

1、简介
随着互联网上的文本资源日益丰富,用户逐渐需要耗费大量的时间查找所需信息,并且很难有充足的时间阅读和理解完整的篇章,同时文本中存在着大量的重复和不重要的内容,因此对文档中的信息形成精炼的摘要就显得尤为迫切和重要,而手动形成摘要费时费力,自动摘要就成了解决这一问题的直观方式。自动文本摘要通常包括三种方法,一是抽取式摘要,直接从原文抽取重要句进行合并,用来代表原始篇章,二是抽象式摘要,通过对原文进行语义表示,再解码成代表原文中心思想的句子,生成的句子和原文表述不同,三是混合式方法,将抽取式和抽象式方法进行结合。在目前提出的方法中,自动生成的摘要和人工生成的摘要依然相差甚远,工业界和学术界研究人员依然致力于为解决这一难题而努力,同时较多的研究被放在抽象式和混合式方法上。
2、自动文本摘要系统的分类和应用
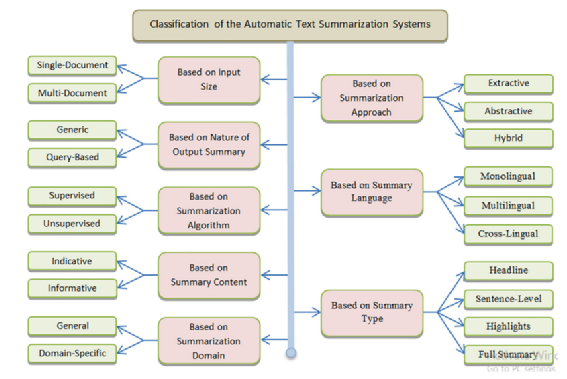
2.1 系统分类
自动文本摘要系统的分类有不同的分类依据,根据输入的规模,分为单文档摘要和多文档摘要;根据生成摘要的方式,分为抽取式、抽象式和混合式;根据输出摘要的属性,分为generic和query-based,generic指的是对文档核心思想的提炼,而query-based需要先根据输入query检索到相关文档集合,再进一步形成query、主题、用户相关的摘要;根据摘要的语言可以分为单语言、多语言、交叉语言;根据摘要的算法可以分为有监督的和无监督的;根据摘要的内容可以分为indicative和informative,indicative包含了原始文档的方向性内容,如主题,用来引导用户快速决策是否要进一步浏览原文,而informative则包含了原始文档的重要信息,是原文的简短性概括;根据摘要类型,分为headline(shorter than a sentence)、sentence-level(abstractive sentence)、highlights(重点短语)和full summary;根据摘要的领域分为通用领域和特定领域。
2.2 系统应用
自动文本摘要系统在文本挖掘和分析应用中应用广泛,如信息检索、信息抽取、自动问答等。常见的自动文档摘要应用包括新闻摘要生成、观点/情感摘要、微博/Tweet摘要、书籍摘要、故事/小说摘要、邮件摘要、生物医学文档摘要、法律文本摘要、科学论文摘要等。
3、自动文本摘要方法
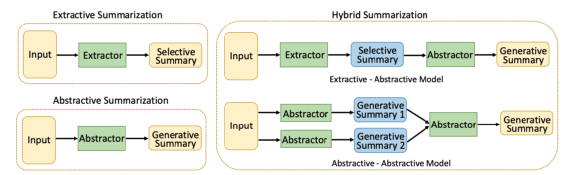
图 自动文本摘要流程
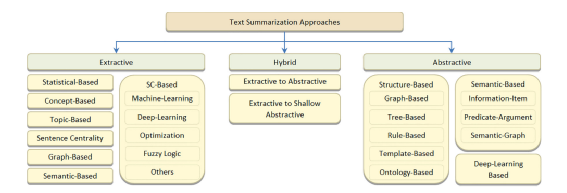
图 自动文本摘要技术体系
3.1 抽取式文本摘要
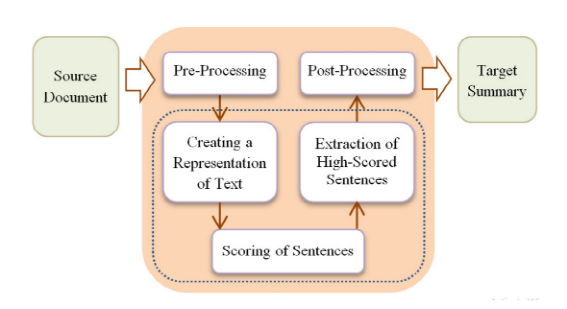
抽取式文本摘要包括1)原始文本预处理;2)对原始文本进行表示(N-gram,bag-of-words,graphs等);3)基于表示对sentence进行打分;4)抽取分数高的sentence;5)后处理:句子重排序、指代消解等;抽取式文本摘要方法简单,速度较快,且摘要准确率较高,但和人工编写的摘要相差甚远,抽取式摘要存在较多的句子冗余、过长、表达冲突、句子之间缺乏衔接、重要信息可能缺失等。
基于统计的方法将重要句定义为最易出现的位置、频繁句等,这种方法通过一些统计特征和语言学特征为句子赋予权重,并通过权重来选择重要句。该方法处理速度快,不需要额外的语言学知识,但特征过于简单,句子之间缺乏交互,生成的摘要可能包含较多相似句。
基于概念的方法通过引入外部知识如WordNet、HowNet、Wikipedia等,基于sentence检索外部词典,得到一些关键概念用于计算句子的重要性,同时基于概念的表示来计算句子和概念之间的关系,最后通过排序算法来对句子进行排序(考虑到句子的概念重要性、以及概念和句子的相关性)。该方法生成的摘要包含较多的概念,但摘要的质量较大程度依赖于抽取的概念的质量。
