


作为一种展示结构化数据的常用手段,表格随处可见。比如:信息收集、商品明细、企业年报等。
随着无纸化办公的流行,企业或个人经常需要将纸质报表上的信息按图片中表格的样式原样生成xls文件,再转录到各自系统中去。
即便可以用OCR(Optical Character Recognition,光学字符识别)技术辅助提取纸张上面的文字,但若要提取表格结构,就需要人工创建表单再将文本一个个复制到单元格中,这可是不小的工作量。
表格识别应运而生。

两阶段OCR是检测+识别,先检测图片中的文本行(以下简称条目),识别即对单一条目进行文本识别。
端到端OCR则直接由模型预测条目的坐标及文本。
两阶段表格也是检测+识别,先检测图片中的所有表格区域,再逐一识别单个表格的结构 端到端直接预测图片中的表格区域及其中的单元格。

可以同时处理有线表和无线表 模型后处理相对简单,基于规则的合并策略也可以case by case的逐渐扩充,比较灵活。
split模型预测的是整行和整列的分隔位置,无法应对倾斜表格,虽然可以通过优化前置的表格检测模型,使得送入SPLERGE的表格相对横平竖直,但如果表格内的文字本身就是扭曲的,那么这个模型就无能为力了。 在有线表的场景下,无论是merge模型还是基于规则,都存在无法合并单元格或错误合并单元格的问题。
另外,文中提出了一种新的图片增强方法Smudge Transform,可以在保留表格结构的同时模糊文字,使得模型可以更加关注文字块的空间布局而不必过分关心文字特征:

