

智能文档处理(Intelligent Document Processing,简称 IDP)是来也科技智能自动化平台的核心能力之一。IDP 基于光学字符识别(OCR)、计算机视觉(CV)、自然语言处理(NLP)、知识图谱(KG)等前沿技术,对各类文档进行识别、分类、抽取、校验等处理,帮助企业实现文档处理工作的智能化和自动化。
本文介绍 IDP 的一个典型应用场景,即利用文档智能问答赋能电网设备管理作业。对 IDP 产品及更多应用场景感兴趣的读者,可点击文章开头的话题“#智能文档处理”。
背景
电网设备技术标准文档包含了各种设备的参数标准、技术条件、操作规范等内容,是电网员工对设备进行管理作业的基础。电网员工在展开设备运维检修作业时,须严格按照技术标准中的流程规范开展作业,存在大量设备技术标准的检索和问答需求。设备技术标准文档数量庞大,文档内容非常专业和复杂,包含大量专业术语和表格。由于这些原因,员工对于设备技术标准文档的使用效率和质量都不高。
来也科技的智能文档处理产品基于自然语言处理(NLP)、知识图谱(KG)等技术,对技术标准文档内容进行加工和提炼,让业务人员通过问答的方式快速从文档中获取相应的答案,大大提升设备管理作业的效率和质量,减轻基层工作人员的负担。
问题分析与建模
在构建智能问答系统之前,我们首先要对问题进行分析和建模。因为智能问答系统是基于机器学习模型的,一个智能问答系统能够回答什么问题,取决于该系统所使用的训练数据。根据电网设备技术标准文档内容的特点,员工的问题可以通过三大类问答引擎融合解决,这三类引擎分别对应三类不同的训练数据。
FAQ
FAQ(Frequently Asked Questions)是最常见的一类训练数据。它通常由领域专家梳理,对高频问题及答案统一进行整理和维护。基于此训练的智能问答系统,能够判断用户的问题是否命中这些高频问题,并给出相应的答案。但是,因为 FAQ 的数量有限,系统无法回答 FAQ 覆盖范围之外的问题。下图是一个常见问答对的示例。在这个例子中,当用户询问“是什么”、“有哪些”、“是多少”、“能否”等类似问题时,系统会直接给出一个精准的回答。

知识图谱
电网设备技术标准中涉及到大量设备相关的参数、指标等,这些信息通常以非结构化的方式包含在文本或表格中,适合以知识图谱这种结构化的方式进行表示。知识图谱由三元组构成,三元组的内容既可以是(实体1,关系,实体2)这种形式,代表两个实体之间的关系,也可以是(实体、属性,属性值)这种形式,代表某个实体的某个属性。我们使用 IDP 技术从文档中抽取信息来构建知识图谱,然后训练智能问答系统。知识图谱的规模通常比 FAQ 要大很多,因此基于知识图谱的智能问答系统能够回答的问题覆盖面更广。下图是一个知识图谱的示例。在这个例子中,当用户询问“户外配电箱的装置门开合角度应该具备什么技术条件?”或类似问题时,系统会给出一个精准的回答如“不小于100°”。

文档片段
我们观察到,在电网设备技术标准的智能问答场景中,答案一定来自于文档。具体而言,答案要么直接就是文档的某个片段,或者可以通过对文档进行提炼、归纳得到。因此,文档本身就可以作为智能问答系统最主要的训练数据。这种情况下,我们可以使用机器阅读理解(Machine Reading Comprehension,简称MRC)技术来实现基于文档片段的智能问答。下图是一个具体的示例。该例子中,用户的问题是“新投运的 220kV 变压器,施加电压前静置时间应该不少于多少小时?”,问题的答案包含在文档片段中,模型能从该文档片段中准确的抽取出问题的答案“48小时”。如果我们把所有文档片段都用于该系统,则能大大提升系统对问题的覆盖率。当然,它的准确性和基于 FAQ、基于知识图谱的方法相比会低一些。