基于主题的方法使用TF、TF-IDF、词汇链、主题词的方法来形成一个主题下的重要词汇表,并基于该词汇表对文档中的句子依次打分,进而选择打分高的句子作为摘要的内容。该方法生成的摘要主题集中,但选择的主题影响了重要句的选择,一些较重要的句子可能因为和主题不太相关而漏选。
基于图的方法使用无向图来对文档进行表示,节点为文档的句子,节点之间的边为句子的相关性,最后通过LexRank/TextRank等方法选出重要句。该方法能有效检测冗余信息,且增强了摘要句之间的紧密度,但使用bag-of-words及词之间的相关性一方面并未考虑到不同的词在文档中的重要性,另一方面在语义的刻画上较弱。
基于语义的方法通过词的共现得到句子的语义表示,对文档的句子表示构成的矩阵进行SVD分解,得到不同topic下的语义表示,在计算句子重要性时,将term表示、句子表示和主题表示进行融合,强化句子的语义表示,在语义的表示上,Semantic Role Labelling(SRL)和Explicit Semantic Analysis(ESA)也是较常用的方法。该方法语言独立,且生成的摘要句之间有较强的语义关联,但依赖对句子的语义表示,且SVD计算耗时。
基于机器学习的方法把摘要的生成转化为对每个句子进行二分类,判定属于摘要还是不属于,先对句子抽取特征,然后将其输入神经网络得到二分类判定得分。该方法需要依赖大量的标注数据,且相对简单的regression模型获得的分类效果较好。
基于深度学习的方法使用词的embedding来进行语义表征,一个句子对应若干个词,形成句子的表征,接下来以最大化次模函数为目标(余下句子的最大价值最小)来抽取重要句。该方法生成的摘要更贴近人的阅读风格,但需要人标注大量的数据训练模型。
基于优化的方法首先形成句子的表示,然后利用优化方法如Multi-Objective Artificial Bee Colony (MOABC) 在多个指标如content coverage, redudancy reduction, relevance and coherence上达到最优。该方法计算量较大,且需要数次迭代来实现最优化目标。
基于模糊逻辑的方法模拟人类的推理,在对句子完成特征提取(句子长度、term weight等)后,结合fuzzy-logic理论对句子进行打分。
HiStruct+: Improving Extractive Text Summarization with Hierarchical Structure Information,ACL Findings 2022
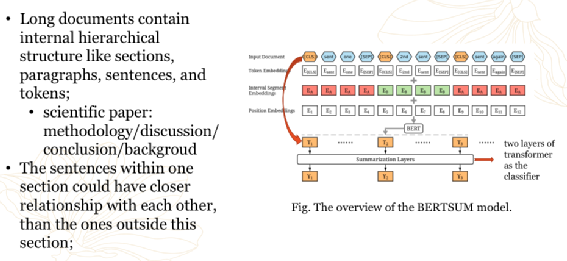
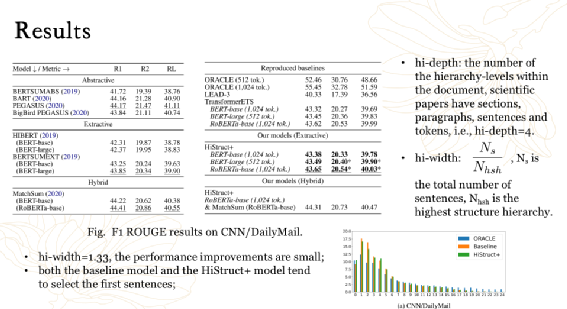
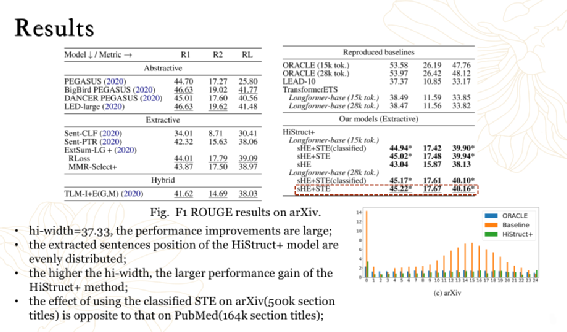
3.2 抽象式文本摘要
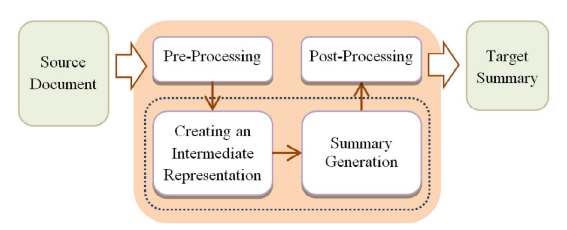
抽象式文本摘要过程包括1)文档预处理;2)对文档进行向量表示;3)摘要生成;4)后处理。该方法生成的摘要具有更强的灵活性,通过一定程度的paraphrase,语义上具有更高的压缩性和聚焦性,和人工生成的摘要更贴近,较少冗余。在实际操作中,生成一个高质量的抽象式摘要是比较困难的,需要对原文有非常准确的理解和表示,并且不能很好地处理OOV的问题。在一些受限领域,数据较少,摘要生成效果可能较差。
