

实战案例丨如何用5行代码扒小说!
用UIBot的元素获取功能,
很轻松就能从网页上
扒到你想要的内容。

这里就以小说网站笔趣阁为例,
教大家怎么扒小说
1、首先用Chrome打开笔趣阁的小说,(这里随便打开的一本小说,没有任何广告嫌疑,手动狗头)
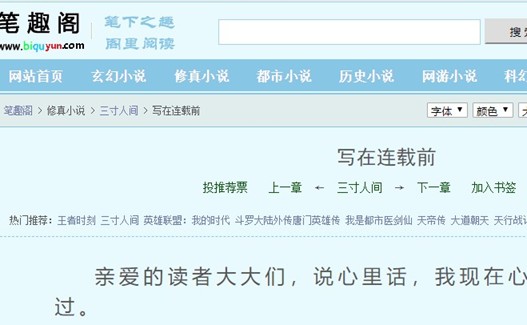
2、我们先用获取元素文本功能,
获取小说的章节标题
点击查找目标之后,把鼠标移动到浏览器小说标题的位置,获取标题元素,把获取到的文本存入变量sTitle中备用~

3、接下来我们再来获取下小说的内容,和获取标题一样使用获取元素文本功能,把小说的内容存入变量sBody中

4、我们再新建一个变量,
把刚才获取到的标题还有内容组合一下

一般我们会把标题和内容之间用换行来隔开。
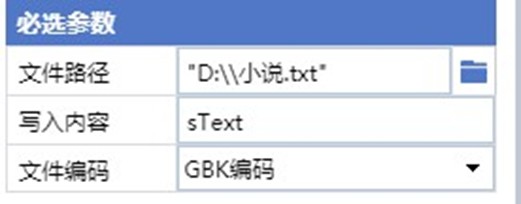
5、处理好标题和内容的连接后,我们把内容写入到一个文本里,并且是用追加写入,这样可以保证每次的写入不会覆盖掉上一次的内容。
这里使用到的命令是追加写入文件

6、最后,最重要的一步来了,前面我们只是获取到当前这一章的内容,我们想要获取整本小说,拿就得用循环命令,再配合上点击下一章的操作,这样就能实现循环的把每一章内容都提取出来,最终就能把整本小说都扒下来了。
先使用鼠标点击命令,获取到【下一章】按钮的元素

然后我们把刚才整个过程使用循环来包起来,
这样就能实现整个提取小说的过程了
++++++++我++++++++是+++++++分+++++++++割+++++++++线++++++++
看到这里,恭喜你,
已经初步掌握了
运用UiBot扒小说的基本技能。
然鹅
这怎么能够!?

那么,现在我们就来丰富下扒小说的功能。
上回书说道必须要打开到小说的第一章才能开始扒,不够有逼格,我们可以在此基础上加上自动搜索小说,自动进入第一章,自动开始扒,这样的工具逼格才会多一些。毕竟大文豪鲁迅先生曾经说过:有逼格的东西才能拿的出手!

1、打开笔趣阁网站的首页,用填写元素文本命令,获取到搜索框的元素,并且扒内容设置成你想要搜索的小说名。


这里我们就我们就随便填一个小说名
2、用鼠标点击命令,
获取搜索按钮,并点击

3、之后我们就可以看到小说的目录了,
我们可以继续用鼠标点击命令
去点击小说的第一章

4、最后再把前文中
写好的代码复制上去就好啦

看到做出来的工具越来越完善了,
嘴角不禁露出了微笑

++++++++我++++++++是+++++++分+++++++++割+++++++++线++++++++
看到这里,用UiBot获取小说的功能
算是做的差不多了。
氮素
距离真正的实用
貌似还差那么一点点。

