

来也科技和英国帝国理工学院合作,在 ICLR-2021 发表一篇长文,主要研究了利用层级式强化学习解决任务导向式对话系统的问题,并在多领域任务导向对话数据集 MultiWoz 2.0 和 MultiWoz 2.1 上取得了目前的最好水平。
标题
Modelling Hierarchical Structure between Dialogue Policy and Natural Language Generator with Option Framework for Task-oriented Dialogue System
作者
Jianhong Wang (Imperial College London), Yuan Zhang (Laiye Network Technology Co.,Ltd), Tae-Kyun Kim (Imperial College London, KAIST), Yunjie Gu (Imperial College London, University of Bath)
Github 地址:
https://github.com/mikezhang95/HDNO
文章地址:
https://openreview.net/forum?id=kLbhLJ8OT12
问题背景
任务导向式对话系统是一个有挑战的研究课题,在对话过程中既需要满足用户的需求,又要保持对话的可解释性。监督学习需要大量标注的对话语料进行训练,同时未能利用任务对话中经常关注的成功率等重要信息。而强化学习可以利用这些不可求导的信息,但是现有研究表明,在学习过程中,对话的可解释性大幅下降,导致对话系统与用户的交流不够顺畅。
方法介绍
任务对话系统本身是一个层级式结构,包括对话策略模块和自然语言生成模块。我们利用 Option 框架对这一层级式结构进行建模,具体的结构图如下所示:
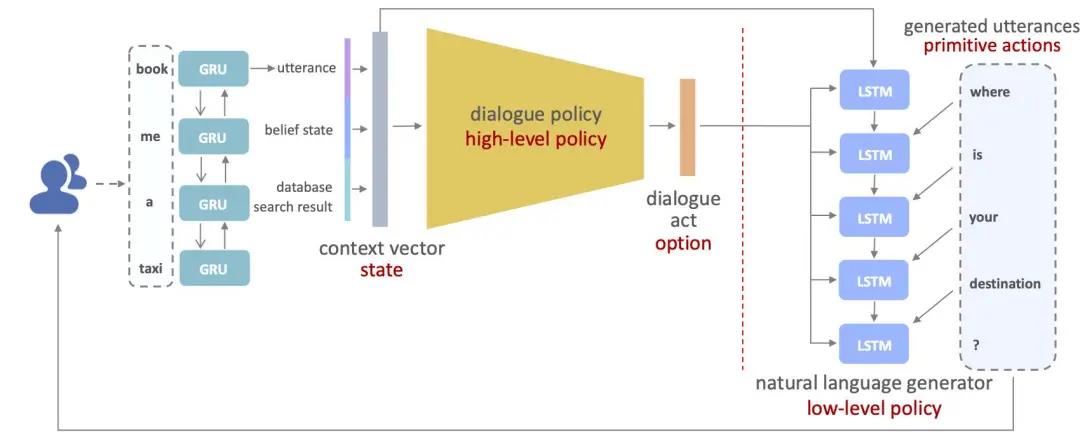
建模之后,我们利用层级式强化学习同时训练对话策略模块和自然语言生成模块,同时经理论证明异步更新两个模块可以保证策略梯度算法收敛到局部最优解。此外我们还训练了一个语言模型作为额外的奖励函数,从而引导模型生成语义连贯的对话。
结果展示
我们在常用的多领域任务对话数据集 MultiWoz 2.0 和 MultiWoz 2.1 上验证了我们的方法,与其他强化学习方法相比,我们的方法不仅达到了更高的对话成功率,同时生成的对话质量更好,语义更连贯。最后,我们还展示了模型学习到的对话动作的隐式表示,如下图所示,隐式表示在二维空间投影的集聚性(分别用8种颜色标明)表明其可解释性确实更强:

未来展望
这篇发表在 ICLR-2021 上的论文是来也科技北京研发中心算法组在强化学习、任务对话领域长期持续的研究工作的成果之一,这一发现对于推动强化学习技术在对话系统中的落地具有重大意义。