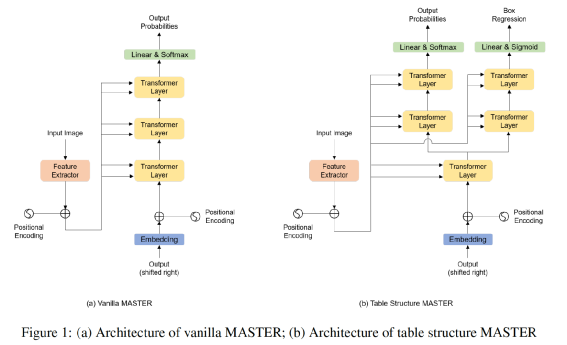
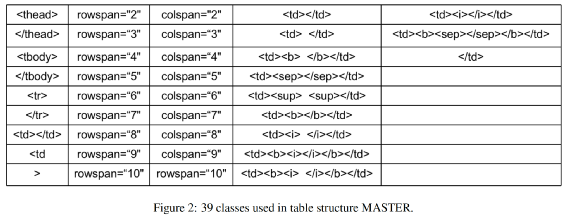
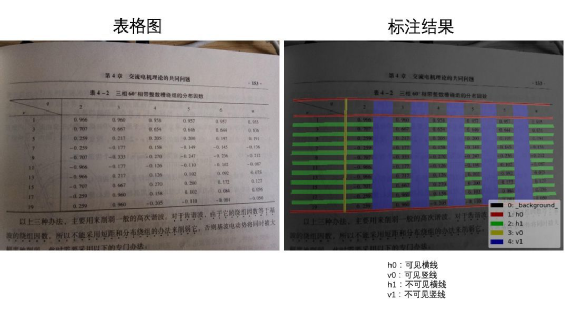
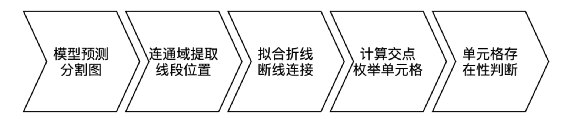
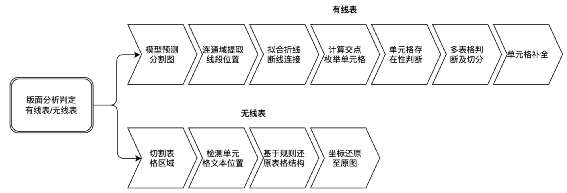
加入前置的版面分析判断图片有无表格,及有线表或无线表。 去掉了unet模型的不可见横线和不可见竖线分支,仅处理有线表。在实际训练中发现,客户的真实无线表并非理想中的长短相近的短文本,例如同一列的文本长度参差不齐,这时列间的不可见竖线区域就不能表示成规则的矩形或四边形,并且在无线表中有较大空白时,相邻的行列分割区域很容易粘连从而导致不能正确提取分隔线的位置,这甚至影响到了可见横竖线的表现,因此我们去掉了该分支。 我们的模型采用了u2net+cbam。在RPA的使用场景中,时常有线条颜色极浅的表格,因此我们加入了注意力机制来提取更细微的图像特征。 有线表后处理中我们加入了多表格切分和单元格补全逻辑。我们的真实使用场景中存在一图多表的情况,因此我们在后处理中加入了策略来切分多个表格。另外模型难免会有漏检线条,我们加入单元格补全机制来提高模型的召回率。 无线表分支基于检测单元格文本的思路,我们暂定使用了yolox,来应对长宽比不固定的情形。
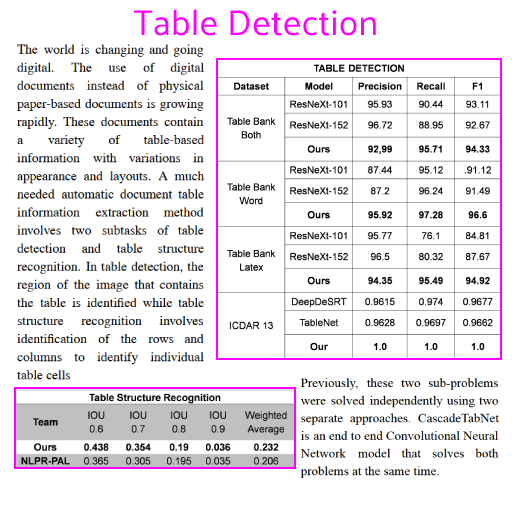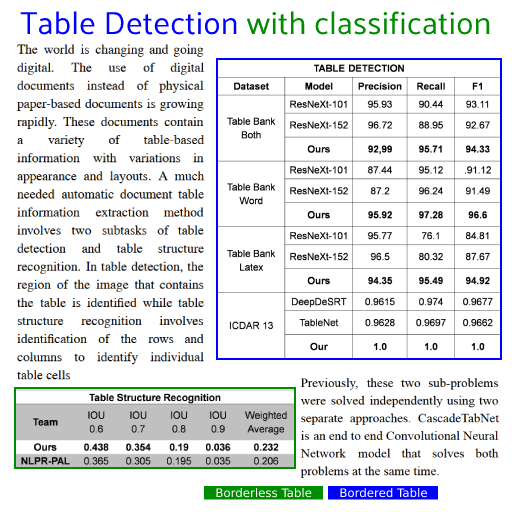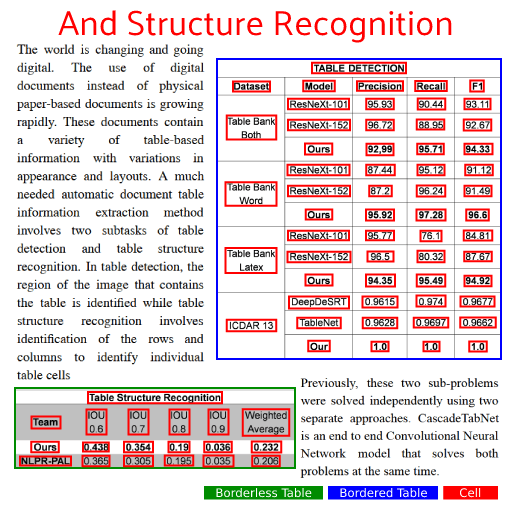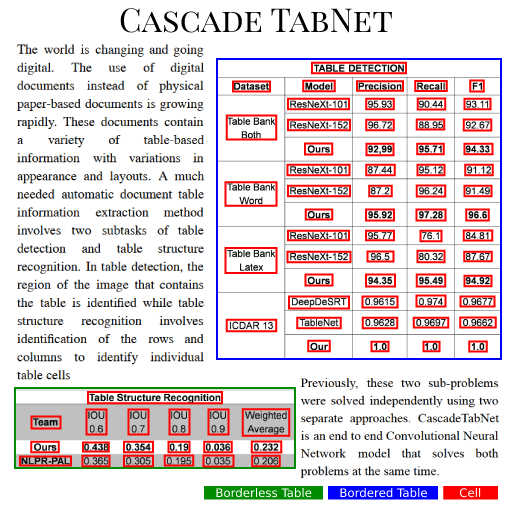
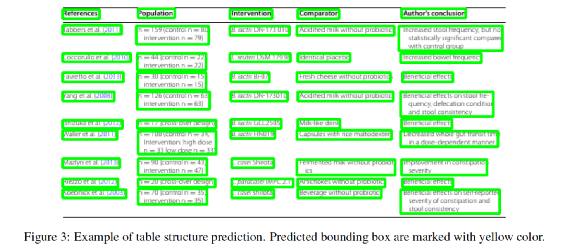
表格结构F1:IOU(标注单元格,识别单元格)≥0.9 视为识别单元格正确。即识别的单元格与标注的单元格iou超过0.9才认为单元格识别正确。由此可以计算一个表格的单元格准确率和召回率,进而得到表格结构F1。 表格结构+文字F1:IOU(标注单元格,识别单元格)≥0.9 且单元格内的文本与标注文本完全相同才视为单元格正确。即不仅单元格的iou要达到阈值,结合OCR后单元格内的文本也要和真值完全相同,这时才认为该单元格识别正确(错一个字也视作单元格识别错误)。由此可以计算表格+文字的准确率、召回率,进而得到结构+文字F1。此指标综合考虑了表格识别能力和OCR能力,较为严苛。
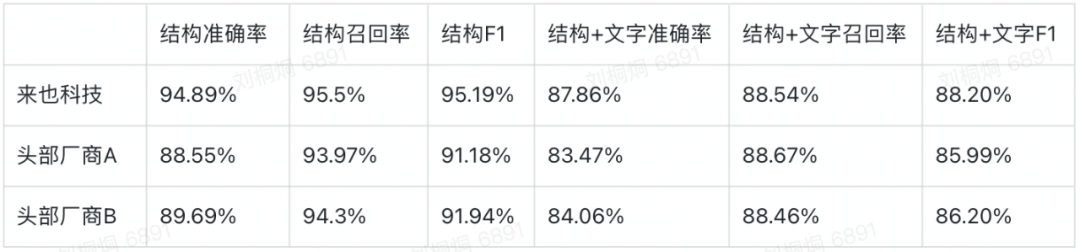
https://github.com/pyxploiter/deep-splerge https://github.com/DevashishPrasad/CascadeTabNet https://github.com/JiaquanYe/TableMASTER-mmocr https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.4/ppstructure/table https://cloud.tencent.com/developer/article/1452973







