

机器学习领域的全球顶会ICLR-2021(The Ninth International Conference on Learning Representations) 于5月3日至7日在线上举行。
来也科技和英国帝国理工学院合作,在ICLR-2021发表一篇长文,利用层级强化学习的方法解决了之前强化学习在任务导向对话系统中的语义退化问题,并且在多领域任务导向对话数据集 MultiWoz 2.0 和 MultiWoz 2.1 上取得了目前的最好水平。这项研究将推动强化学习在智能客服等领域的落地,使得机器和人的交互更加智能和自然。
论文题目:Modelling Hierarchical Structure between Dialogue Policy and Natural Language Generator with Option Framework for Task-oriented Dialogue System
Github地址:https://github.com/Laiye-Tech/HDNO
论文链接:https://openreview.net/forum?id=kLbhLJ8OT12

背景知识
任务导向型对话系统
人机对话是人工智能发展过程中一个重要的任务,一直以来吸引了无数学术界和工业界的有识之士进行研究。根据需要进行分类,人机对话主要分为问答、任务导向型对话和闲聊。其中任务导向型对话因为其挑战性和在使用中的潜力而受到了广泛的关注,本研究也主要聚焦于这一类型的任务。
任务导向型对话系统可以拆解为几个模块组成的流水线结构,如下图所示[1]
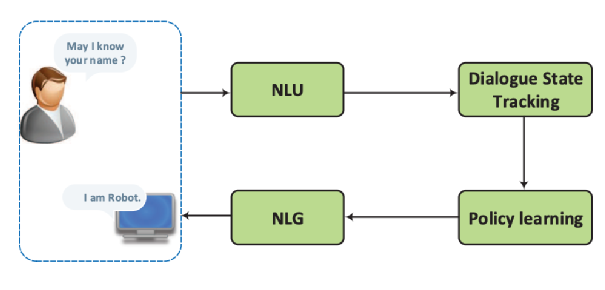
自然语言理解模块(NLU: Natural Language Understading)将用户的自然语言输入解析为对话的意图和关键信息,使用的技术包括意图识别和命名实体识别;
对话状态跟踪模块(DST: Dialogue State Tracking)管理每轮对话的输入和历史,输出当前的对话状态;
对话策略学习模块(DPL: Dialogue Policy Learning)产生本轮对话机器的回复策略,例如在预定火车票的场景下,策略可能是“询问乘车时间”;
自然语言生成模块(NLG: Natural Language Generation)将对话策略转化为自然语言作为用户收到的回复内容。
这些流水线的模块原来多根据规则和专家知识构建,因此很难适应新的领域,近年来,随着深度学习的流行,这些模块通常由神经网络来进行表示,然后利用人工标注的对话数据进行监督学习,最后得到的模块效果通常优于规则。
但是监督学习的一个明显问题就是,训练的效果依赖于标注数据的数量和质量,而这加大了应用成本。任务导向型对话系统本身具有清晰的目标,可以通过成功率等来衡量对话的质量,而强化学习相比于监督学习可以更好的利用这种不可求导的的信息。
强化学习
强化学习(Reinforcememt Learning)是主体通过与环境进行交互,取得最大化的预期利益。下图描述了强化学习的基本模型,马尔可夫决策过程(MDP: Markov Decision Process)
在时间t主体从环境得到状态 St ,然后主体执行动作 at ,在下一时刻 t+1 从环境得到新的状态 St+1 和奖励 rt+1 ,主体的目标就是学习到一个最优策略,可以最大化累计的奖励。
仔细观察,之前介绍的任务对话的流水线和强化学习的过程图非常像,实际上,任务对话系统经常被建模为马尔可夫决策过程的扩展形式,部分可观察马尔科夫决策过程(POMDP: Partially-Observed Markov Decision Process)[2],常见的奖励函数是在对话结束时给成功的任务对话一个正向的奖励,如果任务失败,则奖励为负值。
可以看到,强化学习在模型训练的过程不依赖于人工标注的回复内容,而只需要告诉模型任务是否成功,这降低了标注的负担,在一些实验中的确提高了任务对话的成功率[3]。
研究动机
强化学习在任务对话任务已经有了一些比较成功的应用。[3] 固定了自然语言生成模块,指利用强化学习训练对话策略;[4] 把自然语言生成的每个token作为动作,直接端到端地学习生成自然语言。
但是从实验结果来看,尽管这些方法都有效提高了任务的成功率,但是生成对话的流畅程度都有了明显的下降,这主要由于:
单独优化对话策略给自然语言生成模块的输入带来了偏差,影响生成对话的质量;
端到端的方法动作空间的大小等于整个词表单词的数量,这样的动作空间给强化学习带来了探索上的困难。
在工作中,我们对对话策略模块和自然语言生成模块之间的层序关系进行建模,而不是直接使用端到端的结构,两个模块的解耦降低了动作空间的大小,减少了学习的难度;
另外我们使用层序式强化学习(HRL: Hierarchical Reinforcement Learning)的方法同时训练两个模块,并且使用自然语言模型提供额外的奖励函数,保持生成对话的流畅度。
研究方法
具体来说,对话策略模块(Dialogue Policy)是对话系统中的高层策略(High-Level Policy),其输出的对话动作(Dialogue Act)在层序结构中也被称为选项(Option),而自然语言模块(Natural Language Generator)作为底层策略(Low-Level Policy)需要根据高层策略的指示生成原始动作(Primitive Actions),也就是给用户的回复内容(Generated Utterances)。完整的对应关系如下图所示:
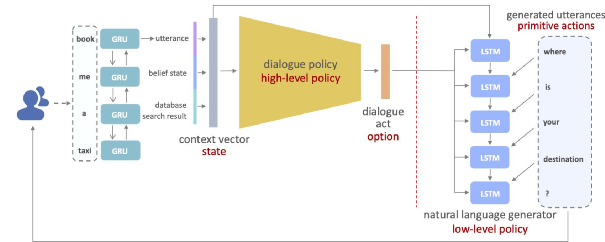
我们使用层序式强化学习的方法同时训练这两个模块,奖励函数由两部分组成,一部分是任务的成功率,如果任务成功,则在任务结束的时刻得到reward=1,否则reward=0;
另外一部分是生成模型给出每个生成字符的概率作为奖励,生成该字符的概率越大,则奖励越大,表示模型生成的字符是符合语义连贯的,应该得到强化。
综合这两部分奖励,我们证明同步优化这两个模块,可以最后收敛到局部最优解。
实验结果
我们在多领域任务对话数据集 MultiWoz 2.0 [5] 和 MultiWoz 2.1 [6] 上验证了我们的方法,结果如表格所示(HDNO代表我们的方法):
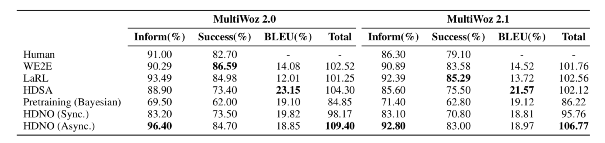
可以看到,与其他强化学习方法相比,我们的方法不仅达到了更高的对话成功率,同时生成的对话质量更好,语义更连贯。
为了减少对话策略模块生成的对话动作的标注,我们用隐状态(固定维度的向量)来表示对话动作。为了验证模型学习到的隐状态对话动作是有意义的,我们将隐状态向量投影在二维空间,并且使用K-Means聚类算法分成8类。
可以看到,同一类下的隐状态所对应的回复内容(右侧)都表达了类似的语义,但是使用了不同的表达方式。因此,我们学习到的隐状态具有很好的可解释性,这也区别于其他使用了强化学习训练的模型 [3]

