

首先Faiss是一个Facebook AI库,它可以使相似度的搜索变得容易;比如,我们有一个向量的集合,我们可以通过Faiss给他们建索引,然后用一个别的向量,我们可以用这个索引在这个集合中找到跟他相似的向量; 而且,他不只能够让我们构建向量索引、搜索向量,他可以通过参数的调节,使搜索变快,但是可能会导致召回或准确度下降,这也是这篇文章一个目的:让大家理解Faiss的底层的原理,更好地根据业务需求去调整参数
import requestsfrom io import StringIOimport pandas as pdfrom sentence_transformers import SentenceTransformerres = requests.get('https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/sick2014/SICK_train.txt')# create dataframedata = pd.read_csv(StringIO(res.text), sep='\t')data.head()
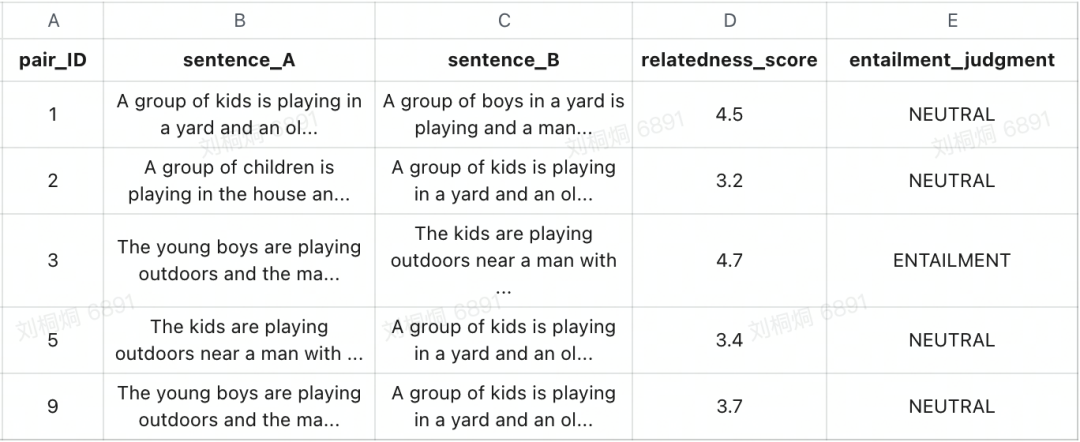
sentences = data['sentence_A'].tolist()sentences[:5]sentences = data['sentence_A'].tolist()sentence_b = data['sentence_B'].tolist()sentences.extend(sentence_b) # merge themurls = ['https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/semeval-sts/2012/MSRpar.train.tsv','https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/semeval-sts/2012/MSRpar.test.tsv','https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/semeval-sts/2012/OnWN.test.tsv','https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/semeval-sts/2013/OnWN.test.tsv','https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/semeval-sts/2014/OnWN.test.tsv','https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/semeval-sts/2014/images.test.tsv','https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/semeval-sts/2015/images.test.tsv']for url in urls:res = requests.get(url)# extract to dataframedata = pd.read_csv(StringIO(res.text), sep='\t', header=None, error_bad_lines=False)# add to columns 1 and 2 to sentences listsentences.extend(data[1].tolist())sentences.extend(data[2].tolist())
sentences = [word for word in list(set(sentences)) if type(word) is str]model = SentenceTransformer('bert-base-nli-mean-tokens')sentence_embeddings = model.encode(sentences)
安装CUDA的Linux机器请用conda install -c pytorch faiss-gpu安装
其他的操作系统用conda install -c pytorch faiss-cpu;
