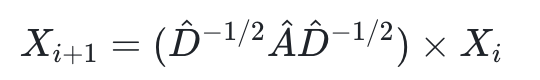
其中左乘 是为了行归一化,右乘是为了列归一化,因为乘了2次,所以要对是开一次根号。
是为了行归一化,右乘是为了列归一化,因为乘了2次,所以要对是开一次根号。
而在我们模型学习过程中,需要对特征X进行特性映射和非线性变化,所以会得到最终的特征迭代公式
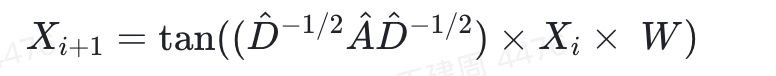
其中W是带学习参数,tan为非线性激活函数,i为图卷积的层数
三.邻接矩阵
从第二部分的原理可以看出,在整个图卷积中,邻接矩阵A非常关键,好的邻接矩阵可以有效地聚合邻居节点的特征。但是在文档中,不像社交网络,蛋白质分子结构等存在自然的邻接矩阵,所以需要构造邻接矩阵,在我们的实践中,采用三种邻接矩阵的构造方式,一种是规则预计算,剩下两种的邻接矩阵跟着模型 一起学习,下边将逐一介绍
1.规则邻接矩阵
如上图,在文档中,可以认为每个文字区域为图上的一个节点,在规则构造中,从左上角节点开始,每个节点依次向右、向下投影,有交集的第一个节点可以认为是有边相连,在这里还可以加入节点的距离变换(如倒数)作为边权重。
这种做法比较复杂,要写较多的预处理代码,此外规则驱动的邻接矩阵抗泛化差,比如距离作为边权重,相同距离的情况下,在文档顶部的节点语义相关性要弱于文档底部,这种通过距离作为边权重没法体现。
2.位置信息学习邻接矩阵
对于文本节点i的 左上角坐标 < 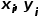 >,宽度和高度 <
>,宽度和高度 < 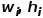 >,与文本节点j可以构造如下的特征
>,与文本节点j可以构造如下的特征
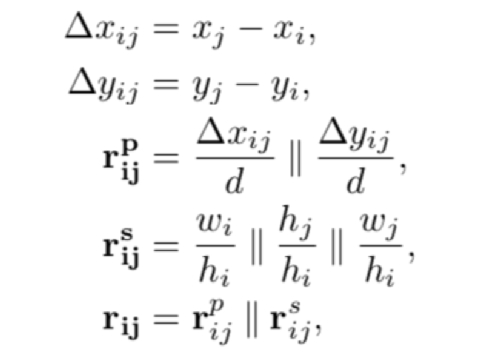
其中d为归一化参数,对于一个有n个节点的图G,可以构造出输入特征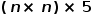 ,我们在最后 一维上进行非线性变化学习得到
,我们在最后 一维上进行非线性变化学习得到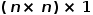 ,最终reshape为
,最终reshape为 的邻接矩阵。代码如下:
的邻接矩阵。代码如下:
Python |
这种做法简单、速度快,相比规则邻接矩阵效果好,但是也会有一些问题:
1.邻接矩阵只考虑节点的位置和形状,忽视了节点其他特征
2.在GCN多次前向卷积中,相同节点特征的关系(边权重)在不同层可能会发生变动,但是根据位置学习邻接矩阵是不变的,没法捕获这种差异性
基于这个缺点,我们采用GAT来构建邻接矩阵。
3.GAT 邻接矩阵
GAT 是通过节点之间计算注意力矩阵来得到邻接矩阵,在这里我们参考论文【5】,在每一层前向传播中,都会利用上一层得到节点特征计算邻接矩阵,为了减少计算量,我们只对节点两两计算注意力作为邻接矩阵的边,采用轻量级别的注意力对齐算法,对计算的邻接矩阵做归一化作为最终邻接矩阵。在计算过程我们也考虑节点之间位置拓扑关系。对于节点i和j,左上角坐标 < >、< 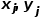 > 归一化前的边权重计算公式如下:
> 归一化前的边权重计算公式如下:
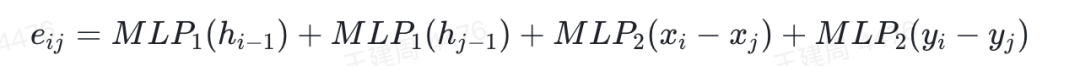
MLP为两层的全连接非线性变换,第一层h特征为原始的节点的特征。
四.节点特征
特征工程对于机器学习非常重要,虽然深度学习强大的特征提取能力减少了特征工程的复杂性,但是仔细的设计特征对于深度学习来说,也会有相当的收益,在这一节,我们将简述我们所做特征工程。
1.文本特征
对于每一个文本节点,我们采用了预训练的roberta【6】进行编码作为表征,其中根据统计的样本,为了减少计算量我们统一截断文本长度为48个字符,此外考虑到SER和RE中许多任务是和阿拉伯数字组成的编号有关,我们在训练过程中,将所有的阿拉伯数字转成一个特殊的字符,让所有的阿拉伯字符表示同一个语义。
2.图像特征
训练良好的roberta虽然能很好的表达文本语义信息,但是只用文本信息的话会丢失一些关键的视觉信息,如字体、颜色、文字是否加粗等。这些视觉信息对于模型的提升也会有很大的帮助,所以我们也加入图像特征作为模型输入,
在图片特征提取上,我们采用UNET 【7】模型,UNET 架构是一种像素级别任务如图像分割非常简单有用的模型、通过图像卷积和下采样获取大区域的抽象语义级别的信息,再通过上采样恢复图像的宽高分辨率和原图一致,获取像素级别语义信息,也方便像素级别的任务head接入。
我们用UNET提取了全图特征,全局特征每个文本区域bbox的特征作为这个节点的图像特征。
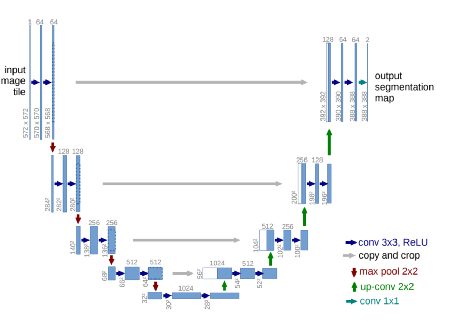
3.人工特征
SER的语义实体以及RE中答案,大多数情况下有一些很明显的范式,根据观察,对于每一个节点的文本串、我们又构造了如下特征:
数字字符数占比
字母字符数占比
标点符号占比
中文字符占比
是否特殊实体(共有以下几种:人名、金额、邮箱、日期、url)
4.编号特征
对于一张图,我们对所有节点根据左上角坐标排序后,根据编号顺序得到Embedding特征作为编号特征
5.位置特征
对于原图宽度和高度,对于节点i 左上角坐标<>,宽度和高度 < >,文本字符数s,我们构造如下位置特征
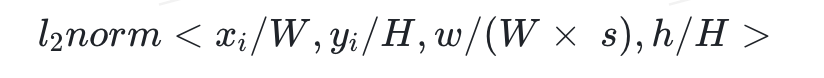
6.特征融合
对于节点i的文本特征  、图像特征
、图像特征 、人工特征
、人工特征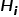 、编号特征
、编号特征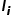 、位置特征
、位置特征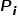 采用如下方式融合得到模型节点的输入特征
采用如下方式融合得到模型节点的输入特征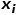


