

小来说:
“来也科技是一家业务涉及ToB和ToC领域的智能自动化公司,ToB业务是我们的战略重点,企业服务的本质在于了解客户的真实业务诉求,并为其提供优质的产品与服务,帮助其走出复杂商业环境中的发展困境。BI为了解用户、优化产品提供了参考。
来也科技的产品除了提供在线SaaS服务外还支持客户本地化部署,所以我们BI系统的技术选型也会考虑两种情况,本文对这部分内容亦有所涉及。”

本文将从以下7个大方向,16个小方向全面解读来也科技的BI生态:
1 背景介绍
1.1 BI定义
1.2 来也科技BI应用的发展阶段
1.3 探索数据驱动之路
2 数据接入
2.1 数据埋点
2.2 数据采集
2.3 数据抽取
3 数据传输转换与加载
3.1 数据传输
3.2 数据转换
3.3 数据加载
4 数据建模与存储
4.1 数据仓库
4.2 数据分层
5 数据统计与分析
5.1 预定义指标生成
5.2 即席查询(Ad Hoc)支持
5.3 实时指标支持
6 数据反馈与可视化
6.1 SaaS产品中的指标体系
6.2 基于数据仓库的BI系统
6.3 基于行为事件的多维用户分析系统
7 总结与展望
背景介绍
BI定义
在开始讨论BI应用之前,有必要对BI(商业智能: Business Intelligence)的概念做一个界定。国内外的工业界和学术界对于BI的定义一直在不断发展与变化,且没有形成公认的表述。本文引用帆软数据智能应用研究院2020年9月发布的《商业智能(BI)白皮书2.0》中的表述:BI 是一种解决方案,它以辅助决策为目的,通过相关的数据技术方法来处理企业各类数据,产出可量化的、可持续的数据价值,这些价值表现在帮助企业实现业务监测、业务洞察、业务优化、决策优化甚至数据盈利。
来也科技BI应用的发展阶段
发展初期
在企业产品成型初期,团队规模较小,业务量不大,对于数据指标的需求即不强烈也不明确。数据落地形式主要以SaaS产品功能和管理后台功能为主。数据需求的来源集中在项目反馈及产品经理个人判断。
当需求产生以后需要经过如下流程将指标落地:产品经理提前1-2个迭代发起评审,然后开发之间商定日志格式,业务开发同学记录日志,数据开发同学收集日志,再通过编写复杂的计算过程产出所需指标,最后由 gRPC 接口将数据提供给业务使用。
运维团队则采取一个需求一个定时任务的策略。在发展初期这种模式勉强可以支撑,但是随着团队规模和业务量的不断增长,这种方式显得捉襟见肘,主要问题如下:
l指标产出周期长:一个指标从提出到最终与用户见面大约需要一个月甚至更长的时间,这种效率在激烈竞争的市场中显然没有优势可言。
l代码混乱、维护困难:当某一指标需要升级时,面对长长的定时任务列表和众多的入口函数,工程师既不确定要改哪些代码又不知道要变哪个任务。定时任务往往是上马容易下马难。
l指标混乱、口径不统一:几乎每个指标的起点都是原始日志,由于不同的理解和未知的Bug,往往出现不一致的指标,类似召回率大于100%的情况时有发生,导致用户无所适从。
l数据烟囱林立:想要打通多个业务系统、前端行为、线下、CRM、ERP等数据,通常需要编写代码调用API实现。
l流量混合:指标数据的获取直接在业务数据库上进行,复杂聚合和大批量查询给线上业务造成影响,业务数据库时常被打满。
