


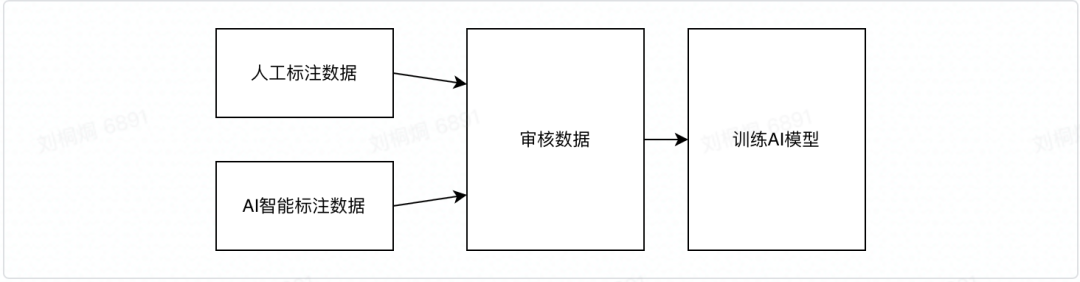
首先,为了您能顺利理解本文内容,对常见的技术名词说明如下:
借助 Excel 标注数据 使用市面上现有的标注工具 自主研发标注工具

操作、协同不便 所有关系维护在一个表格中,需要手动查找及复制 不方便多人操作统一数据集,且容易误操作 共享表格,权限无法细化 标注状态、审核状态等不方便维护
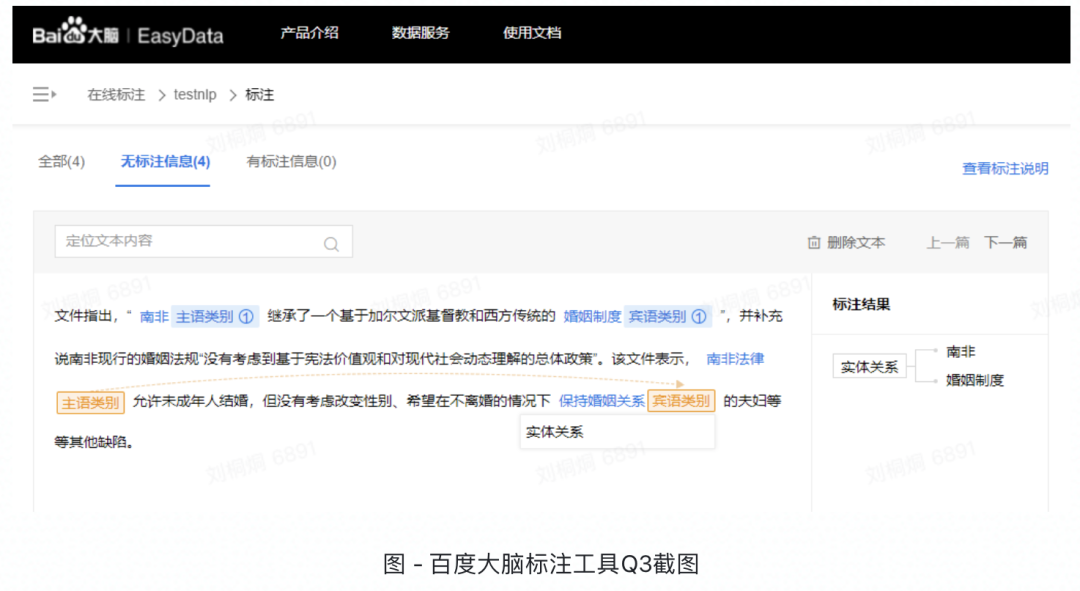
通过刷选文本取代过去复制粘贴文本的标注方式 通过共享实体和实体类型取代过去靠成员间约定的维护方式 通过高亮文本并添加指示线取代在原文档中大海捞针的审核方式 各实体持有关系数展示 点击标注结果时会用虚线指向2个实体
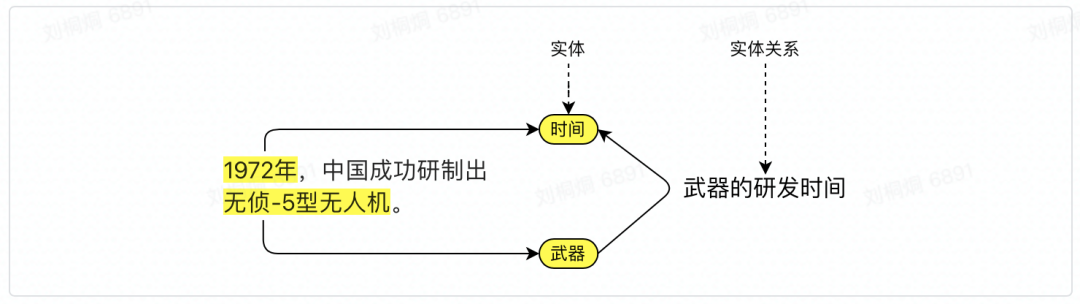
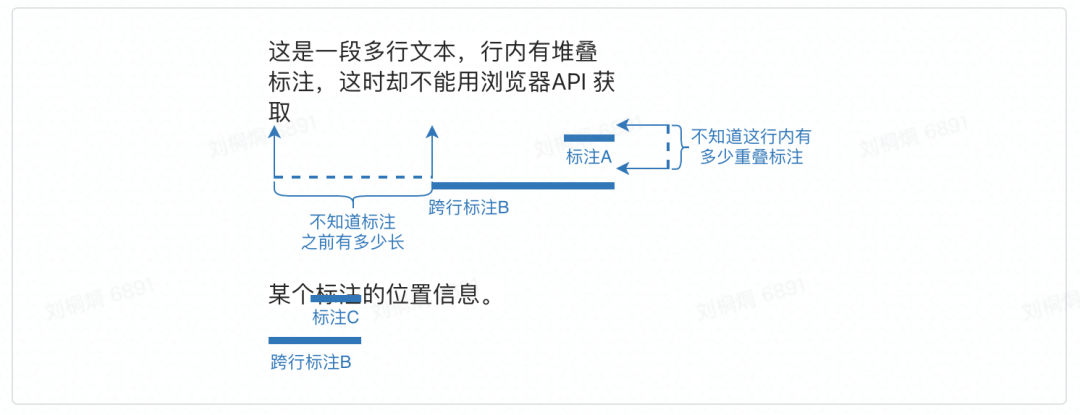
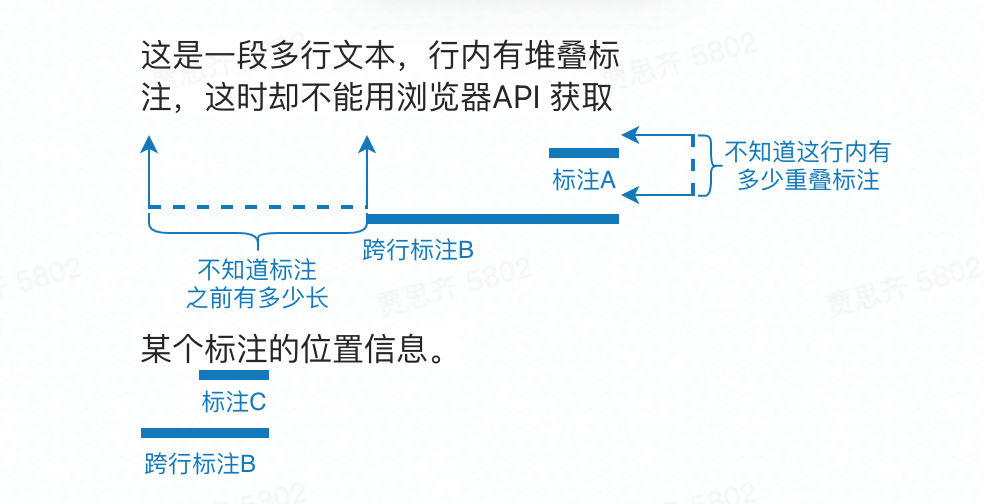
同一段文本不能被标为多种实体:实际业务场景中同段文本可能需要被拆分成多个实体,彼此之间创建实体关系。如图: 
跨行标注时会扰乱原本的文本结构,影响标注体验。如图: 
查看实体关系的实体高亮不明显,实体间的虚线可能会被文本遮盖,实际作用不大 标注时不能创建实体类型和关系类型,需要到另一个页面编辑,但我们希望可以不要切换
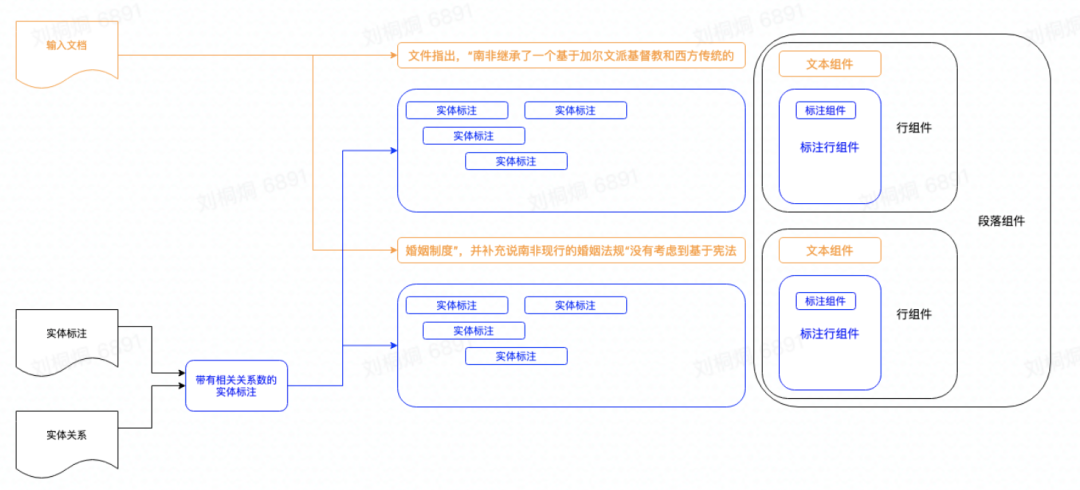