基于图的方法将词的语义和位置信息表示为顶点,边记录句子之间的结构,在生成摘要的过程中,首先构建图,然后在图中寻找合理的路径,基于相关性过滤有重复的路径,最后使用余下路径中的词构成摘要。
基于树的方法可以较好地利用互信息来生成摘要,首先对输入文本进行解析构造语法树,然后基于不同的大小选择部分独立的树,然后使用聚类的方法对选择的树进行聚类,以保障多样性,最后挑选不同簇的树形成句子来输出摘要。
基于规则的方法需要定义规则来区分重要句,首先通过term和concept来对句子进行分类,接下来使用规则生成包含关键term的问句,通过检索并进行term和concept匹配来得到候选答案,最后将这些答案输入到特定的模版中生成摘要,在该方法中,依次进行启发式的内容搜索、信息抽取和特定pattern的内容生成。
基于模版的方法着重于解决特定领域的摘要生成,如会议摘要,这些摘要有着特定的模版,直接应用抽取规则和语言学模式对模版中的slot进行填充即可。
基于本体论的方法通过对特定的领域构造知识词典作为ontology,并依赖ontology来形成摘要。
基于语义的方法首先使用information terms,predicate- argument structure,semantic graph对输入进行语义表示,然后将表示输入自然语言生成系统实现摘要的生成。
基于深度学习的方法得益于seq2seq框架的盛行,通过深度网络模型对输入进行表示,然后输入到decoder网络进行token解码,完成摘要的生成。这种方法依然面临OOV和重复token解码的问题。
当前研究的重点依然在深度学习模型在短文本抽象式摘要上的应用。如多模的融合、混合式摘要的生成等。
Sequence Level Contrastive Learning for Text Summarization,AAAI2022
AAAI2022清华、微软、上海期智研究院的工作,将原始文档、标注摘要、模型生成摘要作为3个sequence,使用对比学习让两两之间的距离尽可能接近。
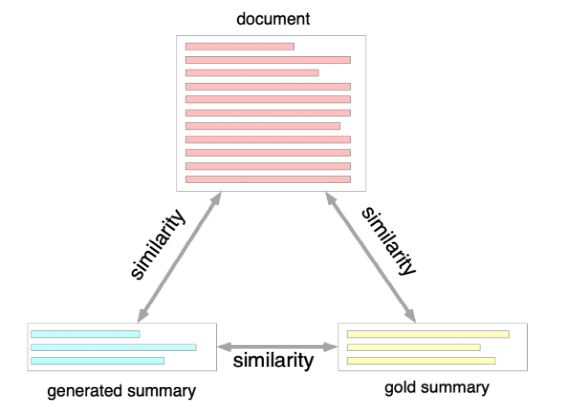
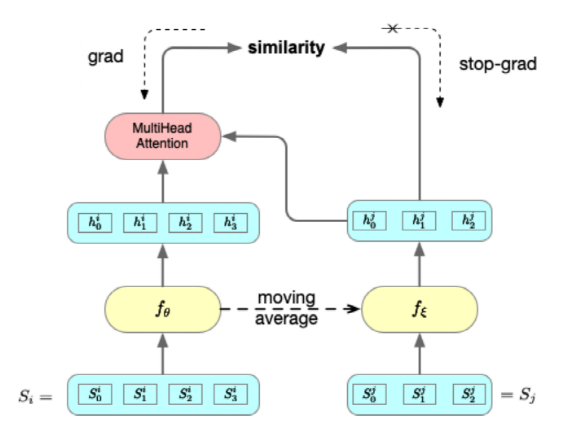
模型框架如下所示:

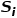 和
和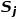 为对比的两个sentence。
为对比的两个sentence。
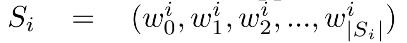
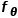 和是相同的网络框架,不同的参数,代表的是Transformer Encoder后接Feed Forward,对于经过的输出编码成隐向量后,接入MultiHeadAttention,该模块输入
和是相同的网络框架,不同的参数,代表的是Transformer Encoder后接Feed Forward,对于经过的输出编码成隐向量后,接入MultiHeadAttention,该模块输入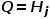 ,
,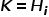 ,
,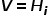 ,使用该网络的目的在于加强word-word之间的交互,同时给出size相同的输出,因为不同的sentence可能长度不同,同时bert的[CLS]向量也可以拿来进行上述计算,但作者实验说明该向量效果较差,因此最终采用的是MHA架构。最终MHA模块的输出和Feed Forward的输出维度相同,代表整个sentence的语义表示,通过计算两者的相关性,使用距离最近来约束参数的更新。