l对终端用户关注不够:企业服务的指标分为B2B和B2B2C。前者关注我们的客户对产品的使用情况,比如知识点数量,消息数量,服务用户数等,这是业务数据化的体现。后者关注终端用户的产品体验,是帮助客户更好的服务他的客户,比如留存分析、分群分析、分布分析、漏斗分析、属性分析、多维事件分析等,这是将数据业务化的体现。伴随着自有渠道触达的终端用户越来越多,对终端用户的分析势在必行。
增长期
当产品功能基本稳定,用户基数初具规模,数据类型愈发丰富,同时产品、运营、市场等团队对于数据分析的需求愈发迫切,之前的需求支撑模式已不具可持续性。在资源(特别是人力资源)有限的情况下,通过梳理所需能力,我们采取开源组件与公有云服务共存、自研与采购并行的策略来快速支撑BI应用。我们所梳理的最小能力列表如下:
l灵活可扩展的数据落地标准,用以规范数据生命周期中每一环节的行为,提高数据质量、加速交付效率、降低沟通成本
l可靠的数据采集工具,用以将数据从源头接入传输系统
l高效、稳定、易用且支持 Time Travel 的数据传输管道,用于完成数据的快速传输及反复的转换投递
l提供OLAP服务的实时数据仓库,用以存储从各烟囱获取的数据并提供实时的数据分析服务
l灵活响应数据分析需求的BI系统,用以支撑业务人员快速定制数据分析需求,及数据大盘展示
l支持多维分析的自助式用户行为分析系统,用于支撑互联网营销和终端用户分析需求
探索数据驱动之路
数据处理的关键在于疏通好一条“流”,管理好两个“点”。一条流即数据的流动,两个点即数据的产生点与落地点。按照数据的流向,我们把数据流的处理过程分为数据接入(埋点、采集抽取)、数据传输转换与加载、数据建模与存储、数据统计分析与挖掘以及数据可视化与反馈5个阶段,如图所示。

后续内容将对这5个阶段做更为详细的介绍。
数据接入
数据接入阶段负责将所需数据以可靠的方式进行分类收集并投送到传输通道。通过相应技术将前端用户行为、服务端埋点日志、数据库操作日志以及数据库实时数据进行接入。
数据埋点
所谓埋点,是指在业务逻辑中嵌入数据采集代码的过程。埋点主要分为全埋点、代码埋点和导入辅助工具埋点。
数据埋点是数据流动的源头,是数据处理的第一个“点”,在埋点的过程中需要注意考虑以下两个方面的内容:
原子操作埋点
埋点的过程中尽量避免对数据的加工聚合,尽量只对原子操作进行埋点。这样一方面降低埋点工作的复杂度,另一方面增加埋点数据的复用性,最后还可以避免埋点逻辑BUG引起的指标错误与混乱。
幂等性
即数据被重复投递时业务不受影响的特性。数据的重复投递在实际业务中很难避免,如数据采集端和数据传输系统在发生容错行为时很容易出现重复。Flink等流处理框架所支持的 "exactly once" 特性,也仅仅是保证在数据流中的每条数据被处理一次,当某条数据本身有多条存在于流中时,许多策略便失去作用。
我们的经验是越在数据生命周期的早期采取措施,越容易解决问题。在埋点阶段指定数据ID是准确度最高、成本相当可控的选择。业务中通常采用如下方式为数据分配ID:
l具有业务含义的字段,例如用户消息选择已有的消息ID作为埋点数据ID。
l具有业务含义的字段及其他字段组合。
l全系统唯一序列号,这种方式增加了系统的复杂性,需要序列号生成服务,且对埋点方的性能有一定影响。埋点方可以采取批量获取序列号以及异步埋点的方式降低影响。异步埋点有丢消息的可能,使用时需要权衡。
