



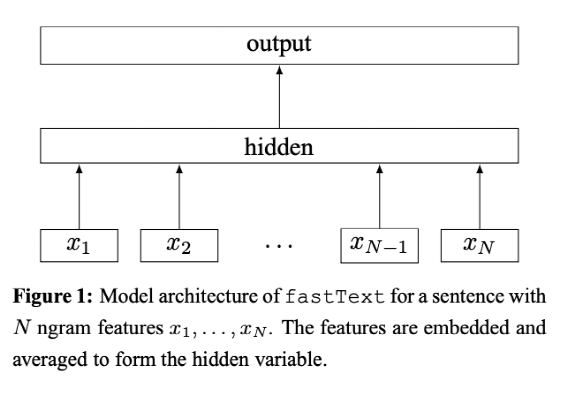
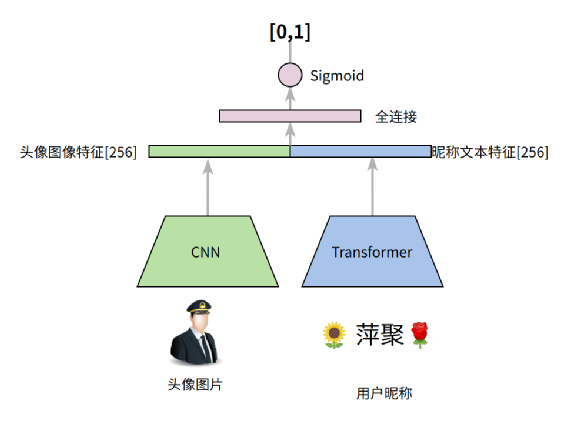
头像图像经过 CNN 抽取得到图像特征 昵称文本数据经过 transformer encoder 得到文本特征 文本特征和图像特征进行concat进行全连接得到预测结果
有 80 条数据无法通过头像和昵称区别性别。如下三张图片昵称分别为:青春永驻、春夏秋冬、随缘:

存在偏中性的图像或昵称。比如图像偏中性,但是可以通过昵称区分性别。如以下两张头像的昵称分别为:X小宝、X国强。能比较容易猜测后者为男性。
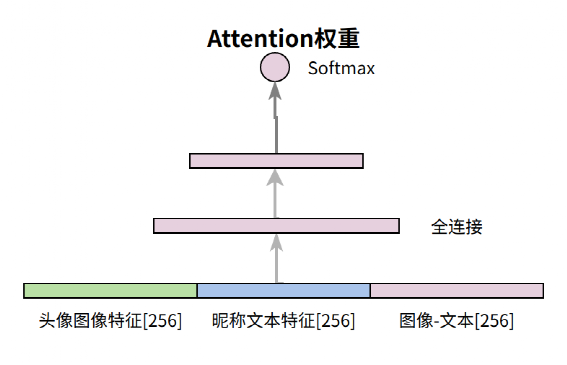
def _attention(self, img_feature, name_semantics):features = [img_feature, name_semantics, img_feature - name_semantics]features = tf.concat(features, axis=-1)f = self.att_dense1(features)weight = self.att_dense2(f)weight = tf.reshape(weight, [-1, 1, 2])concat_feature = tf.concat([img_feature, name_semantics], axis=-1)feature = tf.reshape(concat_feature, [-1, 2, self.feature_norm_dim])self.log.info("concat feature shape is (%s)", feature.shape)feature = tf.matmul(weight, feature)self.log.info("after attention feature shape is (%s)", feature.shape)feature = tf.reshape(feature, [-1, self.feature_norm_dim])return feature
'''将sigmoid低于阈值的idx mask掉eg:threshold=0.8 需要将prob>0.8 和prob<0.2 的保留probs=[0.81,0.7,0.4,0.19,0.3,0.7]的得到mask=[1,0,0,1,0,0]'''def get_mask(self, probs, threshold):probs = tf.reshape(probs, [-1])mask1 = tf.math.less(probs, 1 - threshold)mask2 = tf.math.greater(probs, threshold)return tf.math.logical_or(mask1, mask2)def mask_loss(self, loss, probs):mask = self.get_mask(probs, self.mask_loss_thres)mask = tf.cast(mask, loss.dtype)recall = tf.reduce_mean(mask)loss = loss * mask'''扔掉了一部分数据的loss,所以需要将剩下的loss放大防止模型将结果全部预测到这个区间'''loss = tf.math.divide_no_nan(loss, recall)return loss
class GCAdaW(tfa.optimizers.AdamW):def get_gradients(self, loss, params):grads = []gradients = super().get_gradients()for grad in gradients:grad_len = len(grad.shape)if grad_len > 1:axis = list(range(grad_len - 1))grad -= tf.reduce_mean(grad, axis=axis, keep_dims=True)grads.append(grad)return grads
https://arxiv.org/pdf/1607.01759.pdf
https://arxiv.org/pdf/1607.01759.pdf
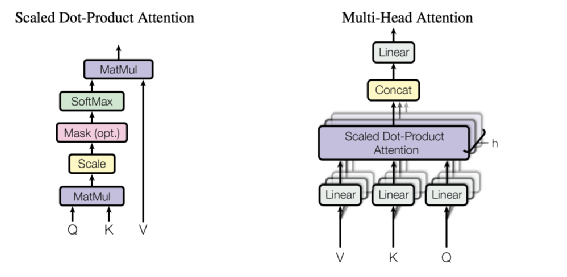
https://arxiv.org/pdf/1706.03762.pdf
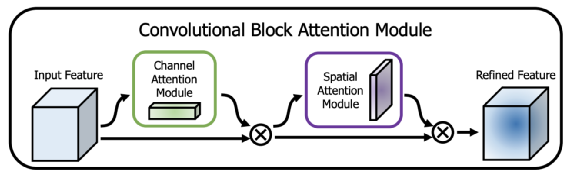
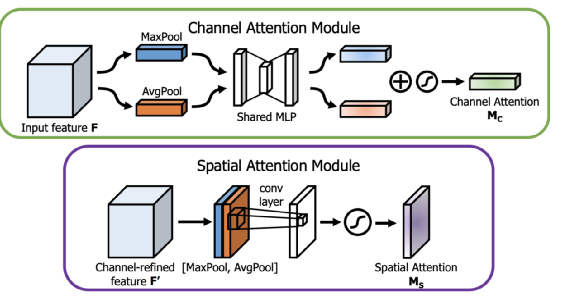
https://arxiv.org/pdf/1807.06521.pdf
https://arxiv.org/pdf/2004.01461.pdf
https://arxiv.org/pdf/1711.05101.pdf
https://arxiv.org/pdf/1801.04381.pdf







