智能文档处理(IDP)可帮助企业实现日常文档处理工作的自动化,在文档识别、分类、信息抽取和比对等各个方面,为企业工作人员提供帮助。印章识别是智能文档处理中一种重要的识别能力,广泛应用在合同比对,出入库审核以及发票报销等场景。以往这些工作环节中需要人工对印章图像进行核对校验,流程繁冗,而使用OCR技术进行印章自动识别则可为企业有效节省用工成本。
印章识别问题的特点
与普通场景下文字识别问题相比,印章识别具备一些独有的特点,而这也正是它的难点所在:
1. 印章样式的多样性强:印章从种类上分有公章、财务章、合同章等,从形状上看有圆章、方章、椭圆章等,印章文字的排布方式、文字的阅读顺序都有各种变化。
2. 容易有背景干扰:文档中盖章区域的背景多种多样,背景上的文字与印章文字往往会形成遮挡干扰,影响印章的识别。
3. 印章图像质量受影响因素更多:印章由人加盖于文档上,由于印泥质量,用印力度等因素的影响,印章图像容易出现色彩不均,字形模糊的现象,质量较差的印章文字人眼甚至都很难分辨。

| 
| 
| 
| 
| 
| 
| 
|
印章的多样性,体现在形状,阅读顺序 | 背景干扰、印泥缺失、字迹模糊 |
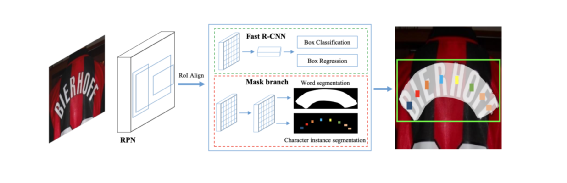
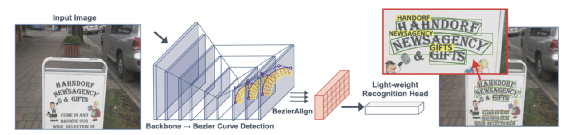
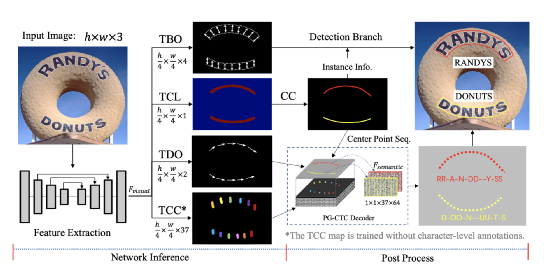
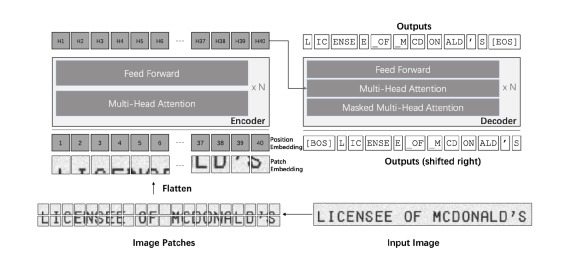
其中的两个主要步骤分别是印章位置检测与印章文字内容识别。下面主要介绍一下这两个步骤的常用方法,以及来也科技在实践中选择的方案。印章位置检测需要从文档图像中定位印章主体所在的位置,这是一种典型的目标检测场景,现在已有很多基于深度学习的目标检测方法,如RCNN系列,YOLO系列等。这个任务本身比较经典,在此不做过多描述。值得说明的是,这些目标检测方法基本都为“硬标签”学习,即每个目标只有一个标签。但印章本身还具有形状和颜色这两个很重要的属性,很多情况下希望在得到印章位置的同时,同时还可以得到这两个属性值。因此,我们选择在传统的yolov5目标检测框架上进行改进,同时输出印章的位置、形状、颜色。为达到此目的,我们主要改进了yolov5方案中的两个处理:1. loss计算:计算分类损失时的标签为多标签,同时使用带有sigmoid操作的交叉熵计算loss:在训练过程中计算loss使用的标签将其组织成[1, 0, 0, 0, 0, 1, 0]格式,同时使用torch.nn.BCEWithLogitsLoss() 计算loss。2. 后处理nms:我们使用组合多类别nms代替原始的类间nms操作:yolov5中原始自带的nms操作为torchvision.ops.nms(),会忽略掉每个Bbox的类别信息,因此在模型后处理时使用tf.image.combined_non_max_suppression()进行nms操作,该方法会考虑每个Bbox的类别信息。在确定了印章的主体位置并相应的裁切图像之后,印章文字的识别与场景文字识别的流程很类似,主要有两种可选择的策略:先使用文字检测模型检测到图片内的文字item,该检测模型需要能检测不规则形状的文本行,再使用文字识别模型识别文本行的文字内容(印章内文字识别需要使用文本矫正方法将曲形的文本拉直后进行识别)。甚至还可以选择检测印章中的各单个字符,然后逐个字符识别后再按照一定的读取顺序规则将单字识别结果进行串联,得到印章文字识别结果,2. 一阶段:即端到端文字识别。此即由模型直接从含有文字的输入图片,预测出图片内的文字内容,减少中间处理过程。两阶段的OCR识别方法,检测方法与识别方法之间互相独立,无法进行联合优化,识别的效果会强依赖于检测结果。与之相比,端到端的OCR识别方法框架简单,同时会避免分阶段训练产生的误差积累。因此,我们认为印章文字识别这个场景下,能够端到端训练的模型会具备更大的潜力,以下就介绍几种我们调研过的典型模型。Mask-TextSpotter系列方法是由白翔团队从2018年提出的一个可端到端训练的文本检测与识别方法,可以对任意形状文本操作。