

随着公司产品UiBot的影响力在国内外不断增强,与合作伙伴签订的合同也变得越来越多,故此导致业务人员对合同关键信息的提取工作,变得日益繁重。
基于此,公司内部关于电子合同信息提取的流程自动化需求应运而生。
以下是关于RPA+OCR提取电子合同信息的流程视图。
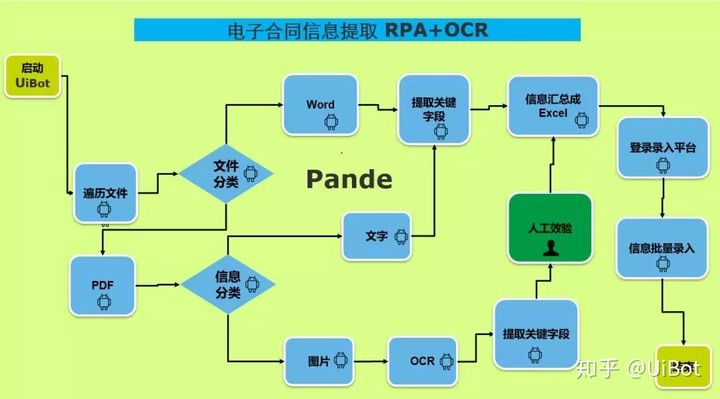
基于电子合同信息的提取,根据文件类型,分为两大类:Word和PDF。
1、Word类。Word类的会直接用RPA机器人UiBot从信息里面根据字符规则提取出关键信息,生成结构化数据,当然,也会遇见有些Word文档是补充协议等,没有相关要提取的信息,这类会根据业务规则直接在流程里面,根据模板判断划分出来。
2、PDF类。PDF类的会根据里面信息分为两类,一类是文字型,一类是图片型。
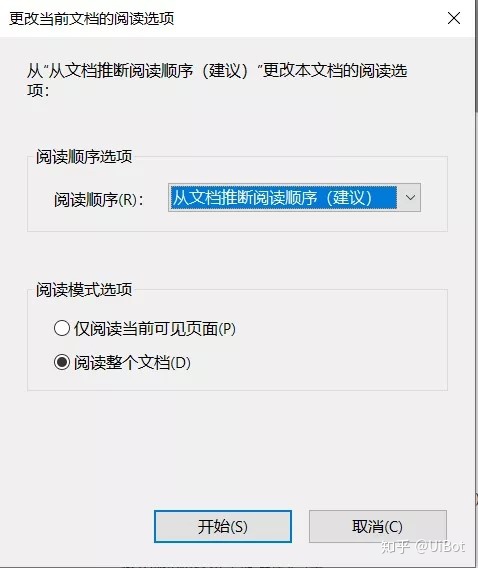
文字的可以使用UiBot的窗口元素中的预制组件获取元素文本或者文本中的获取文本来提取关键信息。(需要注意的是使用Acrobat的时候,需要在编辑中选择辅助工具来做如下图操作)
图片类的,就必须要使用OCR来进行识别,然后进行信息提取,因为上面有盖章等不同因素的影响,正确率并不能保证百分之百,甚至也没有关键性可以回流验证的信息,所以生成的结构化数据仍需要人工二次校验,才可以录入系统,所以基于图片类的电子合同,并没有为业务人员节省多少时间,无非是图片类的电子合同占比并不高,所以影响不大。
当然此类电子合同都是使用公司固定的统一模板,所以总体业务并不复杂,但如果合同模板不能统一,各有特色,可能就需要根据各个模板的类型来做归类划分和业务异常处理。
另一方面,就技术上来说,也可以直接用源码模式来引用Office(Word,PDF文字类)的对象直接后台处理,相比较而言,处理速度会比较快一些。







