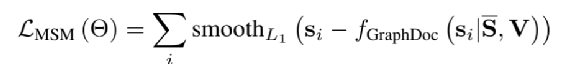一.前言
文档图像有多个文本条目(Segment)或者词(Word)或者区域(Region),文档智能核心要解决的两个问题是:
预测这些 Segment(Word、Region)的类别:如下,左侧图的 Segment 的类别如绿色的 “Date”。
预测它们之间的配对Key-Value的关系,如下,右侧图的配对关系如 “From” 和 “Kevin Narko” 的有配对关系。

学习 Segment(Word、Region)良好的 Embedding 表示; 基于学习的 Embedding 来进行分类从而实现类别预测; 基于学习的 Embedding 计算相似度来预测配对关系,配对的 Segment(Word、Region)相似度很高;
StrucText LayoutLMv3 GraphDoc
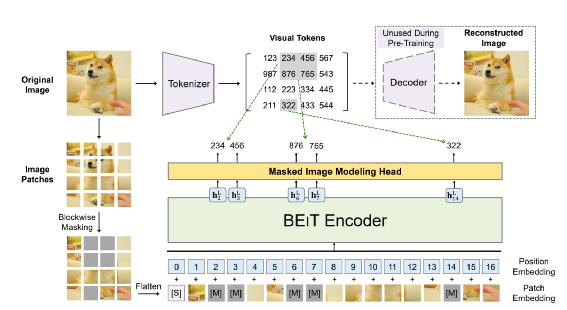
输入特征 特征融合 自监督任务设计
基于多头注意力的Transformer 基于图论的图卷积 GCN
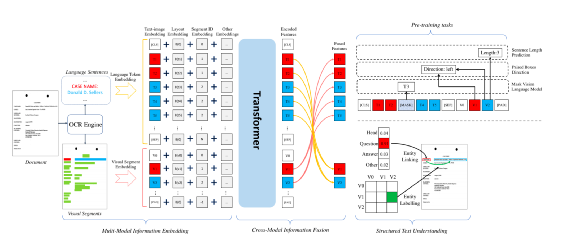
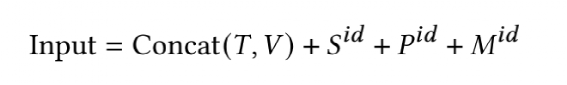
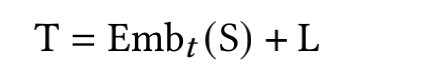
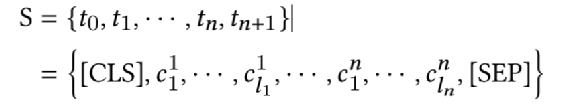
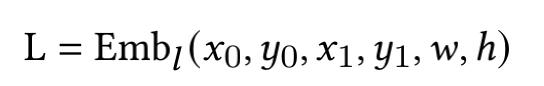
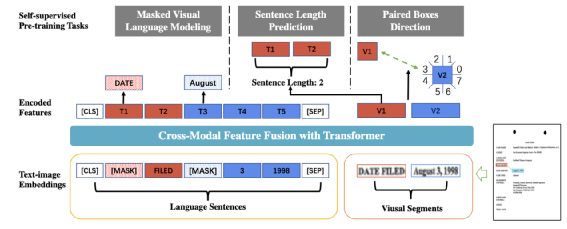
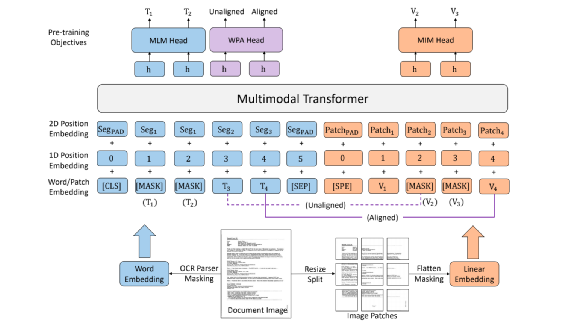
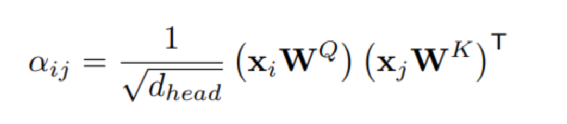
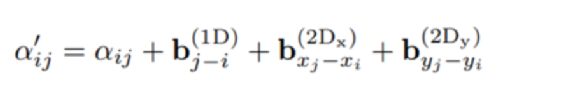
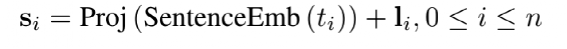
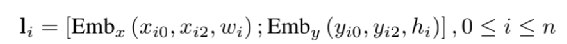
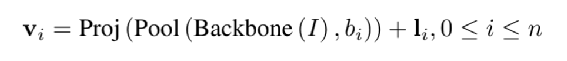
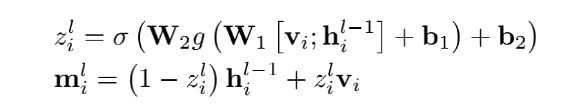
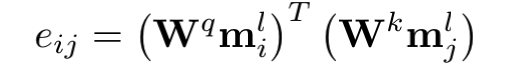
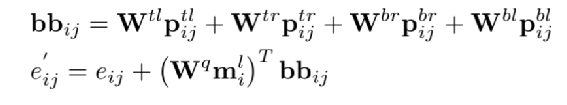
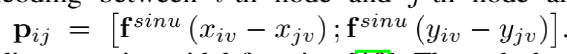
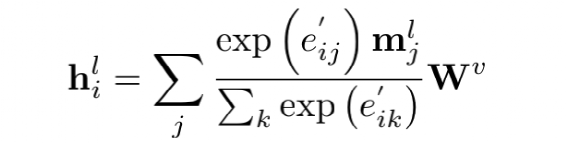
为了减少计算量和避免过拟合,邻接矩阵中每个节点只会保留数值最大的k条边; 为了让每个节点都能学到全局特征,显式的增加一个全局节点G,让这个G和其他所有节点都有边;