

RPA(机器人流程自动化)将原本需要人工重复执行的软件操作交给机器人执行,能够极大地帮助企业降低成本、提升效率,成为推动企业数字化转型的利器。
但是,传统RPA只能实现基于规则的流程自动化,应用场景相对受限。借助AI之后,RPA机器人则能具备感知和认知能力,将自动化拓展到更复杂的业务流程,产生更大的价值。
不过,RPA+AI,这听起来十分美好,但在实际场景中又该如何落地?
本文会从技术角度对RPA和AI进行分析,并结合来也科技在RPA+AI方面的实践,谈谈如何破局,并对未来进行展望。
两种软件开发范式
本质上来讲,RPA和AI属于两种截然不同的软件开发范式。
01 RPA是基于规则的软件开发范式,每一行代码都对应真实场景中的业务逻辑。因此,开发RPA机器人前,首先要梳理清楚业务流程,然后根据业务流程去编写代码。
02 AI则是一种全新的软件开发范式。在这种范式下,开发者不再需要用代码去编写规则,而是用代码编写机器学习模型,然后用数据来训练这个模型,最后软件基于模型的输出去完成特定的任务。
简单的说,RPA开发是给机器明确的指令每一步该做什么,AI开发是教机器过去是怎么做的,让机器去学习并举一反三。
开发范式的不同会带来一系列的后果,这导致RPA+AI在实际落地中遇到巨大挑战。
第一,RPA和AI对开发人员的要求不同。RPA的特点是非侵入、低代码,让不懂编程的业务人员也能开发流程。而AI模型的训练则有较高的门槛,通常需要专业的数据科学家或算法工程师才能完成。由于这类人才的稀缺,导致RPA+AI的落地变得很难。
第二,AI的开发周期要比RPA长。RPA强调的是快速落地、快速见效,而AI模型的训练要经过数据获取、数据标注、模型训练、模型部署、模型持续优化等流程。这意味着RPA+AI项目的落地周期会大大加长。
第三,AI的使用成本比RPA高。RPA是客户端程序,只要计算机的软硬件配置和系统环境满足基本要求,即可运行。AI基于深度神经网络,对计算、存储、网络等都要较高的要求,通常需要运行在GPU服务器上,部署和运维成本不小,这使得RPA+AI项目的前期投入大。
以上几点,都导致RPA+AI在实际业务中的落地并没有想象中的容易。
如何破局
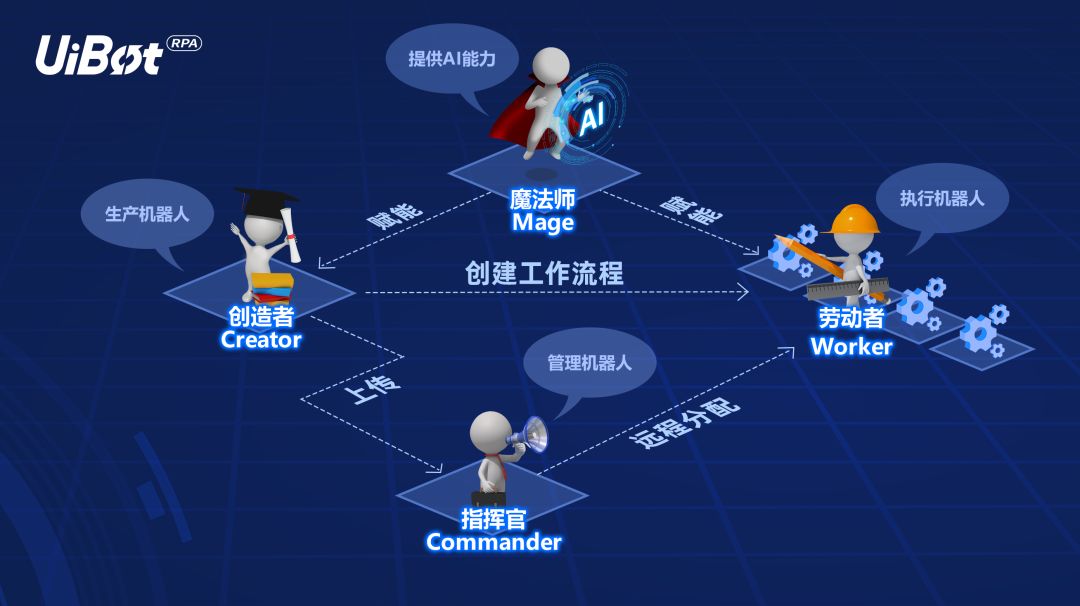
不久前,来也科技发布了全新的RPA+AI平台产品——UiBot Mage,这是专为RPA机器人打造的AI能力平台,以拓宽RPA的使用边界。
UiBot Mage上线后,将与UiBot家族原有的Creator(创造者)、Worker(劳动者)、Commander(指挥官)三大模块集结,分别为RPA机器人生产、执行、分配、智能化提供相应的工具和平台。
提供开箱即用的AI能力
既然AI模型依赖数据和训练,第一种破局的思路就是提前把模型训练好供RPA使用。这个方案的前提是,我们要知道RPA需要什么样的AI能力。
为此,来也科技深入分析了几十个业务场景中的几百个业务流程,从中梳理出RPA最需要的AI能力。我们发现,在RPA流程中,最能够用到AI能力的地方,是对各种非结构化数据的处理。在这些场景中,RPA可以利用文字识别、文本理解等AI能力将非结构化数据进行结构化。
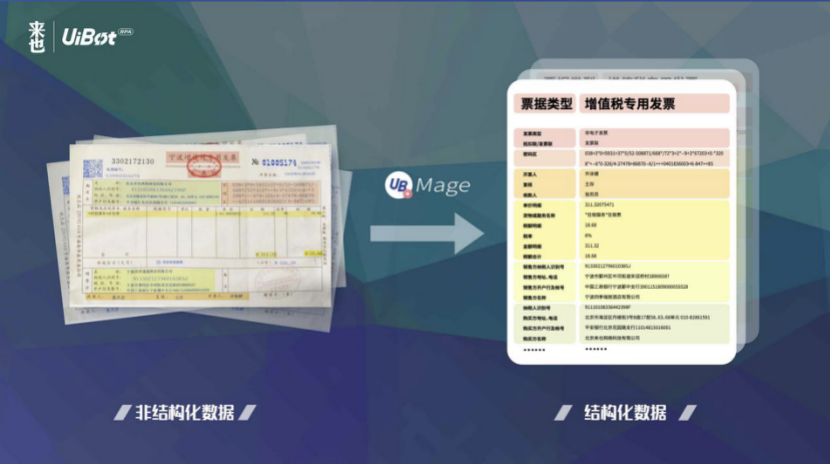