,使用该网络的目的在于加强word-word之间的交互,同时给出size相同的输出,因为不同的sentence可能长度不同,同时bert的[CLS]向量也可以拿来进行上述计算,但作者实验说明该向量效果较差,因此最终采用的是MHA架构。最终MHA模块的输出和Feed Forward的输出维度相同,代表整个sentence的语义表示,通过计算两者的相关性,使用距离最近来约束参数的更新。
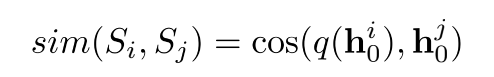
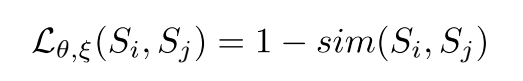
在参数更新时,同时更新和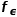 ,会导致更新策略过于简单方法不生效,因此采用只用gradient更新,然后采用动量方式更新。
,会导致更新策略过于简单方法不生效,因此采用只用gradient更新,然后采用动量方式更新。
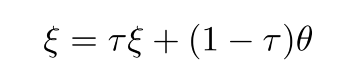
最终整体的Loss由5个部分组成:
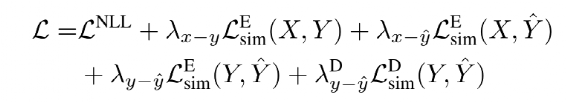
第一部分Loss为Negative Log-Likelihood,表征的是seq2seq解码的概率最大化:
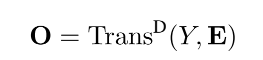
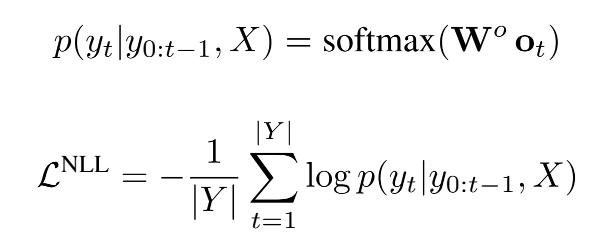
中间3个Loss为原始文档x,标注摘要y,和模型生成摘要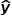 彼此的距离:
彼此的距离:
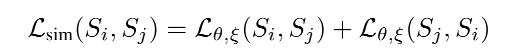
最后一个Loss为经过解码网络后标注摘要和生成摘要文本表示的距离,计算方式同上。
整个训练超参初始值如下:
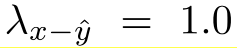
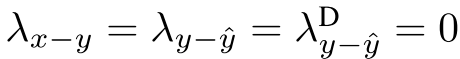
随着被采纳,可以不断迭代修改朝着ground truth靠近,同时保障两者similarity的loss尽可能小并不能保证NLL的loss最优,因为前者是句子维度的刻画,后者是token维度的刻画。
该方法在CNN/Daily Mail、NYT、XSum三个数据集上效果如下:
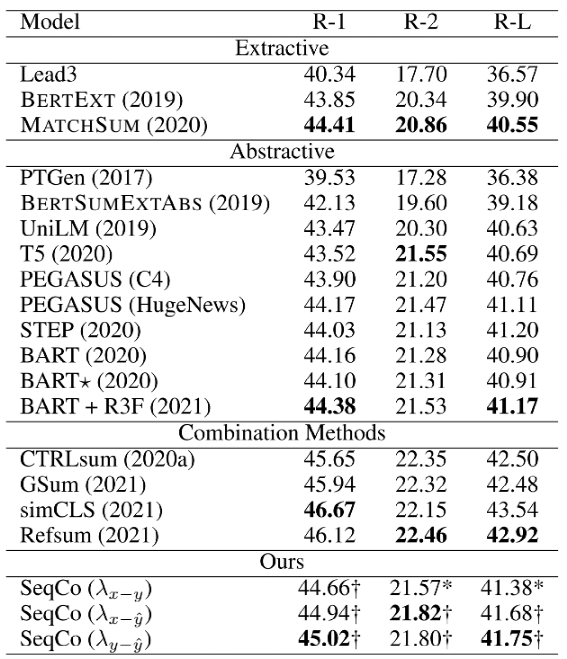
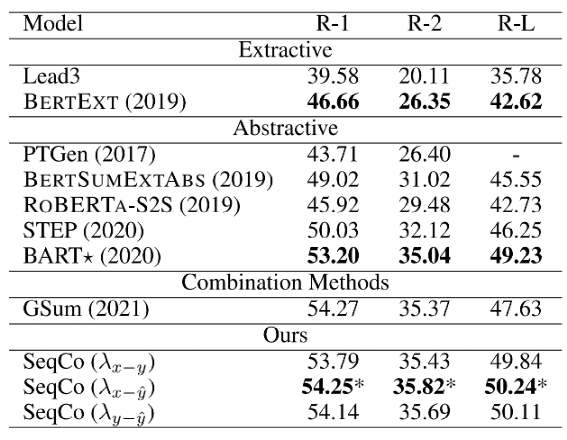
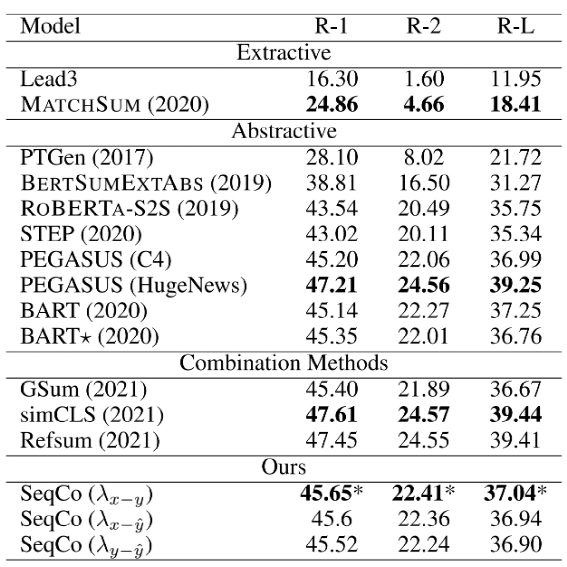
在训练过程中,通过实验发现MultiHeadAttention通过加强token之间的交互,效果优于直接使用[CLS]计算similarity,当对比学习应用于多个pair时,效果差异不大,但速度会明显降低。

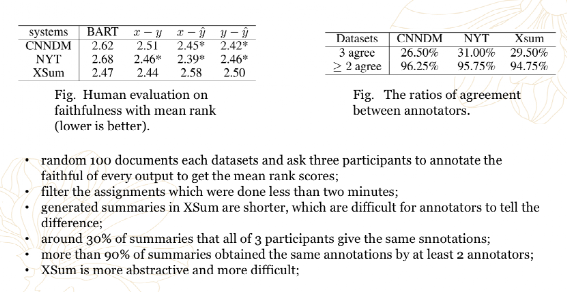
在人工评估上,每个数据集随机sample 100个文档,让参与者标注模型输出的置信度,分为1-5共5个level,取mean rank为最终评估指标(越低越好)。
3.3 混合式文本摘要
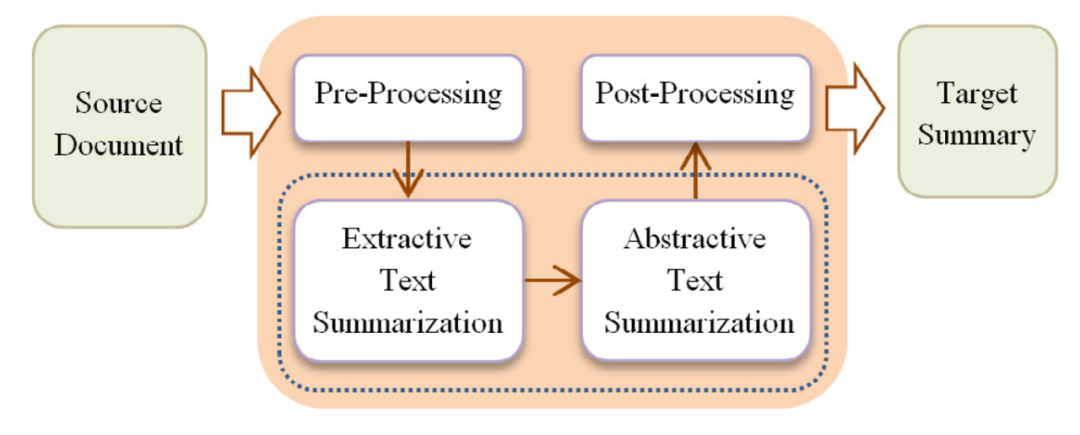
混合式文本摘要过程包括1)文本预处理;2)抽取式摘要生成;3)基于抽取式摘要输出完成抽象式摘要生成;4)后处理。该方法对抽取式和抽象式摘要方法进行融合,互补以提升性能,但可能产生质量更差的摘要,因为抽象式摘要的生成高度依赖抽取式摘要的结果,若抽出的句子非重要句,可能导致生成的摘要出现较大的语义偏差。
