污渍干扰如红章、墨迹
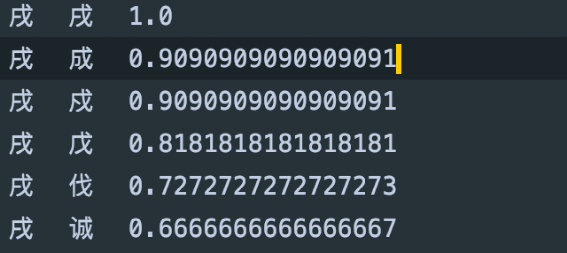
形似字 如 “戍”与“戌、成、戊”
图像变形引起的字体变形


在OCR解码过程加入语义信息、典型如百度的SRN【1】,用CNN提取的图像特征进行解码时融入字符的语义信息,保证解码的时不光用了图像特征,还和前一个字符做了语义对齐。
加入预测语义信息的多任务。一般做法是在图片上通过马赛克视觉随机遮挡字符,最终有两个Head网络,一路是预测图片上的字符,一路是预测遮挡的字符,这样的模型就会学到基于语义的纠错信息。
第三种一般是将纠错作为一个和OCR识别不耦合的后处理模块。
在我们合成的大量图片样本中,为了让一些长尾字符如生僻字出现足够多的次数,我们增加包含生僻字的随机文本;为了让模型区分一些形似字故意让多个形似字出现在一个图片,所以合成图片上的文字缺乏语义连贯性。
真实的样本标注中为了减少成本,我们不标注单字位置,这样没法在真实样本上位置准确的 Mask 一个字符,所以第二种做法也不成立。
替换 SubStitution:
今天我感到飞长高兴 -> 今天我感到非常高兴
增补与删除 Insert & Delete
今天我感到常高兴 -> 今天我感到非常高兴
今天我感到非非常高兴 -> 今天我感到非常高兴
改写 Local Paraphrasing (极小限度)
序列任务如机器翻译。简单来说就是将有错字的句子翻译成准确句子
检测错误加纠正。简单来说检测句子中可能发生错误的字,如检测到错字的话,预测这个错字对应的真值
错误字检测
纠正字召回
纠正字排序
为了减小模型,我们只采用最常见的3900个汉字字符;
为了提高模型准确率,将语料中数字、英文字符、标点、汉字中如量词千、百等语义通用性很强的字符替换为OOV的字符
交叉熵Loss由两部分组成,一部分是整句话所有预测字符的交叉熵Loss,一部分是Mask掉字符的交叉熵Loss,因为在最终的使用上更关注第二部分,所以第二部分Loss权重会更高。
在Loss计算过程中需要将OOV字符预测的Loss Mask掉 并将剩余Loss根据有效字符数等比缩放,主要是避免有效字符越少的Loss越低,具体代码可以参考我们以前的一篇博客【6】