

“
来也科技使用 MGR (MySQL Group Replication)作为私有部署时 MySQL 的高可用架构,一年多以来,服务众多用户,稳定性得到了极大的保障。
本文记录自内部分享,需要一定的 MySQL 基础。欢迎大家在评论区讨论、交流~
”

MGR 介绍
什么是MGR
为什么是MGR
MGR 的限制及特点
最少 3 个节点,最多 9 个节点 节点越多,容错性越强,但交互越多,可能会影响效率 存储引擎只能使用 InnoDB 表中必须带有主键 一次只能加入一个节点。如果一次性添加多个节点,可能能执行成功,也可能会报错 只支持 IPv4 网络 必须使用 row-base 格式的binlog MGR 模式下不支持过滤指定信息的操作
MGR 在来也科技的应用
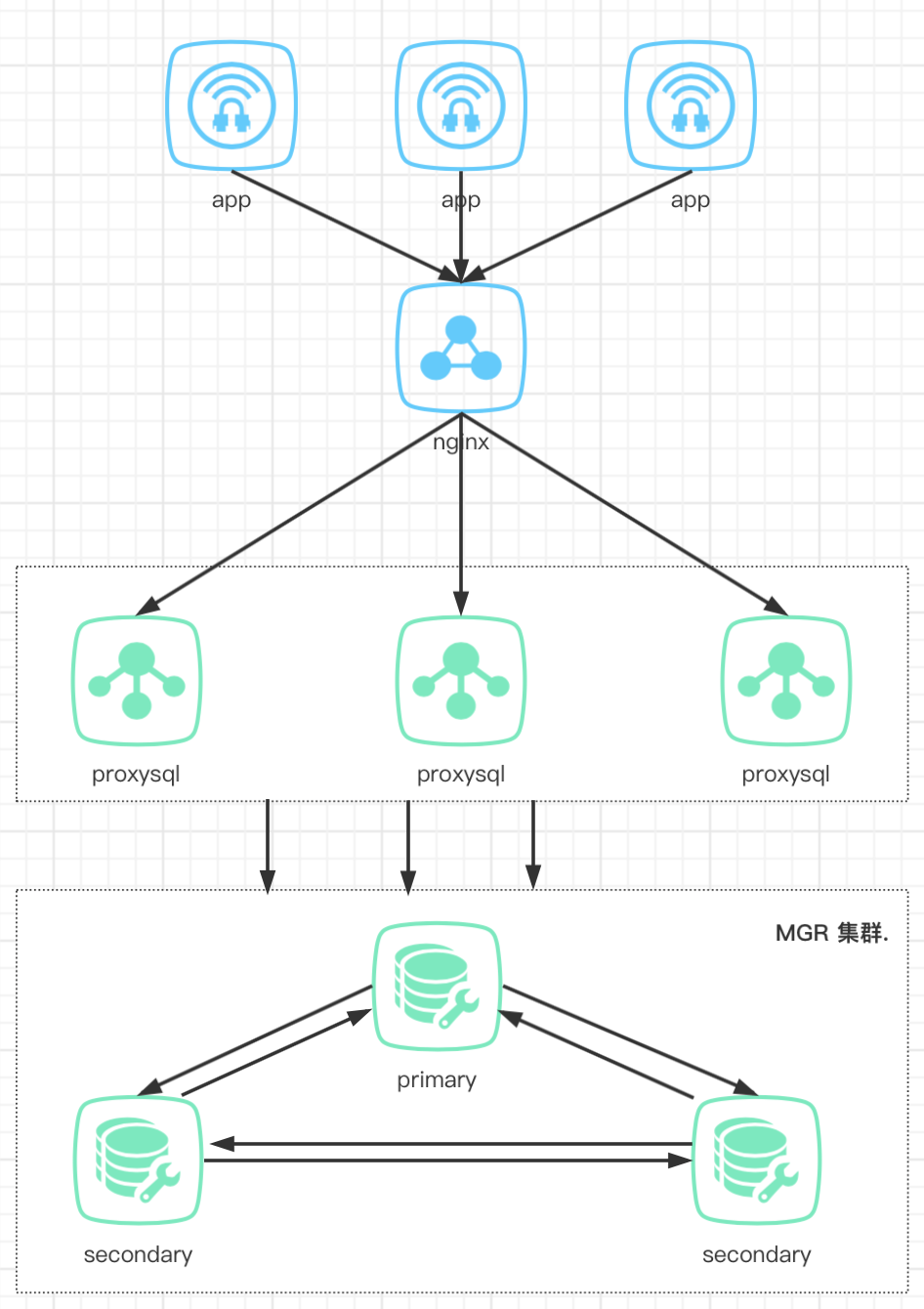
如果主库发生故障 -- 自动切换 如果从库发生故障 -- 将其下线
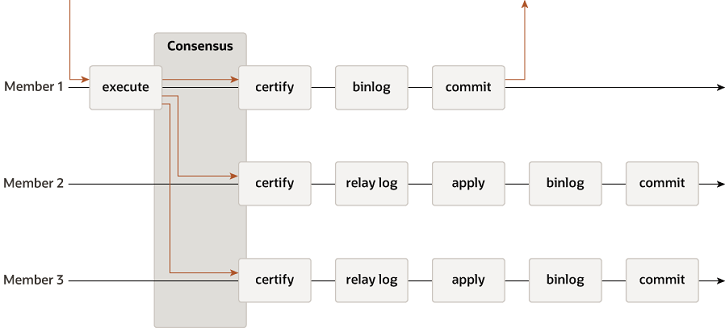
MGR架构和原理
primary 接受到请求后,想组所有成员同步请求,进行事务认证。事务认证包含 3 个部分: 冲突检测 gtid分配器 事务组提交信息分配器 如果检测失败 primary:回滚 secondary:丢弃 binlog event (冲突检测时带来的) 如果检测成功: primary :记 binlog, 分配 GTID secondary:将 binlog event (冲突检测时带来的)信息写入 relay log secondary 应用 relay log ,执行 sql ,并记录日志(通常情况下,我们建议将集群内所有 node 都配置在 seed 中,即:每个节点都可能成为 donor ,所以都要记 binlog)
本地恢复:应用自己本地 relay log 中的日志 全局恢复:从集群中活跃的节点中任选一个作为 donor,用 recovery 线程 dump 它的binlog,来恢复自己的数据
mysql> select * from replication_group_members;
+---------------------------+--------------------------------------+---------------+-------------+--------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | +---------------------------+--------------------------------------+---------------+-------------+--------------+ | group_replication_applier | 69bb0b63-1c3c-11ec-bc07-00163e011343 | 172.18.85.227 |3306 | ONLINE | | group_replication_applier | 732d940e-1c3c-11ec-b336-00163e016ec8 | 172.18.85.228 |3306 | ONLINE | | group_replication_applier | 7cac32d7-1c3c-11ec-b4e3-00163e018982 | 172.18.85.229 |3306 | ONLINE | +---------------------------+--------------------------------------+---------------+-------------+--------------+ 3 rows in set (0.03 sec)
mysqldump --set-gtid-purged=ON --single-transaction --all-databases -uroot -p -h 127.0.0.1 > mgr.sql
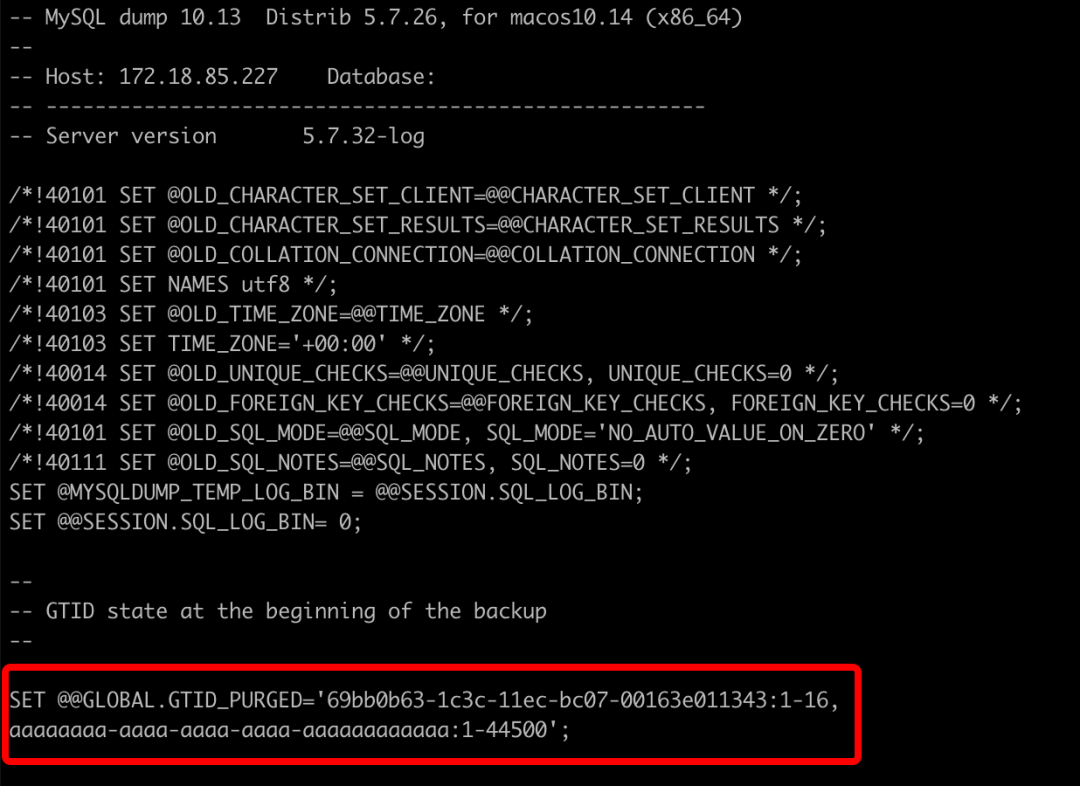
STOP GROUP_REPLICATION;reset master;
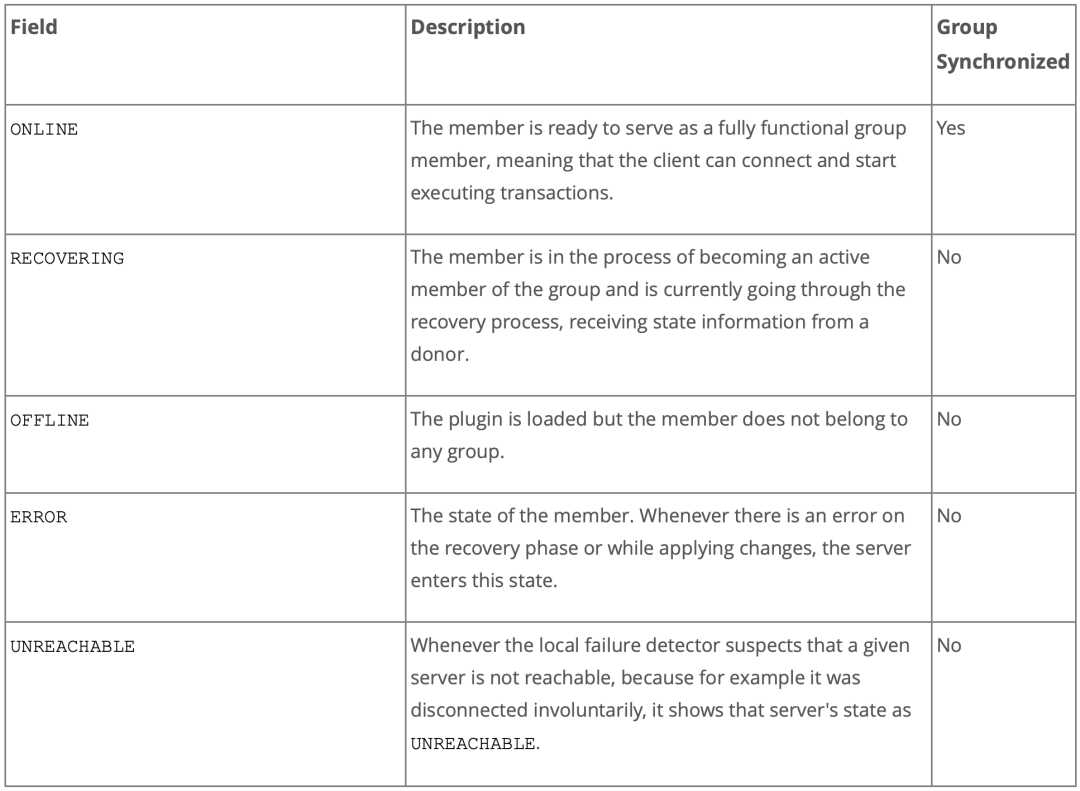
节点状态说明
组成员维护
成员的加入和退出需走 paxos 协议,由多数成员同意后方可执行成功 如果多数节点已经处于离线状态了,那么不可执行主动离组操作(投票会无法通过)。
主动离组: 只有执行 stop replication 命令才算主动离组 相当于总数变为 n-1 无论主动离组多少成员,都不会影响投票 被动离组: 因故障等原因导致意外下线 总数不变 影响投票 当有多数节点被动离组后,集群不可用
两个通道
mysql> select * from performance_schema.replication_connection_status\G*************************** 1. row *************************** CHANNEL_NAME: group_replication_applier GROUP_NAME: aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaaSOURCE_UUID: aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaaTHREAD_ID: NULLSERVICE_STATE: ONCOUNT_RECEIVED_HEARTBEATS: 0 