lUUID,当上述方式都不能使用时,可以选择UUID,该方式并不推荐,其不光占用空间很大,且索引效率太差。
l在数据加工过程中生成数据ID,对于第三方组件产生的埋点数据,如Nginx访问日志等,可选择在数据加工的过程中根据业务需求生成ID。如不同接口的调用可以使用header信息和消息体中的数据生成ID。
对于前端数据的埋点我们使用神策数据SDK,数据格式遵循相应规范,这里不做介绍。
对于后端数据埋点,我们定义了简单实用且低侵入的规范,服务端只需要以普通日志的形式将需要埋点的数据以约定的格式打印到日志文件即可。规范如下:
l在日志数据的最后面拼接埋点数据,埋点数据的总体格式为 saas_log_statistic=JSON String,之所以在日志行的最后面,是为了提取方便。
lJSON String 部分必须包括含 theme 字段,表明日志所属主题,或指标体系,用于在后续数据加载环节进行数据路由
lJSON String 部分必须包括含 timestamp 字段,表明数据产生的时间,在处理数据的过程中以该时间为主,防止在数据传输流程中产生延迟以及在time travel时保证业务逻辑
l除了 theme 字段和 timestamp 其他字段由不同的业务所决定
[INFO]2020-12-15 16:34:39 saas_log_statistic={"theme":"staff_operation","timestamp":1608021279460,"operation_id":980064}
对数据库(MySQL)操作日志我们选择行模式记录,这样虽然会让数据量有一定程度的膨胀,但是大大降低了后续处理环节的复杂度。
数据采集
前端行为日志的采集由神策数据SDK完成,直接提交到相应的数据接受服务。这里值得分享的一点是神策上传数据的巧妙方式。其首先将埋点的JSON数据使用base64编码,然后通过发起一个Get图片的HTTP请求并将数据以请求参数的形式传输。这种方式即解决了浏览器跨域的限制,也防止了因为数据中存在特殊字符而导致的问题。请求如下图所示。

服务器端的埋点数据则通过 logtail 与普通日志一起无差别收集,并投递到数据流转环节,原始日志可以在后续的数据清洗环节处理。
数据库操作日志(Binlog)通过阿里云提供的日志订阅服务(或canal)接入,解析并封装为内部格式以后,投递到流转系统。
数据抽取
数据抽取部分主要完成将事务数据库中的数据同步到数据仓库的工作,我们使用阿里云数据传输服务(DTS)来完成准实时单向数据传输,该服务支持模式变更捕获。在为客户本地化部署时,这部分功能可以通过Binlog和数据库定时扫描实现。
数据传输转换与加载
数据传输
我们使用的数据传输管道主要有 Logstore、Kafka及Pulsar。
Logstore是阿里云提供的日志类数据一站式服务。其支持日志检索、数据订阅、数据加工等功能,来也科技的SaaS服务从诞生之日起就运行在公有云上,所以使用云原生的服务是第一选择,但是在用户本地部署时,我们会选择使用开源消息中间件替换。