先抽取式再抽象式方法首先通过抽取式摘要方法如图模型抽取重要句,然后通过抽象式摘要方法如RNN构成的Encoder- Decoder网络结合指针模型和attention机制生成摘要。
先抽取式再浅层抽象式方法首先通过抽取式摘要方法抽取重要句,然后使用信息压缩方法、信息融合方法、同义词替换等生成和原文不同的摘要句。
Proposition-Level Clustering for Multi-Document Summarization
NAACL2022的文章,常见的摘要提取方法都是针对句子来做的,本文提出针对Proposition sentence(观点句)来提取文档的显著信息,再应用聚类的方法进一步浓缩句子的选择,有效减少重要句的冗余,使得最终根据重要句生成的摘要更加压缩且能表达主题。
下图为文档句子和proposition的示例,将文档按句子进行组织,蓝色的是proposition,黑色加蓝色为完整的句子。

作者提出的Proposition- Level Clustering方法整体流程如下所示:
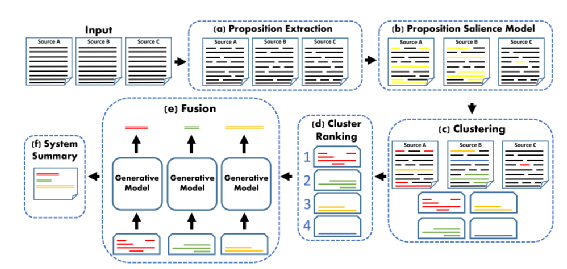
(a) 多个文档使用Open Information Extraction(OpenIE)工具进行Proposition的抽取,allennlp上可直接调用;
(b) 对所有的Propositions使用二分类模型(fine-tune Cross-Document Language Model)进行分类,卡阈值挑选模型分类为proposition的句子,阈值的选择由validation set上整体pipeline完整执行后最终生成的摘要ROUGE得分最大时选定,二分类模型选择Cross-Document Language Model是因为使用该模型在多文档上进行pretrain后在下游分类任务上效果较好,用于finetune的数据label自动生成,通过将所有proposition和目标摘要进行比对,选择使得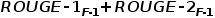 最大的标注组合;
最大的标注组合;
(c) 对选定的propositions进行聚类,聚类相关性使用SuperPAL计算两两propositions的similarity;
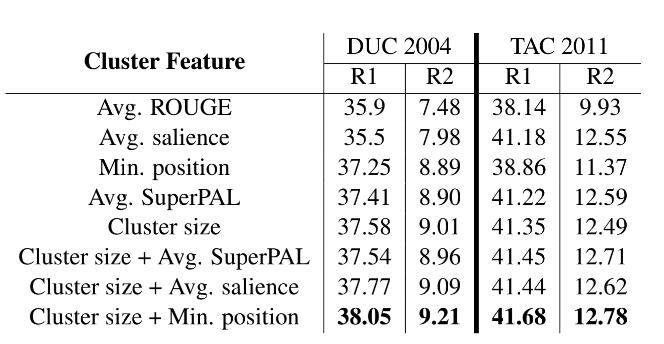
(d) 对聚类后的簇进行排序,排序特征包括average of ROUGE, average of SuperPAL, average of the salience score, minimal position in a document of the cluster propositions, cluster size,本文依次使用单个特征排序,再采用叠加策略排序,如使用单个特征时发现cluster size最有效,那么优先使用cluster size排序,当该特征打平时,采用其它特征如Avg.SuperPAL,Avg.salience,Min.position二次排序,当第二个特征继续打平时,采用maximal proposition salience score继续排序;
(e) 对排序后的簇,依次进行cluster fusion,该部分通过finetune BART来实现,finetune的数据自动生成,将簇中的每个句子和目标摘要的每个句子基于SuperPAL model计算similarity,平均相关性最高的句子即为该簇的目标fusion结果,使用BART进行finetune,输入为簇的若干个句子,按照salience score进行排序,输出为基于SuperPAL找到的目标句;