LAST_HEARTBEAT_TIMESTAMP: 0000-00-00 00:00:00 RECEIVED_TRANSACTION_SET: 69bb0b63-1c3c-11ec-bc07-00163e011343:1-16,732d940e-1c3c-11ec-b336-00163e016ec8:1-6,7cac32d7-1c3c-11ec-b4e3-00163e018982:1-6,aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:1-89163LAST_ERROR_NUMBER: 0 LAST_ERROR_MESSAGE: LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00*************************** 2. row *************************** CHANNEL_NAME: group_replication_recovery GROUP_NAME:SOURCE_UUID:THREAD_ID: NULLSERVICE_STATE: OFFCOUNT_RECEIVED_HEARTBEATS: 0 LAST_HEARTBEAT_TIMESTAMP: 0000-00-00 00:00:00 RECEIVED_TRANSACTION_SET:LAST_ERROR_NUMBER: 0 LAST_ERROR_MESSAGE: LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:002 rows in set (0.04 sec)
性能调优
并行复制 压缩 调整 GCT
slave_preserve_commit_order=1 slave_parallel_type=LOGICAL_CLOCK
STOP GROUP_REPLICATION;SET GLOBALgroup_replication_compression_threshold = 2097152;START GROUP_REPLICATION;
超出这个指定范围,就不压缩了。官方文档中提示:当网络带宽成为瓶颈时,通过压缩消息,可以提高集群整体 30% - 40% 的性能。mysql> SET GLOBAL group_replication_poll_spin_loops= 10000;
GCT接收来自组和 MGR 插件的消息,处理与仲裁和故障检测相关的任务,发送一些保活的通讯消息,还处理 MySQLServer 与组之间传入和传出的事务。GCT 会等待队列中的传入消息。当队列中没有消息时,GCT将会进行等待。 在某些情况下,通过将这个等待配置得稍微长一些(进行主动等待),可以减少操作系统执行上下文切换时从处理器中换出GCT线程的次数。安全