Kafka主要接收来自前端的用户行为数据,由于是外采系统所以不便替换。我们内部已经全部迁移到Pulsar,因为Kafka基于offset的确认机制在多并发消费的场景中存在丢失消息的可能,要避免这种问题会让系统复杂度增加。
Pulsar采用基于记录的确认机制,使用更加灵活简洁,另外Pulsar支持多租户,这也非常适合我们的业务场景。通过Pulsar主要完成日志数据之外的其他数据流动需求,比如数据库操作日志、业务数据等。
数据转换
数据转换主要完成以下工作:
l数据标准化:如对不符合标准格式的埋点数据增加 theme 字段,从timestamp字段衍生date_key和time_key字段,为不具备唯一主键的记录生成主键等。
l数据清洗:对于不需要的数据以及明确可以被丢弃的数据进行清洗,如普通日志和存在明显错误的埋点日志。
数据的转换工作主要依靠 Logstore、Flink、Spark等组件完成。
Logstore提供类Python语法编写自定义数据转换逻辑,其在数据到达时触发转换,也支持 Time Travel。其优点是对于比较简单的转换过程提供了云原生的解决方案,语法丰富。缺点是没有状态管理,复杂的业务逻辑实现困难且运算缓慢。其加工的数据只能流转到新的Logstore,不能直接进入数据仓库。
为了弥补 Logstore 的不足并支持客户本地部署,我们基于Flink开发了统一的转换投递系统。该系统从特定的数据管道消费数据,根据标准的theme字段和配置好的路由规则将数据投递到不同的存储目标(ODS层)。同时我们也通过Flink实现了诸如实时统计、实时操作记录等功能。我们也使用spark处理大批量历史数据。
数据加载
数据加载是数据处理的第二个“点”,经过数据转换组件以后的数据需要进入持久存储。这一环节要再次注意数据的幂等性,埋点及转换环节生成数据唯一ID以后,是否能最终实现幂等,就取决于数据加载环节。可以使用以下方式实现数据幂等:
lMySQL的replace特性,此特性会根据主键使用新数据替换旧数据,支持批量操作,效率很高
lMongoDB的Upsert操作,只能逐条更新,效率较低
数据建模与存储
数据仓库
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
数据仓库在我们业务中扮演的最重要角色是数据集成与实时分析的承载者。数据经过前述环节的处理后,全部汇聚到数据仓库。我们对数据仓库提出的需求是支持超大容量、支持复杂查询、超大表查询秒级响应。在线上SaaS产品中我们使用了ADB作为实时数据仓库。
AnalyticDB(简称 ADB) 是阿里提供的自研实时云数据仓库服务。其兼容MySQL协议,可以让我们在为客户本地部署时将相关业务轻松切换到MySQL。
MongoDB也扮演了有限的数据仓库角色,主要是存储通用拉链表以及供给业务应用查询的指标表(APP层)。
数据分层
因为数据仓库中充斥着各种各样的数据,那么如何管理这些数据就显得格外重要,我们将数据进行分层管理,如图所示:
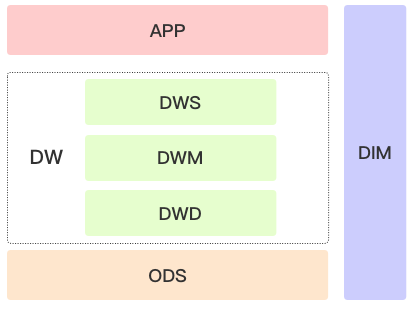
数据分层示意图
ODS(Operational Data Store)层,即运营数据层,业务产生的数据通过ETL之后装入该层,为了提高利用率和追溯方便性,在数据转换的过程中只对数据进行非常克制的去重操作。所有的事实表都划入该层,如用户消息明细表、接口调用明细表、拉链表等。
