“
深度学习可以对物理世界的人/物/场景所产生各种非结构化数据(如语音、图片、视频,语言文字、行为等)进行抽象,变成多维的表示向量。
物理世界的关系可以通过表示向量的距离数学运算得到。

“中国首都占地16410.54平方千米” “北京面积16410.54平方千米” “北京面积多少平方千米”
[“中国”,“首都”,“占地”,“16410.54”,“平方千米”] [“北京”,“面积”,“16410.54”,“平方千米”] [“北京”,“面积”,“多少”,“平方千米”]
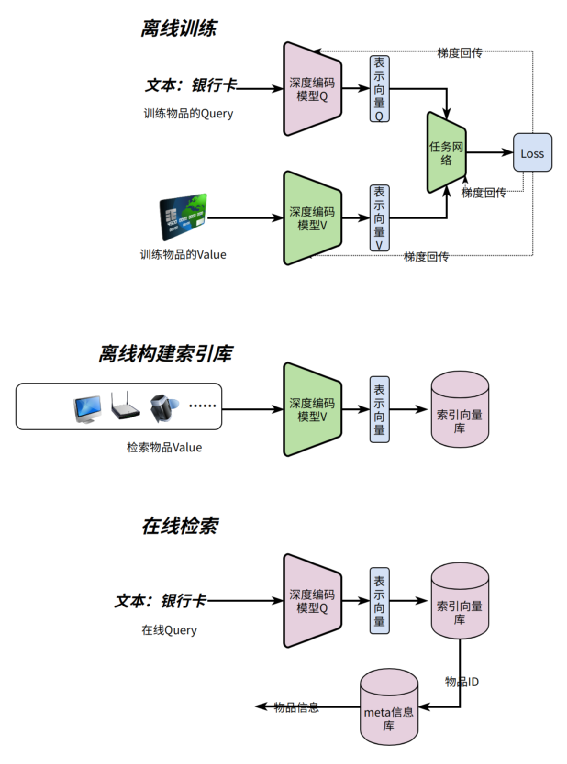
离线训练阶段:主要是训练深度编码模型 离线构建索引库:主要是用训练好的深度编码模型,对所有物品进行编码后保存到向量索引库 在线查询:将Query通过深度编码模型得到编码向量,取编码向量与索引向量库中距离最近的向量对应的物品ID,再通过物品ID去物品Meta库查询业务需要的Meta信息
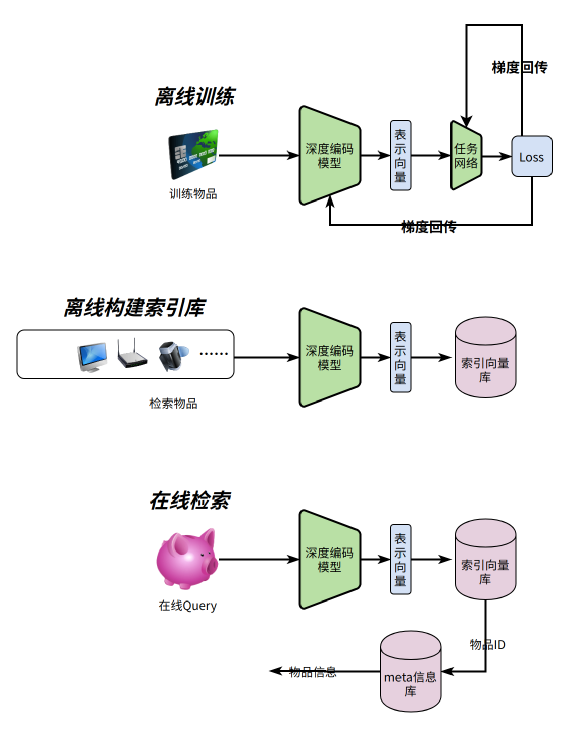
对训练数据中的Query和Value采用两个不同的深度编码模型MQ和MV 离线构建索引时,采用深度模型MV编码所有需要被召回物品 在线查询时,Query采用深度模型MQ编码
局部敏感性哈希(LSH) 基于近邻图 基于乘积量化
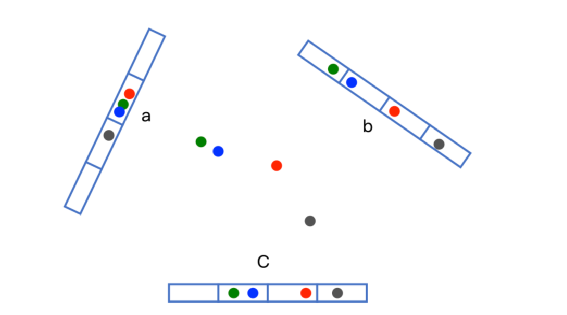
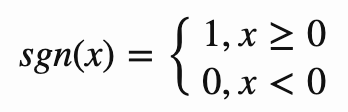
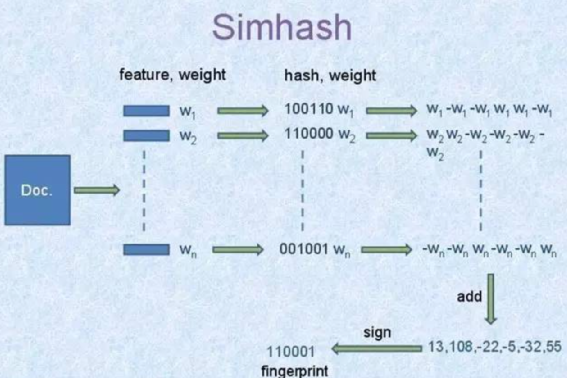
首先对原始的数据提前关键特征和特征对应的权重,在网页中特征就是关键词,权重就是tf-idf; 利用一个签名函数对一个原始数据的所有特征计算,得到二进制签名,这个签名函数就是一个普通的hash函数,比如crc16; 所有的特征签名逐位求差或和,若签名位是0则减去这个特征的权重,当签名位是1则加上这个特征的权重,最终得到一个和签名位数一样的一维向量; 将上步得到的向量转化为二进制,若向量某一维大于0,则最终二进制对应的bit为1,小于0对应的比特位为0
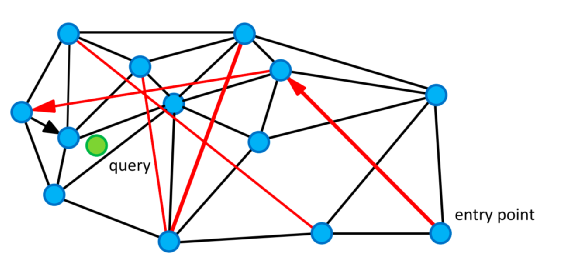
short-link。用于搜索最近向量 long-link。在搜索初期提高搜索效率
每次在图中插入节点v都寻找k个最近的节点x,让v和x之间产生边 插入时产生的边为为short-link 随着新的距离更近的节点逐渐加入,可能以前的short-link不再是距离最近的k个,这个时候short-link变成了long-link