影响
我们针对了任务对话系统设计了层序式强化学习的方法同时训练对话策略模块和自然语言生成模块,既提高了任务的成功率,也没有损害生成对话的质量。
另外我们的框架还可以进一步扩展,将对话状态跟踪模块和自然语言模块也加入到层序式的结构中,同时训练4个模块,最大程度发挥强化学习对标注数据需求少的优点,推动强化学习在工业界落地。
参考资料
[1] A Survey on Dialogue Systems: Recent Advances and New Frontiers. https://arxiv.org/pdf/1711.01731.pdf
[2] Using pomdps for dialog management. http://mi.eng.cam.ac.uk/research/dialogue/slt06_sjy-talk.pdf
[3] Rethinking action spaces for reinforce- ment learning in end-to-end dialog agents with latent variable models. https://arxiv.org/abs/1902.08858
[4] Towards end-to-end learning for dialog state tracking and management using deep reinforcement learning. https://arxiv.org/abs/1606.02560
[5] MultiWoz - A large-scale multi-domain wizard-of-oz dataset for task- oriented dialogue modelling. https://arxiv.org/abs/1810.00278
[6] MultiWoz 2.1: A Consolidated Multi-Domain Dialogue Dataset with State Corrections and State Tracking Baselines. https://arxiv.org/abs/1907.01669
本文作者:张原
本文编辑:刘桐烔