(f) 使用每个簇fusion后的句子,拼接为最终的abstractive摘要,如果不许句子发生改变,需要生成extractive结果,则从原文挑选和abstractive方法生成的摘要overlap最大的句子作为最终输出。
下图给出了一个proposition聚类和cluster fusion的结果:

在TAC2011和DUC2004 MDS数据集上,该pipeline效果如下:
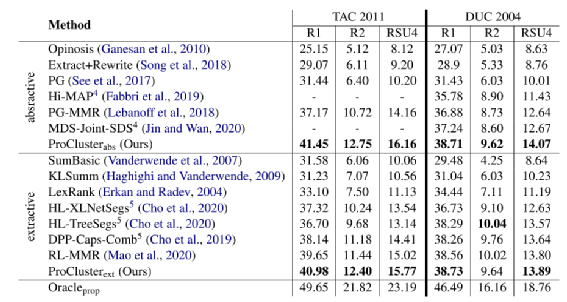
可以看到本文提出的ProCluster方法在abstractive和extractive上都优于sota,作者给出了prop方法的上限,即使用SuperPAL方法基于目标摘要直接对齐原文作为最核心的proposition,再基于该结果进行BART的fine-tune,相当于进一步消除了句子选择过程的噪音。
在人工评估上,ProCluster和两个base model PG-MMR和RL-MMR基于4个维度(生成摘要和目标摘要的overlap,生成摘要的可读性,生成摘要的语法错误,生成摘要的简洁性)进行比较,ProCluster在上述4个指标上均优于base model。
3.4 多文档摘要

图 多文档摘要流程
多文档摘要的难点:如何捕获跨文档和文档内部的关系、如何在包含冲突、重复、补全的向量空间中去抽取和生成关键信息;
多文档摘要和单文档摘要的异同——
相同点:模型结构、学习策略、评价指标、目标函数相似;
不同点:
输入文件的类型更加多样;
跨文档关系需要额外的捕获机制;
输入文档之间存在较高的冗余和冲突信息;
较大的搜索空间,训练数据更为匮乏;
多文档摘要的场景:
多个短文档,如评论摘要,目标是生成多人的简短、翔实的摘要信息;
少数长文,如一组话题一致的新闻,目标是生成更为全面的摘要;
少数长文+多个短文,如一篇新闻及多个评论;
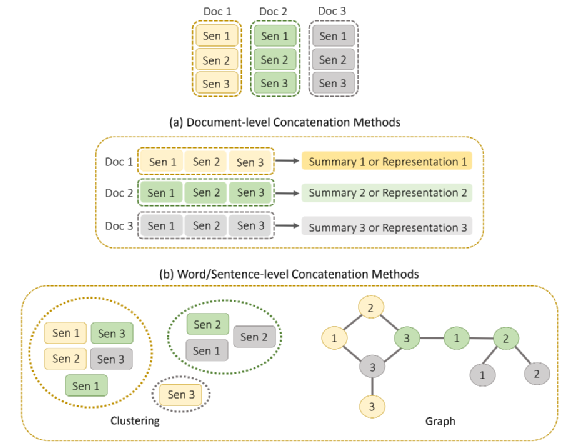
图 多文档信息拼接
图 多文档摘要技术体系
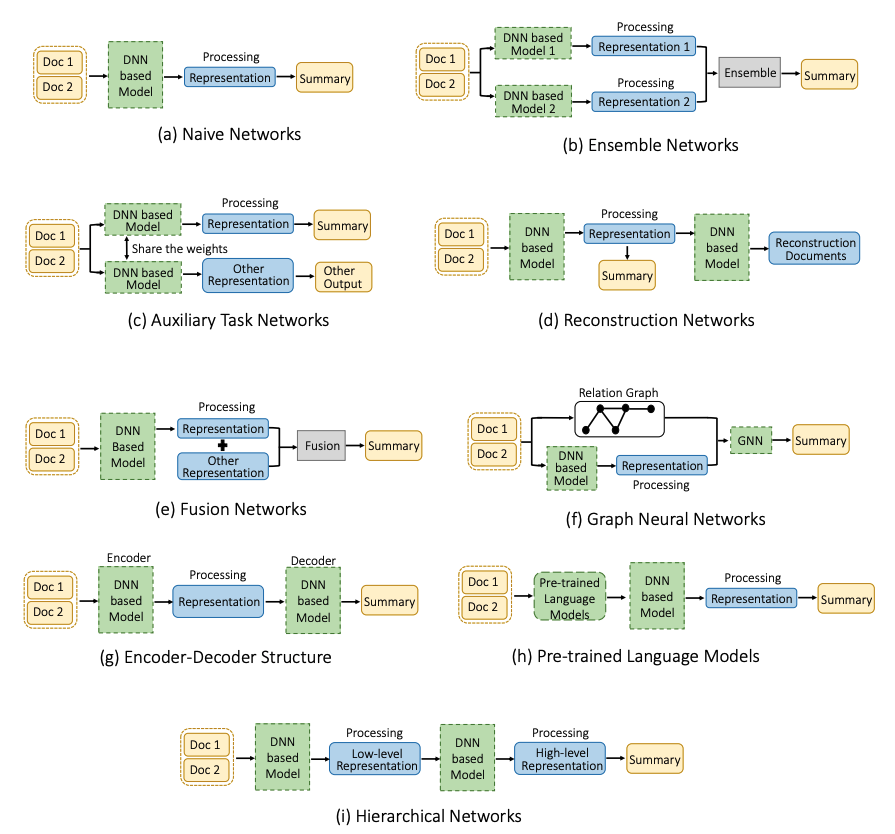
图 多文档摘要结构设计
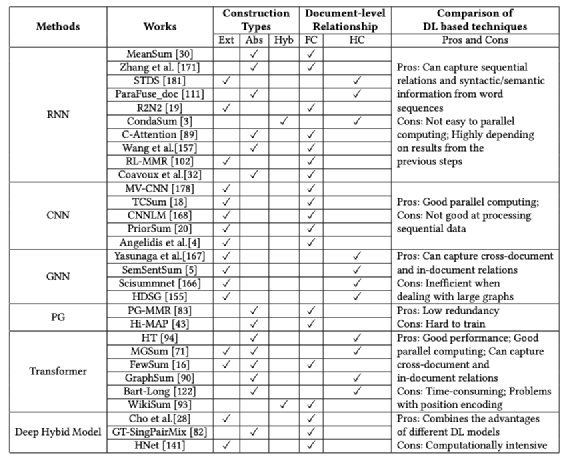
图 神经网络的选型及优缺点
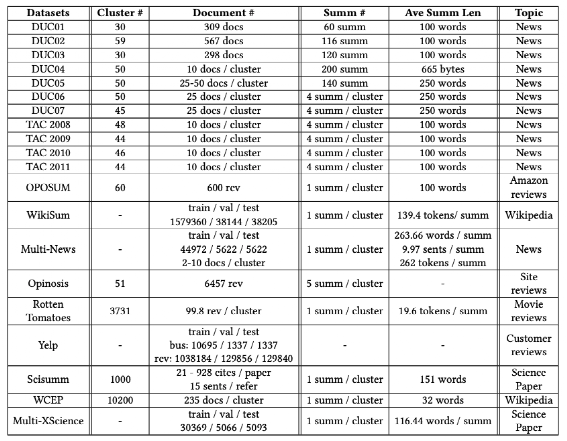
图 多文档摘要数据集
当前多文档摘要的研究重点在学习各文档之间的关联和信息的融合上。
3.5 跨语言摘要
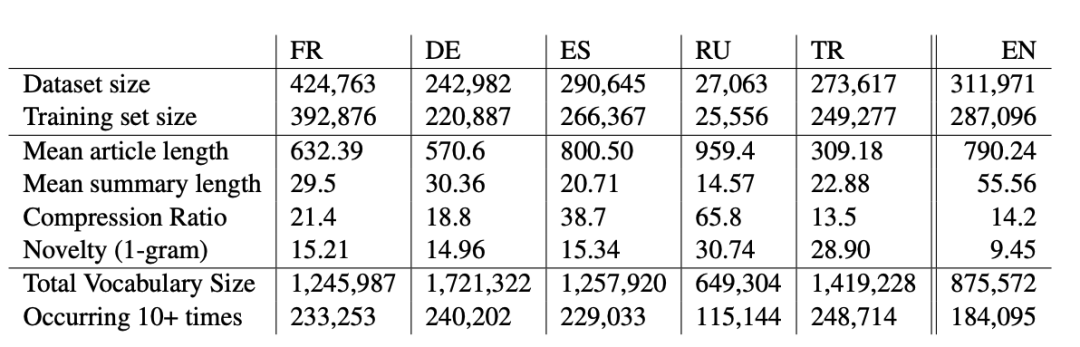
图 MLSUM数据集
20年提出,第一份多语言摘要数据集,5种语言(French, German, Spanish, Russian, Turkish),1.5M+;

图 MLSUM数据集示例
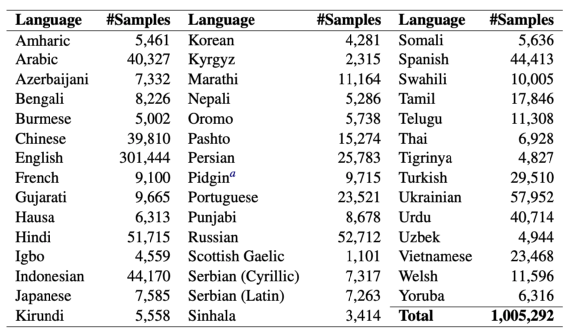
图 XL-SUM数据集,44种语言,21年提出
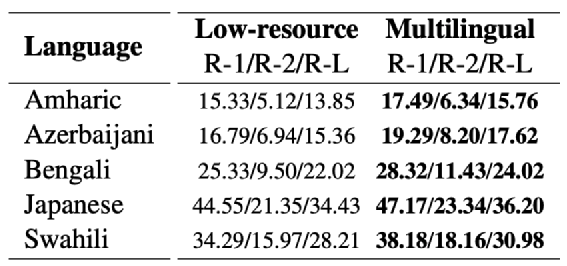
图 XL-SUM数据集上low-resource和multi-lingual实验对比
一般认为单一的数据集上finetune后的模型效果会比multi-lingual效果好,但是在low-resource场景并不是如此。相似的语言之间,存在一定的语义迁移能力。
3.6 对话摘要
包括5类主要的对话摘要场景:会议摘要、闲聊摘要、邮件往来摘要、客户服务摘要、医疗对话摘要,针对对话摘要,未来我们会发布新的博客,敬请关注。
4、自动文本摘要系统构建
对于上述文本摘要流程,构建一个自动文本摘要系统前,首先需要明确统计和语言相关的特征,同时需要明确相关的可执行操作。