import faissd = sentence_embeddings.shape[1]index = faiss.IndexFlatL2(d)index.add(sentence_embeddings)
%%timek = 4xq = model.encode(["Someone sprints with a football"])D, I = index.search(xq, k) # search#CPU times: user 27.9 ms, sys: 29.5 ms, total: 57.4 ms#Wall time: 28.9 ms[f'{i}: {sentences[i]}' for i in enumerate(I[0].tolist())]
vecs = np.zeros((k, d))# then iterate through each ID from I and add the reconstructed vector to our zero-arrayfor i, val in enumerate(I[0].tolist()):vecs[i, :] = index.reconstruct(val)
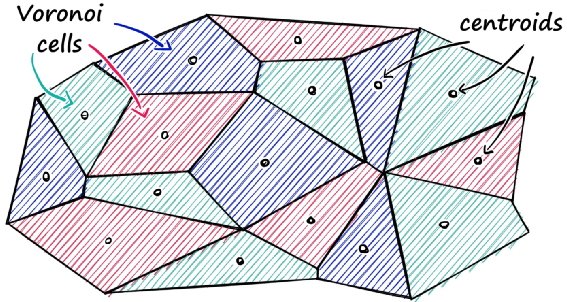
nlist = 50 # how many cellsquantizer = faiss.IndexFlatL2(d)index = faiss.IndexIVFFlat(quantizer, d, nlist)index.train(sentence_embeddings)index.add(sentence_embeddings)
%timeD, I = index.search(xq, k) # searchCPU times: user 3.83 ms, sys: 3.25 ms, total: 7.08 msWall time: 2.15 ms
index.nprobe = 10%%timeD, I = index.search(xq, k) # searchprint(I)#CPU times: user 5.29 ms, sys: 2.7 ms, total: 7.99 ms#Wall time: 1.54 ms
因为搜索的范围扩大了相应的搜索的相应时间也会增加。之间的向量的数量级及与不同nprobe响应关系图如下:
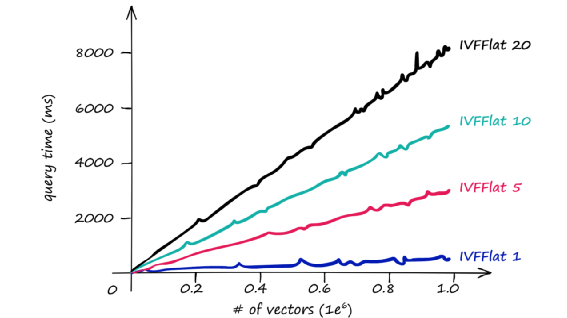 因
因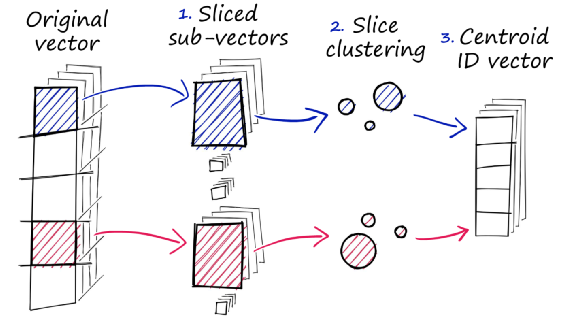
第一步:将原有向量分割成若干个子向量;
第二步:对每一组子向量进行聚类操作,找到每组子向量的多个中心点;
第三步:将这些子向量用离他最近的中心向量的ID代替,得到一个ID的向量;
m = 8 # number of centroid IDs in final compressed vectorsbits = 8 # number of bits in each centroidquantizer = faiss.IndexFlatL2(d) # we keep the same L2 distance flat indexindex = faiss.IndexIVFPQ(quantizer, d, nlist, m, bits)index.train(sentence_embeddings)index.add(sentence_embeddings)
index.nprobe = 10 # align to previous IndexIVFFlat nprobe value%timeD, I = index.search(xq, k)CPU times: user 3.04 ms, sys: 2.18 ms, total: 5.22 msWall time: 1.33 ms
通过添加PQ,查询时间从之前的IVF ~7.5ms下降到~5ms,在这种小数据集上差别不大,但是随着向量数据量级的增加,响应时间将很快有明显的差别;尽管如此,但是我们在返回结果上也会有小小的差异,因为IVF和PQ对准确率都会有所损失,但是不是即使不是跟全量检索一样完美的结果,也能保证跟完美结果相差不远,而且因为预处理过,响应时间有数量级的提升:
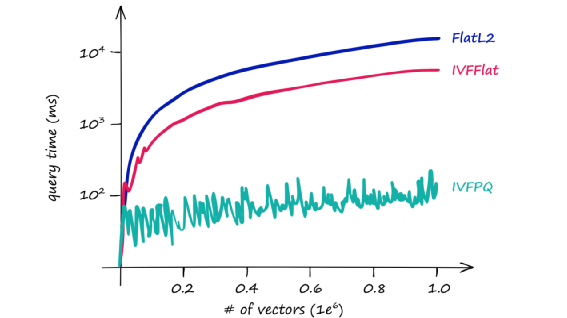 通
通