模型主要由两部分组成:基于实例分割的文本检测器;基于字符分割的文字识别器。Mask-TextSpotter v1 模型整体结构如下:该方法受到Mask RCNN的启发,在特征提取之后介入两个分支,分别进行文本区域检测和生成文本实例分割图与字符分割图(字符分割图数量为字符集个数+1)Mask-TextSpotter v2 在v1的基础上给识别分支添加了空间注意力(SAM)模块。Mask-TextSpotter v3 在v1和v2的基础上提出了一个新的结构Segmentation Proposal Network(SPN)代替原先的RPN网络,SPN属于一种U型结构,可以融合不同尺寸的特征图之后进行分割得到文字候选区域。Mask-TextSpotter 系列可以将文本检测与识别放在同一个网络中进行端到端训练,可以避免两阶段OCR识别中的中间人为误差, 但是该系列需要字符级标注,标注成本较高,需要标注文字的轮廓区域,对文字的阅读顺序不敏感,而且识别分支需要为每个字符生成一个分割图,用来识别汉字时,会生成大量的分割图,增加计算量与内存使用量。ABCNet是由华南理工大学在2020年提出的,该方法提出了一个可适应于任意形状文本的参数化贝塞尔曲线,设计了一个新的BezierAlign对齐层,可以精准的提取任意形状文本实例的特征 ,与标准的bbox检测方法,bezier曲线检测方法只引入了一个可忽略的计算量,整体模型框架如下:检测框架使用了一个signal-shot,anchor-free的卷积神经网络 ,在检测头将每个文本的检测转换成文本行上下两条曲线的检测,每条曲线使用一个三阶贝塞尔曲线拟合。识别分支使用传统的crnn网络加ctc的方法。ABCNet v2 在此基础上,将识别分支改为使用attention模块解码,骨干网络采用双向多尺度金字塔结构,用来检测不同尺度变化的文字特征。同时针对v1训练中,识别分支的feature map与检测分支不共用的问题进行改进,首先对检测结果使用NMS消除冗余框,使用文本实例的真实控制点与每个检测框的控制点的和的最小差,得到检测框并进行识别ABCNet 系列虽然不需要字符级标注,但主要还是两阶段的策略放入一个模型中训练。检测与识别中间的过程处理比较麻烦。PGNet是由百度提出的一个多任务单级文本检测器,可以实时识别任意形状的文本,且提供了基于PaddlePaddle框架的源码。PGNet把文字检测和识别归为以下四个任务:text center line(TCL,文本中心线检测)text border offset(TBO,文本边框偏移)text direction offset (TDO,文本方向偏移)text character classification map(TCC,文本字符分类map)同时,提出PG_CTC loss,避免字符级标注,使用PG_CTC loss,直接从2维空间得到 high-level 字符分类向量,提出GRM(图修正)模块,提高端到端表现。PGNet的整体模型结构如下图:在训练阶段:TBO,TCL,TDO使用相同尺寸大小的label map,pixel-level TCC map模块使用PG-CTC loss解决缺少字符级标注的问题。在推理阶段:从TCL中计算每个文本区域的中心线,按照TDO的文本可读方向排序,恢复阅读顺序,从TBO中提取边界偏移信息,通过多边形回归得到每个文本区域的检测结果,同时PG-CTC 编码器可以将二维的TCC map序列化为字符概率序列,并解码为最终的文本识别结果。PGNet不需要NMS和RoI操作。TCL map中可以计算文本区域的中心点序列 ,并按照可读方向排序,特别的,还采取了一种形态学的方法,得到文本区域的骨干,作为中心点序列。从TDO map中得到每个点的检测结果,通过计算所有点的平均方向并根据投影长度方向进行排序,得到中心点序列。PGNet在训练中与Mask-TextSpotter类似,需要生成字符集个数级别的分割图,用来预测文字序列。在中文场景下,模型会变得臃肿,且在训练生成groundtruth时中,需要每条文字字段的上下两条包围曲线点的个数相同,生成不同任务对应的标签,需要比较麻烦的预处理工作。 