文字识别即我们常说的OCR,它可以应用于文档识别、表格识别、票据识别、卡证识别等垂直场景。UiBot Mage针对每个场景提供若干个开箱即用的模型。例如,票据识别场景下开箱即用的模型覆盖了增值税专用发票、增值税普通发票、行程单、火车票等20多种票据类型,在卡证识别场景则包括了银行卡、身份证、护照、营业执照等20多种模型。
此外,UiBot Mage在文本理解方面也提供一系列开箱即用的模型。以信息抽取为例,我们提供的模型支持几十种常见的实体抽取,包括企业名称、日期、时间、金额、地址、电话等,能够应对大多数业务中的信息抽取需求。
以上AI能力的开箱即用还体现在与Creator的无缝集成上。所有AI能力都以自定义命令的形式存在于Creator中,开发者只需通过拖拽和简单设置就可在RPA流程中使用AI能力。这样,没有任何AI经验的RPA工程师甚至业务人员,都可以享受到AI给RPA带来的价值。
通过提供开箱即用的AI能力,UiBot Mage可覆盖到RPA中常见的需要AI能力的场景。但是,对于长尾的、非标准化的场景,开箱即用的模型无法满足用户的需求,因此我们需要有新的解决方案。
通过预训练降低训练成本
2018年底,Google推出BERT,其核心原理是,用海量数据预先训练一个基于深度神经网络的语言模型,然后针对特定NLP任务在原网络的基础上再次训练得到一个模型(此过程被称为Fine-tune),其效果在几乎所有NLP任务上都明显优于当时最好的模型。
这个方法叫做预训练(Pre-training),它给我们的最大启示在于不同的机器学习任务其底层有相通之处,我们可以用大量任务无关的数据(大数据)事先训练好一个模型,等到要解决特定任务时,只需要用少量任务相关的数据(小数据)对模型进行微调,即可达到理想的效果。这种方法对训练数据量的要求更少,数据标注成本更低,训练时间也更快,最为关键的是,在预训练基础上训练的模型比没有预训练的模型效果要好。
回到RPA+AI场景,前面提到的OCR任务虽然使用不同的模型,其底层确有相通之处。比如,虽然针对不同类型文档有不同的OCR模型,但我们都可以将其拆分为其字符检测和字符识别两部分。因此,我们可以通过大量数据预训练得到检测和识别的基础模型,然后在特定任务上进行Fine-tune,这样便能在保障模型效果的前提下,大大减少对训练数据的要求,并降低了模型的训练成本。
对于NLP任务,预训练同样能给我们带来明显的收益。前面提到的BERT,属于预训练的语言模型,除此之外,我们还可以对词的表示、句子的表示、篇章的表示等模型进行预训练。
未来展望
UiBot Mage通过提供开箱即用的模型、预训练等手段来加速RPA+AI的落地,但RPA+AI今天仍然在发展早期,未来还有很长的路要走。
对于RPA+AI的未来发展,以下几个方向值得我们持续关注和不断创新。
前面提到,基于深度学习的AI模型对于硬件有较高的要求,其部署过程也比RPA要复杂很多,这无疑增加了RPA+AI的落地门槛。未来,软硬件一体的RPA+AI产品或许能够有效解决这一问题,用户不用担心硬件的选型、部署和维护,让RPA+AI真正做到“开箱即用”。
此外,边缘计算能力的提升和普及,使得AI的推理可以从服务端转移到客户端。由于RPA是运行在客户端的软件,相比基于服务端的RPA+AI方案,基于边缘计算的RPA+AI方案在架构上更加简单、灵活,其成本也将大幅下降。边缘计算的RPA+AI方案将让我们真正实现“人人都有一个机器人”。
最后,一个好的AI系统需要“活”的数据来持续更新模型适应环境变化。因此,在RPA+AI中如何高效的实现人机协同,形成数据闭环,是一个未来值得研究的重要课题。