在图上随机选一个节点加入C 计算C中所有节点与q的距离,假设距离最近的点为c(小写),距离为d,若d大于R中的最大距离(这个c称为局部最小点)或者C为空,则查询结束 从C中弹出c并将c加入V 令c的所有不在V的邻居节点集合为E, 将E中和q距离小于d的节点加入C和R,若R中元素已满,弹出R中距离最大的元素 循环2~5
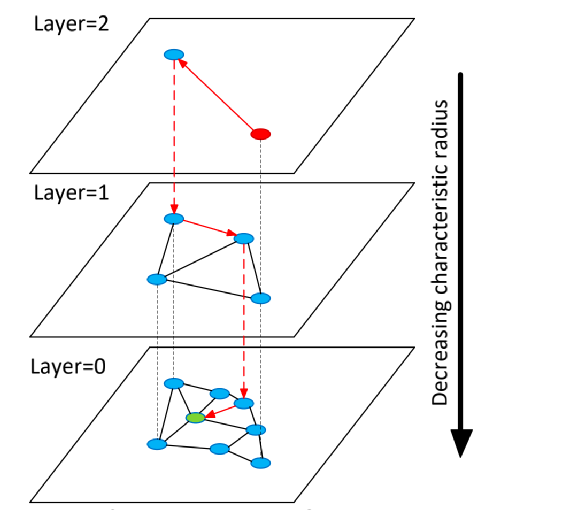
根据概率选择一个当前节点要插入的最大层数,层数越高插入概率越低,假设HNSW的最大层是5,当前的要插入的最大层是3,那么这个节点会被插入0,1,2,3层(4,5层不插入); 从高层开始逐级向下搜索,在每一层找到距离最近的k个节点与插入节点建立边,每一层的搜索算法和NSW一样 对每一个节点,有一个最大边数emax,若进行步骤2后,旧的节点边超过emax,则删掉距离最大的边 搜索过程如下: 从最高层5开始 每一层通过NSW算法找到近邻点 下一层的开始搜索节点则为上一层搜索的近邻点
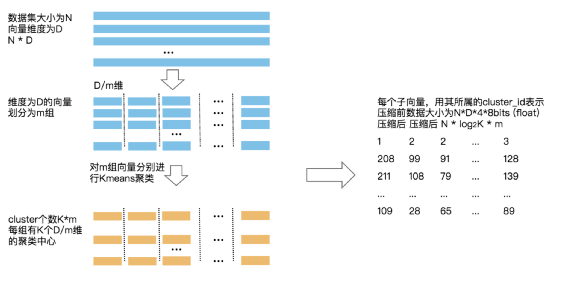
选定一个向量分段数K,假设为10,那么每一段的维度就为1280/10=128 对原始的N个向量每128位分为一组,那么一共有10组,每组有N个向量 对10组的向量分别进行聚类,假设聚类的个数是256个,每个类的中心称为积中心,对每一组的积中心打上依次打上编号0~255 对于一个向量每一段128维来说,和这组的那个积中心距离最近,就把这段用这个积中心编号表示,这样原始每个向量就被表示为一个10位的向量,每位取值0~255
将这个查询向量通过上边的分段算法转成10端128维向量 每一段和这个段的256个积中心算出距离,会得到一个10*256的矩阵M 对于索引库的一个向量v,假设其量化向量为[255,1,210,……](10个元素)对于第i个元素值为j,可以认为第i段与q的距离为Mij(ij为矩阵M索引),比如对于第一个元素255可以认为距离是M的第0行第255列的值 将10个段经过步骤3查询的10个距离求和得到s,可以认为s是v到q的距离,从所有的向量距离中找出距离最近的k为查询结果
预先对这N个向量聚类(原始向量上聚类),假设聚类数量为1000,那么每一个向量会归入自己所在的这个类 对每一聚类的向量进行PQ量化 在线查询来了先和每一类的中心比较,挑选距离较近的m个类,m至少为1,m越大速度越慢但是召回越高 从这个m个类中进行上边PQ查询
首先要对原始向量进行聚类,没法做到从0开始插入数据 聚类后加入的向量若发生离群(离任何类中心都较远或者距离差不多),那么这些向量的召回会很低 量化因为主要原理是通过聚类将考得近的向量降维,所以如果原始向量分布很均匀,那么聚类效果很差所以最终的召回率很低