4.1 文本摘要操作
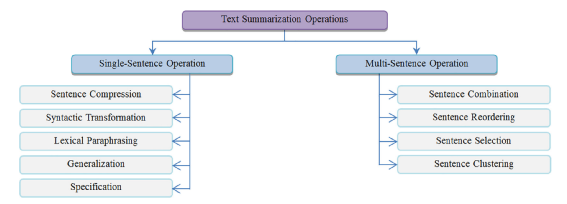
文本摘要相关的操作包括句子压缩/简化、同义转换、词汇改写、常规化表述、特定表述、句子整合、句子重排序、句子选择、句子聚类等。
4.2 统计及语言学特征
统计学和语言学特征主要用于检测文档中的重要句和重要短语,通过对每个句子抽取特征,并给不同的特征赋予不同的权重,使用下述公式对句子进行打分:
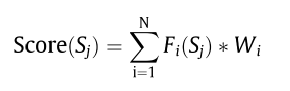
同时为了使得分数在不同的文档中具有可比性,正则化的分数计算方式如下:
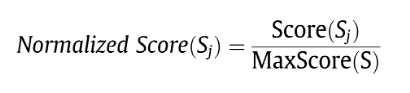
统计及语言学特征包括:Term Frequency,Inverse Document Frequency,TF-IDF,Noun and Verb Phrases, Content Word(Keyword), Title Word, Proper Noun, Cue-Phrase, The occurrence of Non-Essential Information, Biased Word, Font based, Positive Keyword, Negative Keyword, Numerical Data, Sentence Location(Position of Sentence), Sentence Length, Sentiment Features(Emotions), Sentence Reference Index, Sentence-to-Sentence Cohesion, Sentence-to-Centroid Cohesion, Concept Similarity等。
4.3 文本表示模型
文本表示模型用于对文档中的成分(词、句子、文档)进行表示。
图模型包括词汇图模型(以词为节点)和语义图模型(以语义特征作为文本表示)。
向量模型包括词袋模型(统计共现)、向量空间模型(TF-IDF权重)、词嵌入模型(语言模型)。
N-Gram模型包括Bi-gram, tri-gram, quad-gram模型。
主题模型包括LDA、PLSA等。
语义表示模型包括Lambda Calculus(使用函数表示变量和常量)和Abstract Meaning Representation(使用图和节点表示句子)。
4.4 语言分析和处理方法
预处理策略包括:去除header,footer等噪音、文章分段、去除标点、分词、NER、去停、stemming、词性标注、频次统计、文本截断、语义解析、浅层语义分析等。
语义计算方法包括:语义消歧、指代消解、隐层语义分析、文本蕴含、词汇链等。
句子相似度计算方法包括:句法相似度、语法相似度及混合方法。
自然语言生成:解决说什么、怎么说的问题。
4.5 软计算方法
软计算方法探索在不确定性、不准确性、部分真值、近似值中的最大容忍度,来获取更好的处理方法、鲁棒性和低成本。包括机器学习的有监督和无监督方法、最优化方法、fuzzy-logic等。
5、自动文本摘要数据集和评估指标
5.1 标注数据集
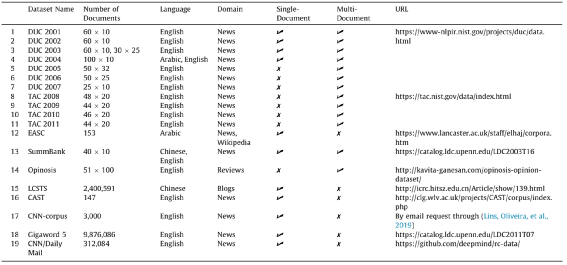
Document Understanding Conference(DUC) Datasets:最通用的摘要数据集,英文新闻,从DUC2001-DUC2011,数据集包含原始文档及摘要,其中摘要有3种形式,人工标注的摘要、基线模型自动生成的摘要、挑战系统自动生成的摘要,获取这些数据集需要填一些DUC网站上的表格,这些数据集通常用来评估摘要系统,而不能拿来训练模型,因为量比较小。