要做到实用,我们还需解决这些问题:
1搜索不同关键字小说时的兼容性(搜索不到怎么办?)
2需要考虑网速差怎么办
3小说章节全部收集完成的判断
针对这些问题点
我们逐个解决:
1、提高元素采集的兼容性
用之前帖子中代码来运行会发现一个问题,用教程中的关键字搜索小说可以正常,但是换了个名字就不正常了,不会自动去点击小说的第一章开始采集。
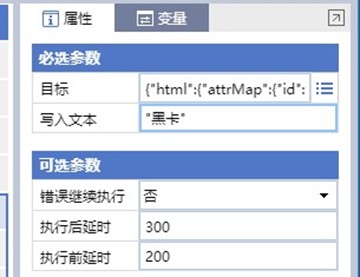
造成这种问题的关键就在于元素的特征,我们再选择完元素之后右侧的属性面板中,可以看到有一个【目标】属性,这个就是元素的特征串,点击右边的按钮,我们可以打开这样的界面。
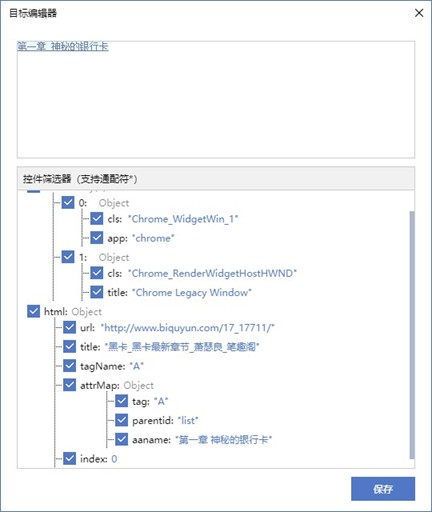
这个就是UIBot特有的元素特征了,下面树状结构就是选择的元素的层级特征。
我们可以看到上面有一些title,aaname这样的特征,结合上后面的内容不难发现,这个就表示该元素相关的页面标题,还有该元素的具体内容。
这些元素是有助于我们进行精确的定位的,但是在这里如果精确到具体的文本的话,那兼容性就不够,其他小说的名称不同就无法匹配到,所以我们可以把title和aaname这两个选项的勾去掉,不对这两个特征进行匹配就行了。修改后记得点保存按钮。
这里只是初步的介绍下元素特征,后续还会有详细的元素特征的教程,大家可以学习后灵活的去进行修改。
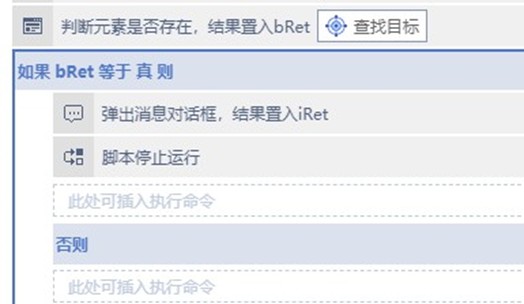
2、利用元素是否存在的判断来提高兼容性
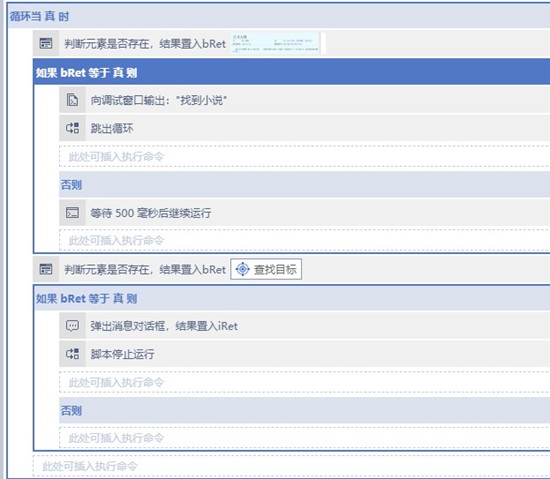
之前的脚本没有对网速慢的情况进行处理,实际上要处理是很容易的,只需要使用循环结构,在关键的地方循环判断下正确的元素是否出现,出现就表示网页正常加载,跳出循环继续即可。
第一个要判断的地方就是点击搜索按钮后页面跳转。
判断到有这种元素出现后,退出循环进行之后的采集。

当判断到这种元素时
就表示搜索的结果不对
停止脚本。
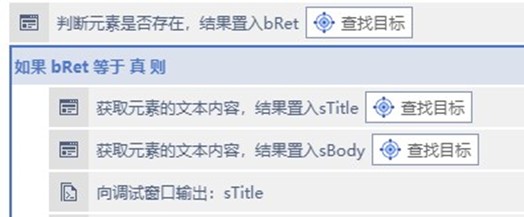
同样需要判断的的地方是
章节的跳转
要确保小说内容
加载成功后再开始采集
3、最后一步就是当采集完最后一章时能自动结束。
不难发现我们再最后一章的时候继续点击下一章的时候,会跳回小说的目录页面,我们可以通过判断目录元素是否存在来判断小说是否采集完毕了。
至此,我们圆满完成了
扒小说的任务!