控制节点白名单。设置 group_replication_ip_whitelist 参数,不再此范围的节点,不允许加入 配置 SSL:
new_member> SET GLOBAL group_replication_recovery_use_ssl=1;new_member> SET GLOBAL group_replication_recovery_ssl_ca= '.../cacert.pem';new_member> SET GLOBAL group_replication_recovery_ssl_cert= '.../client-cert.pem';new_member> SET GLOBAL group_replication_recovery_ssl_key= '.../client-key.pem';
其他注意事项
常见错误及其处理方法
查看集群状态
mysql> select * from performance_schema.replication_group_members;+---------------------------+--------------------------------------+---------------+-------------+--------------+| CHANNEL_NAME| MEMBER_ID| MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |+---------------------------+--------------------------------------+---------------+-------------+--------------+| group_replication_applier | 69bb0b63-1c3c-11ec-bc07-00163e011343 | 172.18.85.227 |3306 | ONLINE || group_replication_applier | 732d940e-1c3c-11ec-b336-00163e016ec8 | 172.18.85.228 |3306 | ONLINE || group_replication_applier | 7cac32d7-1c3c-11ec-b4e3-00163e018982 | 172.18.85.229 |3306 | ONLINE |+---------------------------+--------------------------------------+---------------+-------------+--------------+3 rows in set (0.07 sec)
确认是否存在可用集群
谁是主节点?