文本特征 、图像特征没有采用基本的拼接融合,主要是考虑对于不同的节点 与的重要性不一样,学习通过注意力方式学习一个融合权重,这样就能很好的捕获两个特征的差异性。计算公式如下:
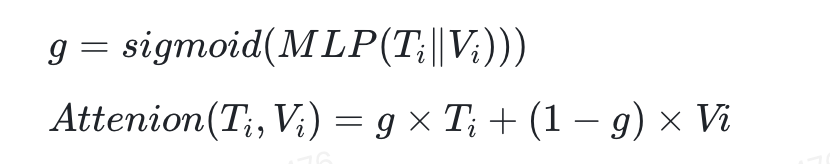
五.应用场景
在来也科技的智能文档产品中,我们将图卷积主要用在以下任务中
1.SER 语义实体识别
比如在营业执照,身份证等卡证上的结构化上。我们利用图卷积得到每个文字区域的特征,基于特征做结构化分类从而得到 ”韦小宝“为人名,”男“为性别等。在类似场景中,如果一种语义实体有多个文字区域,我们直接对这多个区域进行拼接输出,如这张图片的地址。

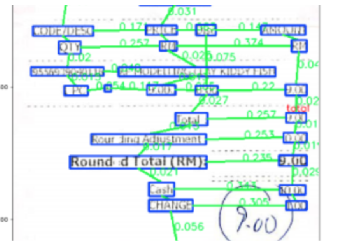
2.RE 关系抽取
在真实场景中存在大量的自定义表单,没法用预先定义实体类别的方式来完成,但是表单上存在自然key-value关系对,如下图。

在这个任务中我们利用GCN得到节点特征 ,利用节点特征重建新的邻接矩阵,有边连接的节点认为就是存在k-v关系对。假设节点的特征矩阵,因为重建的邻接矩阵是有向图邻接矩阵,所以在重建邻接矩阵时,需要借助一个非对称矩阵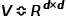 ,重建邻接矩阵的公式如下:
,重建邻接矩阵的公式如下:

成对key和value节点在的位置大于0.5。
3.多任务
例如在英语购物小票中,SER和RE任务同时存在,需要准确的分类节点识别出地址、电话、商品等,同时也要准确的预测出关系对,如一个商品名称对应的价格以及数量

六.自监督学习
在RE和SER任务上,一般来说需要解决的场景,数据因为隐私等问题,是极其难以获取的,所以我们也采用预训练+微调的模式,希望的是用较少的真实场景样本就可以取得不错的效果。
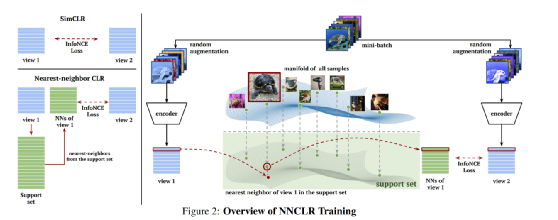
在综合各种自监督任务优缺点上,我们采用图对比的方式进行自监督训练,自监督训练我们采用NNCLR【8】的方式,NNCLR相比对比学习中比较经典的simCLR【9】、MOCO 【10】,最主要的改进思路是采用正例的最近例作为对比中正例,一定程度上避免过拟合,NNCLR的原理如下图:
在图特征提取上,我们尝试对节点特征进行MaxPool,AvePool,以及Attention Pool 得到全图特征,发现Attention Pool的效果是最好的。
经过自监督的预训练对下游模型的效果提升是巨大的,如下图的PO单,需要实现SER任务,我们在仅有的26张图片上F1 只有18%,但是采用预训练的模型,加上数据增强,F1可以提升至90%。

七.其他优化
在图卷积中使用中,除了超大图的计算等问题外,另外一个困难的问题是over smoothing【11】,也就是图卷积中随着层数的增加,感受野会变大,但是随着特征传递、最终学习的每个节点特征会趋于相同,所以一般在图卷积中层数不能太多,但是过浅的层数没法捕获多跳路径太远节点的特征相关性,为了解决这个问题,我们跟踪最新前沿的不少方向,经过多次实验,最终选用以下几个方式:
1.highway 特征拼接
我们借用resnet 的highway 做法,每一层前向计算的节点特征会和上层前向计算的特征求和得到最终的输出特征。
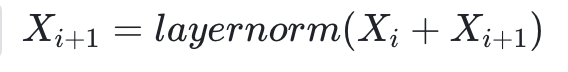
2.稀疏化邻接矩阵
在训练过程,我们对前向传递中邻接矩阵,只保留30%最大的值,其他的值直接置为0,避免一些相关性不强的节点进行特征传递。
3.drop edge
在深度学习中,dropout是一个非常常见提高模型泛化性的手段,经过仔细思考,我们在前向过程中采用drop edge 技术,随机将邻接矩阵一部分扔掉
八.参考文献
1https://mp.weixin.qq.com/s/YseBBNAkOu2084l0_6elJw
1https://cloud.laiye.com/idp/
1来也科技智能文档处理平台喜获中国信通院评测全能力域最高级 https://mp.weixin.qq.com/s/qmX0NFc2imBUPgEjHtWb5w
1https://medium.com/ai-in-plain-english/graph-convolutional-networks-gcn-baf337d5cb6b
1https://arxiv.org/pdf/1710.10903.pdf
1https://arxiv.org/abs/1907.11692
1https://arxiv.org/pdf/1505.04597.pdf
1https://arxiv.org/abs/2104.14548 nnclr
1https://arxiv.org/abs/2002.05709 simclr
1https://arxiv.org/abs/2003.04297
1https://arxiv.org/pdf/1909.03211.pdf over soomthing