DW(Data Warehouse)层,即数据仓库层,是整个数据仓库最核心的一层。本层又分为DWD、DWM和DWS层。
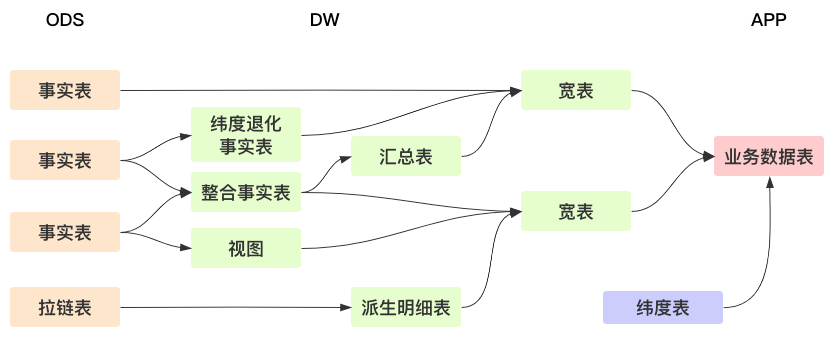
lDWD(Data Warehouse Detail)层:即明细数据层,该层与ODS层保持相同的数据粒度,完成以下两方面工作:其一,纬度退化,将一些纬度退化到事实表中,减少查询关联。其二,相同主题数据合并,如在统计服务可用性的场景中,将Nginx调用事实数据与用户消息事实数据进行合并,形成完整的消息可用性明细数据。另外,创建视图也是在本层实现数据合并的一种有效方法。
lDWM(Data Warehouse Middle)层:即数据中间层,该层会在ODS层和DWM层的基础上做轻度汇总,目的有三:其一,产出业务上使用的明细表用于后续统计,如通过拉链表生成完整的用户操作记录表;其二,降低DWS层数据生成的复杂度,如统计出部分用户行为数据以便在DWS层将其按照主题汇总;其三,减少DWS层重复统计的计算量,比如在本层统计出粒度更小的知识点的相关指标,在DWS层直接根据该层指标进行汇总,不必从DWD层进行全量汇总。
lDWS(Data Warehouse Service)层:即数据服务层,也称数据集市层或宽表层 。本层的数据基于DWD、DWM、和ODS层产出,根据主题划分,如企业、机器人、员工、用户、功能、知识点、任务等主题,生成统计字段较多的宽表,以供后续业务查询和OLAP使用。
APP(Application)层,即应用数据层,本层面向特定业务,数据的聚合粒度以业务拿来即用为准则进行把控。一般将数据存储到MongoDB中供业务进行查询。
DIM(Dimension)层,即维度表层,对于基数比较小的维表(比如机器人表)我们将其数据发送到每一个存储节点,以提升关联查询效率。但是对于高基数的维表(比如用户表,数据量好几亿),则避免使用数据广播。值得一提的是,我们在业务纬度的基础上引入了时间纬度,能非常容易回答诸如“周三的流量趋势有什么特点”、“节假日比较活跃的用户有哪些”等问题。
数据分层管理的优势体现在以下几个方面:
l清晰数据结构:如图所示,每个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解。
l减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
l统一数据口径:通过数据分层,提供统一的数据出口,统一对外输出的数据口径。
l复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题。
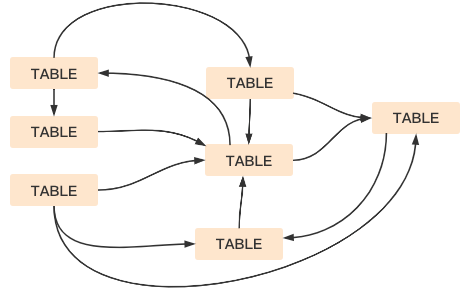
在对数据分层以后,为了防止出现下图所示的混乱依赖关系,我们坚持如下原则:
l禁止同层依赖
l禁止反向依赖,数据只能从明细层往汇总层流动,
l禁止循环依赖,如果上述两项措施严格实施,那么就不会出现循环数据依赖。
数据统计与分析
预定义指标生成