TrOCR由微软亚洲研究院在2021年提出,它采用了 Transformer 结构,包括图像 Transformer 和文本 Transformer,分别用于提取视觉特征和建模语言模型,并且采用了标准的 Transformer 编码器-解码器模式,其结构如下图: 在TrOCR中,编码器用于获取图像切片的特征,解码器以自回归方式生成文本序列,某一步的解码器输出会关注编码器的输出和之前已生成的文本序列。对于编码器,TrOCR 采用了 ViT 形式的模型结构,具体的参数初始化可以用DeiT或者BeiT。编码器归一化输入图像的尺寸,并将其切片成固定大小的正方形图像patch,以形成模型的输入序列。模型保留预训练模型中的特殊标记“[CLS]”代表整张图片的特征,对于 DeiT 的预训练模型,同样保留了对应的蒸馏token,代表来自于教师模型的蒸馏知识。而对于解码器,TrOCR则采用原始的 Transformer 解码器结构,参数初始化使用RoBERTa。 与前面三种介绍的模型不同,TrOCR不仅利用了大规模无标注数据预训练的图像和文本Transformer初始化其模型,还基于从两百多万PDF文件中自动合成出的六亿多条标注文字条目数据,进行了文字识别预训练,微软也开放提供了不同复杂度的TrOCR预训练模型。下游OCR任务的开发人员需要对目标场景数据进行标注,在预训练模型上进行微调。在对几种端到端文字识别模型进行了大量实验与对比之后,我们最终选择了基于TrOCR模型进行印章文字识别。如上所述,我们采用改进后的yolov5框架进行印章检测,采用TrOCR进行印章文字识别。我们的训练数据中包含了2万多张真实标注的印章图片,以及30多万张利用印章模版和phtoshop script脚本合成的印章图片。 在印章文字识别中,我们采用了如下这些图像增强方式:随机resize,模拟拍照情况下,距离目标远近造成的印章尺寸大小问题随机添加纹理特征,模拟盖章情况下印泥缺失,印泥色度不均等情况在hsv颜色空间进行随机扰度,模拟真实场景下印章色度,饱和度不均等情况透明通道使用随机像素值填充,模拟真实场景下印章与背景文字互相遮挡与背景干扰等情况
印章的方向会随着盖章的方向发生变化,文字的方向也会随之改变,组织label时我们考虑了两种阅读情况,从上到下阅读顺序,从右至左阅读顺序。设置了两种不同的特殊符号“$$”和“**”代表两种不同阅读顺序的换行符。
在我们的实验中,我们比较了解码器自回归输出下Beam Search模式和Greedy模式的效果,后者仅较前者在文字条目F1(下面有定义)有0.4%的下降,而推理速度会快的多,因此我们采用Greedy模式。除此之外,在将模型转换为线上服务的serving模型时,我们也注意利用了Transformer QKV计算时能够cache的特性,尽量省掉每个步骤中与此前步骤的重复计算,提升推理速度。 为了衡量印章识别的效果,我们设计了两个评测指标,分别是印章存在性F1,以及印章文字识别条目F1,两者的定义如下:存在性F1:2 * 召回率 * 准确率 / (召回率 + 准确率)文字条目准确率:正确的识别个数/总印章文字条目识别个数文字条目F1:2 * 召回率 * 准确率 / (召回率 + 准确率)我们的测试集涵盖了13个场景的真实印章图像数据,在印章存在性F1和印章文字条目F1这两个指标上均超过了 OCR 头部厂商:

印章识别已经在来也智能文档处理平台上线。点击demo,体验一下Mask textspotter V1:https://arxiv.org/pdf/1807.02242.pdfMask textspotter V2: https://arxiv.org/pdf/1908.08207.pdfMask textspotter V3: https://arxiv.org/pdf/2007.09482.pdfABCNet:https://arxiv.org/pdf/2002.10200.pdfABCNet V2:https://arxiv.org/pdf/2105.03620.pdfPGNet:https://arxiv.org/pdf/2104.05458.pdfTrOCR:https://arxiv.org/pdf/2109.10282.pdf