Text Analysis Conference(TAC) Datasets:2008年,DUC开始成为文本分析会议TAC的专用数据集,访问这些数据集需要在TAC网站上填申请表。
Essex Arabic Summaries Corpus(EASC)Dataset:阿拉伯语,新闻&维基百科。
SummBank Dataset:2003,中文、英文,新闻类,40类新闻,360个多文档手工编写非抽取式摘要,接近200万的单文档、多文档自动生成摘要,可用于训练模型。
Opinosis Dataset:2005,英文评论,51个文件,一个文件一个主题,关于产品的一个特性,如电池寿命等,文件包含若干客户撰写的评论,每个主题大概包含100句评论,每个topic有5个人工手动编写的摘要。
Large-scale Chinese Short Text Summarization(LCSTS)Dataset:2015,新浪微博发布的200w短文本及摘要,中文。

Computer-Aided Summarization Tool(CAST) Corpus:2003,英语,量少,来自路透社和一些科学研究的新闻通讯文本,语料中包含三种信息的注解,一是句子重要性、二是句子之间的链接、三是可删除的文本片段。该数据集在减少句子和句子选择的算法中比较有用。
CNN-corpus Dataset:2019,英文新闻,单文本摘要,包含原始文本、高亮文本、黄金标注摘要文本,主要用于抽取式摘要竞赛。
Gigaword 5 Dataset:2016,上千万的新闻文档,将标题作为摘要内容,用于训练抽象式摘要生成模型。
CNN/Daily Mail Corpus:deepmind发布的30w+英文新闻,CNN指的是美国有线电视新闻网,DailyMail指的是英国的每日邮报。该语料最初用于对话式问答任务,现也广泛用于抽象式文本摘要系统评估,2016年对该语料进行升级,包含对多个段落形成摘要文本。
5.2 评估指标
文本摘要的评估目标是生成更加压缩、更具有可读性且准确表达文档核心思想的文本,需要考虑信息的覆盖面、信息的重要程度、信息的冗余度和文本之间的连贯性这几个方面。
人工评估指标:可读性、结构和连贯性、语法准确性、指代明确、内容覆盖面、内容准确及聚焦程度、冗余度,分为5档,1=strongly disagree,2=disagree,3=neither,4=agree,5=strongly agree。
自动评估指标:准确、召回、F- Measure,ROUGE。
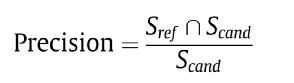
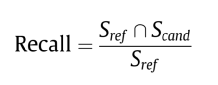

ROUGE-1(R1):基于unigram计算ROUGE(生成的token在ground truth中出现的比例);
ROUGE-L(R-L):基于最长公共字串计算ROUGE;
ROUGE-S*(R-S*):基于skip-bigram计算ROUGE;
ROUGE-SU(R-SU):同上,同时使用uni-gram作为计算单元;
6、未来研究方向
多文档摘要:解决跨文档摘要指代错误、冗余度高、连贯性不强的问题。
以用户为中心的文档摘要:包括多文档、多语言、多模态摘要,个性化摘要、有情感倾向的摘要等。
长文本摘要:新闻文档往往在上千个字左右,而小说篇幅往往超过上万字,对表征模型提出了更高的要求;
对抽象式生成模型、混合式模型的更高关注度;
挖掘更多语言学、统计学特征应用于文本摘要;
RNN用于摘要生成依赖大量标注数据,如何减轻对数据的依赖;
研究合适的摘要生成停止策略,保证在长度足够压缩的情况下有更好的信息表达能力;
更好的摘要自动化评估方式;