预定义指标的生成过程通常是从多个事实表中聚合所需数据,我们将这部分需求抽象成独立的服务,该服务负责从底层数据表中聚合数据并存入高层指标表。统计规则通过配置实现。如下所示,是一段产出天粒度统计数据的配置。
lgrain_type:代表统计周期,如小时/天/周/月/季/年等
lgroup_by: 分组字段,不同的表中获取的数据会根据该字段进行整合,将其设计为数组,是为了支持字段别名
ldate_field、time_field:日期和时间字段的名称
lstat_tables: 每个指标的生成逻辑,如staff_login_number指标的计算过程会转换成如下SQL语句:select sum(login_number) as staff_login_number from dw_stats_staff_daily
dw_stats_staff_daily where (op_type='LOGIN') and date_key=20201201
{"grain_type" : "daily","group_by" : [["account_id","account_id"]],"date_field" : ["date_key", "date_key"],"time_field" : ["time_key", "time_key"],"out_table" : "dw_stats_account_daily","stat_tables" : [{"source_tbl" : "dw_fact_message","out_field" : "bot_count_active","raw_func" : "count(*)"},{"source_tbl" : "dw_stats_staff_daily","out_field" : "staff_login_number","raw_func" : "sum(login_number)","filter" : "(op_type='LOGIN')"}]}
即席查询(Ad Hoc)支持
即席查询是用户根据自己的需求,灵活选择查询条件,系统根据用户的选择生成相应的统计报表。
我们对即席查询的支持通过Redash + 数据仓库 + Logstore的方式实现。
l通过Redash,使用SQL语句从数据仓库查询原始数据或聚合指标。如下图所示。
l对于极少数无法从数仓中直接满足的需求,会将查询下发到未做任何数据清洗的Logstore,其支持类SQL语法查询。

实时指标支持
Flink通过将不同来源的流进行合并(Logstore、Kafka、Pulsar),在产出组合明细数据的同时生成实时统计数据。例如,我们将Binlog(在Pulsar中)和业务日志(在Logstore中)通过Flink进行实时聚合,一方面实时产出通用数据拉链表,另一方面产出实时用户操作记录,于此同时产出业务相应的实时统计数据,让用户在看到明细的同时得到准确的统计结果不必等到固定的统计周期(小时/天)结束。如图所示:
数据反馈与可视化
SaaS产品中的指标体系
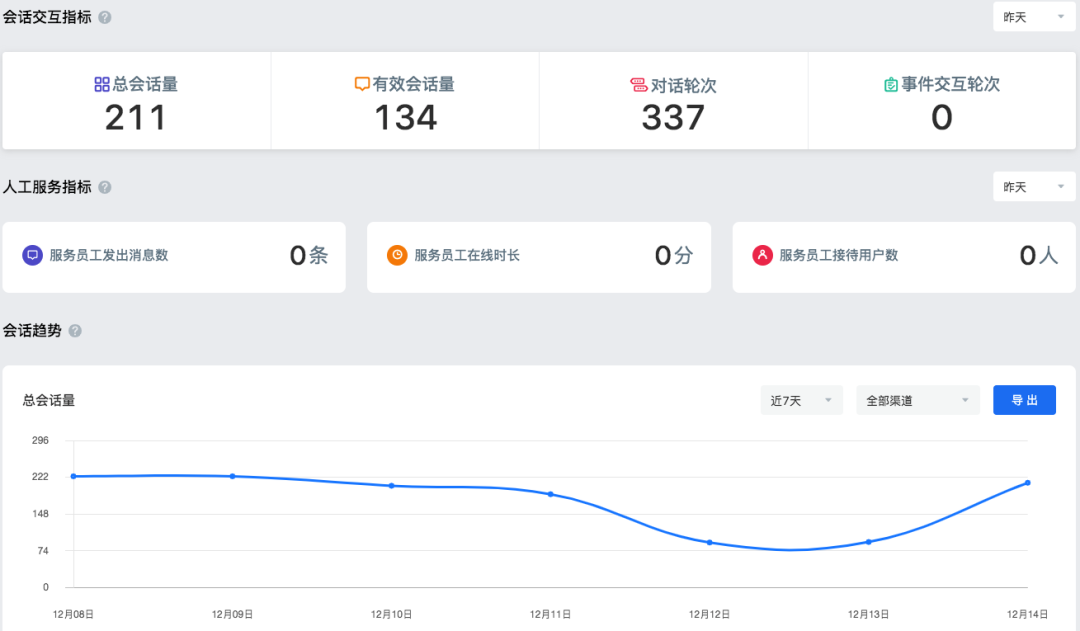
落地在吾来SaaS产品中的指标数据需求通常是比较稳定的,所以我们在APP层生成专用的指标表,然后通过gRPC服务提供给业务方。APP层的指标表通过利用下层准备好的数据,可以非常轻量的生成。如下图所示,是吾来数据概览页:
基于数据仓库的BI系统
为了应对业务、运营、产品等不同角色对数据的特殊需求,我们通过Redash系统将数据仓库的访问对内部开放。相关同学只需要通过SQL语句就可以获得所需指标。这项举措在极大提高指标产出效率的同时,有效解放了数据开发工程师,让他们从“取数仔”的角色中解脱,将更多的时间投入更加有价值的工作。我们使用Redash支撑了如下场景:
l自定义查询:前文已经提及,Redash支持非常丰富的数据源,我们可以将自己编写的查询保存以后分享给他人,不断完善分析需求知识库。同时还可以组合多种数据源产出临时报告。
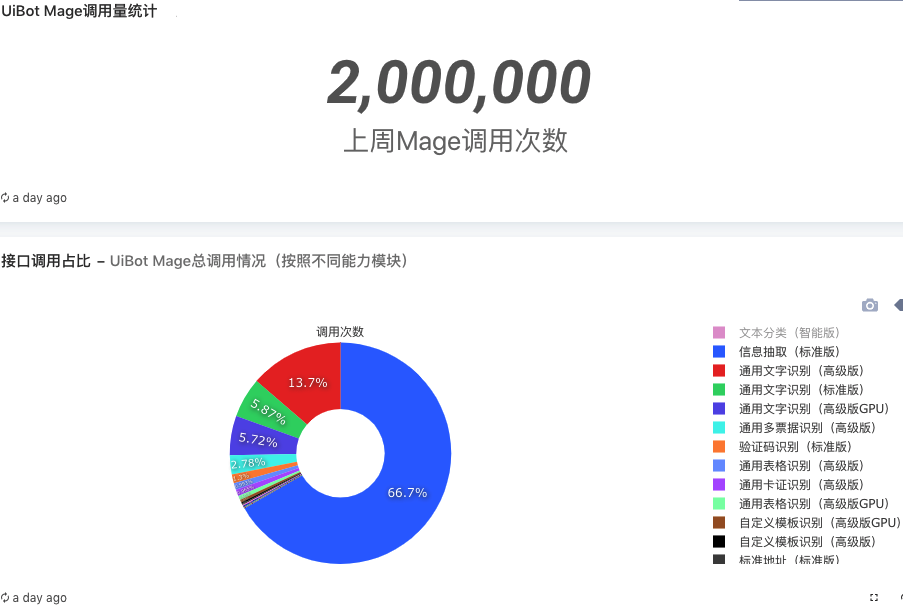
l数据大盘:数据大盘是指标常态化输出的更好方式,这样既可以提高指标的关注度,也可以增加业务的聚焦能力。首先将自定义查询的结果使用不同的形式进行可视化,然后将各查询的可视化单元进行拼装,实现灵活的数据大盘展现需求。配合Redash提供的任务调度功能,可以自动刷新大盘数据。如下图所示,是来也科技 UiBotMage 数据大盘一角。数据大盘指标的选择需要慎重考量,通常可以采用第一关键指标加衍生指标法以及海盗指标法完成。
l发送指标邮件:对于比较重要的指标,我们会定期发送邮件给相关负责人,Redash对多数据源(包括Python)的支持让这一切流畅衔接。首先编写相应的查询,再通过Pyhton数据源调用查询结果,最后通过调度程序定时执行并发送邮件。这种方式即提高了需求响应效率和速度,又统一了指标口径。
l业务数据异常报警:通过编写查询并配置基于该查询的报警规则,Redash可以将数据的变化通知相关人员。比如消息数环比变化了10%以上或某指标表没有产出数据时会发送邮件。
基于行为事件的多维用户分析系统
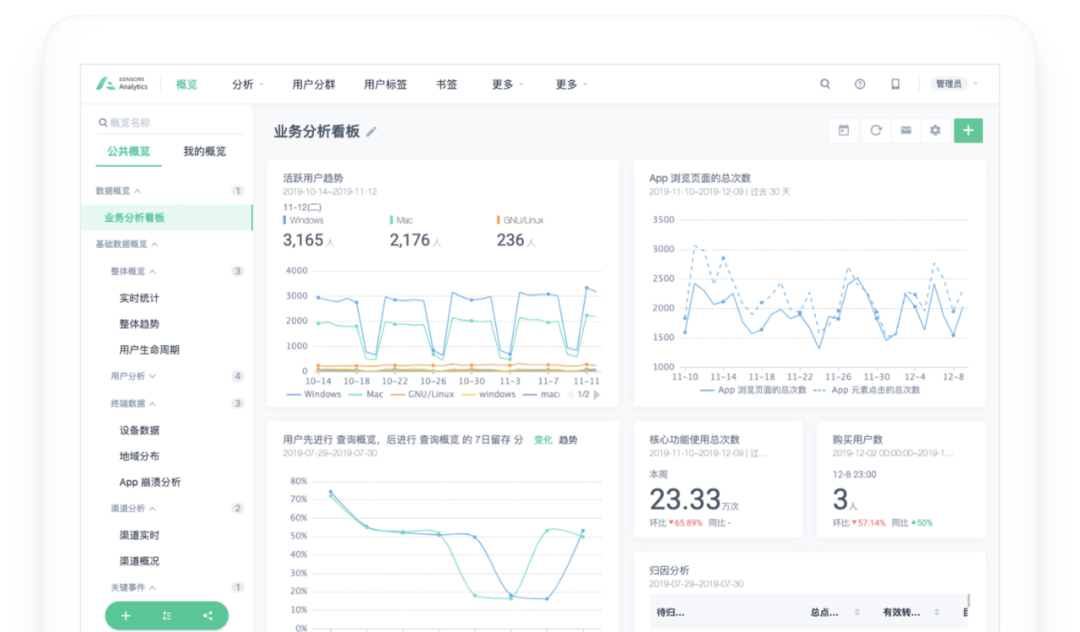
多维分析是相对复杂的系统,我们采购了神策数据作为用户事件分析的辅助工具。通过多维用户分析,我们既可以分析产品的好坏、营销的效果、渠道的价值,也可帮助用户更好的了解他的用户。如下图所示,是利用该系统对UiBot官网的流量评估。
总结与展望
数据驱动相关工作与应用开发有所不,没有立竿见影的效果,需要比较长期的资源投入、成果输出及实践检验。在这一过程中需要克服的不仅是技术的难题,还有内心的困扰以及团队的担忧,必须有躬身入局的决心和持之以恒的信念。
经过不懈努力,来也科技的BI应用走过了“俺也要有”的阶段。通过一套比较完备数据支撑体系和产品,走出了野蛮生长的困境,正在不断助力业务发展。但是我们依然面临着很多挑战,如数据烟囱突破困难、终端用户价值发掘抓手不足、业务数据化不够深入、数据业务化困难等。
为了更加充分地发挥数据驱动的价值,我们需要在业务数据化和数据业务化两个方向持续努力,在如下应用领域争取突破:
l数据驱动决策:提升决策准确性,降低沟通成本,从“嗓门大既有理”走向“有数据再讲理“。
l数据驱动产品智能:数据驱动产品智能的价值要远高于数据驱动决策,如用户画像、文本挖掘、精准广告、个性化推荐等技术会帮助企业持续增长。
l数据驱动运维智能:让运维同学从繁杂的报警、切换、重启等工作中得到一定程度的解放。
本文作者:康永胜
本文编辑:刘桐烔