在实践中,我们需要将上述三类方法结合起来:基于 FAQ 的方法覆盖高频问题,基于文档抽取的方法则覆盖长尾问题,基于知识图谱的方法基于二者之间。如下图所示。

技术架构
在问题分析和建模的基础上,我们设计文档智能问答的整体技术架构,一共分为三层,如下图所示。
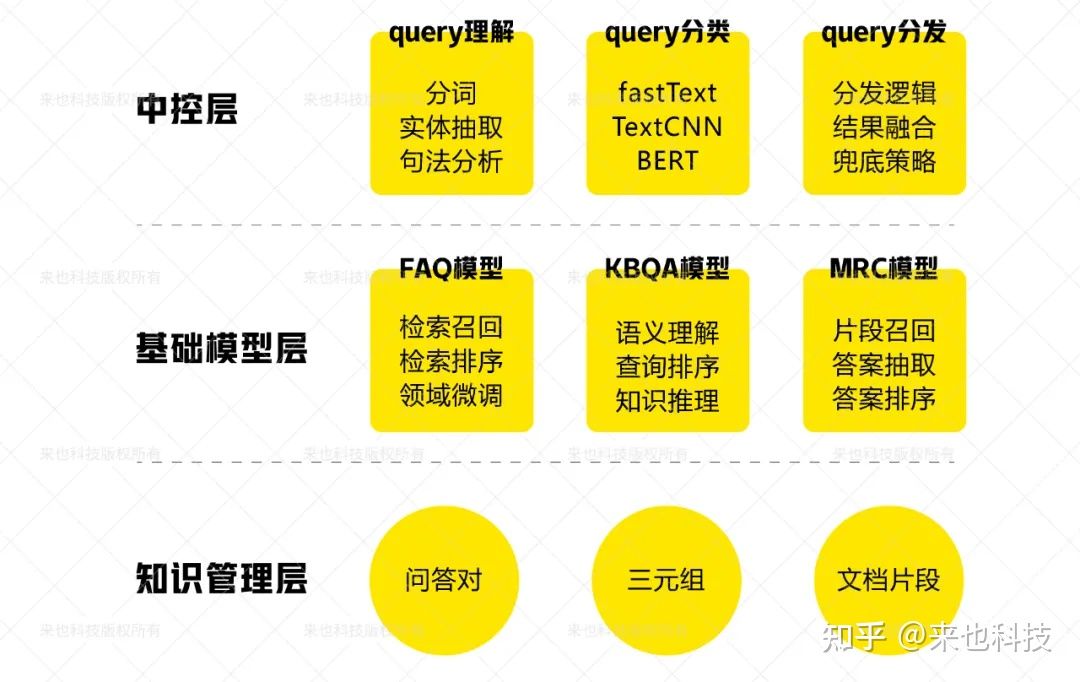
知识管理层
知识管理层位于整体架构的最底部,用于管理和维护训练智能问答系统所需的知识。具体而言,知识管理层主要对上一节中所描述的三类训练数据进行维护,它们分别是:
问答对:包含若干组由业务专家梳理、来自于文档的问答对。针对每个问答对里的问题,专家还可以撰写若干个相似问题,以提高模型的语义泛化能力。
三元组:包含若干组由机器挖掘、业务专家审核的三元组格式的知识图谱。三元组的内容既可以是(实体1,关系,实体2),也可以是(实体、属性,属性值)。
文档片段:包含若干组由文档片段、问题、答案组成的数据,其中问题是针对文档片段的,答案则来自文档片段中。同一个文档片段,可以有多组问题和答案。
基础模型层
在知识管理层之上,则是基于各种类型数据训练出来的基础模型,这些模型通过组合的形式,构成相对完善的问答引擎,对不同类型的问题进行智能问答。具体内容如下。
FAQ 模型
检索召回:基于用户问题,通过传统检索、语义检索等方法,从FAQ库中召回候选的问答对。
检索排序:基于语义相似度等特征,利用机器学习或深度学习模型计算用户 query 和召回的相似问之间的语义相似度。
领域微调:基于领域内数据,对精排后的问答对进行打分微调,最终输出结果。
KBQA 模型
语义理解:利用机器学习或深度学习模型对用户 query 进行理解,将其转化为若干组候选的知识图谱查询表达式。
查询排序:对若干组知识图谱查询表达式进行打分和排序。
知识推理:对知识图谱查询结果进行融合与推理。
MRC 模型
片段召回:基于用户问题,通过检索、深度学习等方法,从文档库中召回可能包含答案的文章片段。
答案抽取:从文章片段中抽取出候选的答案。
答案排序:对答案进行打分和排序,最终输出结果。
中控层
模型层之上是中控层。中控层的主要作用是对用户 query 进行处理,主要包括 query 理解、query 分类、query 分发三部分。
query 理解:包括分词、实体抽取、属性解析等基础模块,对 query进行分析。
query 分类:使用 fastText、TextCNN、BERT 等模型对 query 的类型进行判断。
query 分发:因为模型层提供了多种模型来得到答案,我们需要对 query 进行分发,并对不同模型返回的结果进行融合,最终得到一个结果。
本文介绍了文档智能问答在电网设备作业场景中的应用。通过对技术标准文档进行知识提炼和加工,并结合自然语言处理(NLP)、知识图谱(KG)等技术,智能问答系统能够满足业务人员对于文档检索和问答的需求,提升设备管理作业的效率和质量,减轻基层工作人员的负担。该解决方案同样也适用于其他需要对大量文档进行检索和查询的场景,可广泛应用于电力、能源、制造、医药等行业。