mysql> select MEMBER_HOST, MEMBER_PORT,MEMBER_STATE from performance_schema.replication_group_members m inner join performance_schema.global_status g on m.MEMBER_ID=g.VARIABLE_VALUEand VARIABLE_NAME = 'group_replication_primary_member';+---------------+-------------+--------------+| MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |+---------------+-------------+--------------+| 172.18.85.227 |3306 | ONLINE |+---------------+-------------+--------------+1 row in set (0.01 sec)
什么导致了故障?
mysql> show global variables like 'log_error';+---------------+--------------------------+| Variable_name | Value|+---------------+--------------------------+| log_error | /var/lib/mysql/error.log |+---------------+--------------------------+1 row in set (0.03 sec)
[ERROR] Plugin group_replication reported: 'For details please check performance_schema.replication_connection_status table and error log messages of Slave I/O for channel group_replication_recovery.'
mysql> select * from performance_schema.replication_connection_status where CHANNEL_NAME = 'group_replication_recovery'\G*************************** 1. row *************************** CHANNEL_NAME: group_replication_recoveryGROUP_NAME: SOURCE_UUID:THREAD_ID: NULLSERVICE_STATE: OFFCOUNT_RECEIVED_HEARTBEATS: 0 LAST_HEARTBEAT_TIMESTAMP: 0000-00-00 00:00:00 RECEIVED_TRANSACTION_SET:LAST_ERROR_NUMBER: 2005 LAST_ERROR_MESSAGE: error connecting to master 'repluser@pvt-commander-test:3306' - retry-time: 60retries: 1 LAST_ERROR_TIMESTAMP: 2020-06-05 17:26:502 rows in set (0.00 sec)
常见错误:[GCS]Connection attempt from IP address 192.168.9.208 refused
MySQL [performance_schema]> show global variables like 'group_replication_ip_whitelist';+--------------------------------+-----------+| Variable_name| Value |+--------------------------------+-----------+| group_replication_ip_whitelist | 0.0.0.0/0 |+--------------------------------+-----------+
常见错误:This member has more executed transactions than those present in the group.
有应用直连,往里写数据 有人误在从库上直接操作 错误的恢复手段:这个最为常见
查看哪些数据被错误应用,进行相应处理 找到最后同步的 GTID 位点 reset master 设置最后 gtid_purged 为要继续同步的 GTID 位点
常见错误:Member was expelled from the group due to network failures, changing member status to ERROR
常见错误:the master has purged binary logs containing GTIDs that the slave requires
查询没有主键的表
select TABLE_SCHEMA, TABLE_NAME from information_schema.tables where TABLE_SCHEMA not in ('information_schema','mysql', 'performance_schema', 'test', 'sys') andTABLE_NAME not in (selecttable_name from information_schema.TABLE_CONSTRAINTSwhere TABLE_SCHEMA not in ('information_schema','mysql', 'performance_schema', 'test', 'sys') and CONSTRAINT_TYPE = 'PRIMARY KEY');查询所有不是 InnoDB 引擎的表
select TABLE_SCHEMA, TABLE_NAME from information_schema.tables where TABLE_SCHEMA not in ('information_schema','mysql', 'performance_schema', 'test', 'sys')and engine <> 'InnoDB';