标注页面可以实时维护类型信息 同段文本可标注为多个实体 分行排版 获取字符位置 跨行实体不会被拆成单独的一行

把文本逐字填入容器,当超过容器宽度时,就将文本放入下一行。 选中的文本宽度可以通过 DOM 属性 offsetWidth 直接获取。
伪代码如下:
function breakIntoLines(str, width) {// 获取测试宽度的span,该span继承标注工具的文字样式const span = getTestSpanInstance();// 分行信息const lines = [];// 当前行的文本let tokens = '';// 当前行行首在str中的indexlet stIndex = 0;// 遍历字符串while (str.length) {// 判断当前文本再加一个字符会不会超宽span.innerText = tokens + str[0];// 如果超宽,就将之前的文本放入分行信息中,超出部分单起一行if(span.offsetWidth >= width) {lines.push({stIndex,tokens,});stIndex += tokens.length;tokens = str[0];}// 如果未超宽,则将该字符添加到当前行else {tokens += str[0];}// 吐出被插入的字符str = str.slice(1);}// 插入最后一行if(tokens) {lines.push({stIndex,tokens,})}return lines;}
横向偏移量计算:每行分完,通过计算文字的宽度即可获取标注的横向偏移量 纵向偏移量计算:判断是否与已处理完成的标注重叠,计算纵向偏移量
function injectMarksIntoLines (lines, marks) { for(let line of lines) { // 获取每行内的标注 for(let mark of marks) { if(isMarkInLine(mark, line) { line.marks = line.marks ? line.marks.concat(mark) : [mark] } }
// 根据重叠数量,确定每个标注的垂直偏移量 line.marks = line.marks.map((mark, i, arr) => { let y = 0; for(let j = 0; j < i; j++) { if(isOverlap(mark, arr[j])) { y++; } } return { ...mark, y, } }) }}不必要的分行 文本一行展示不下时,超宽内容不可见

function injectMarksIntoLines(str, width) { // ... if(isMarkInLine(mark, line) { mark.stIndex = Math.max(line.stIndex, mark.stIndex); mark.endIndex = Math.min(line.endIndex, mark.endIndex);
line.marks = line.marks ? line.marks.concat(mark) : [mark] } // ...}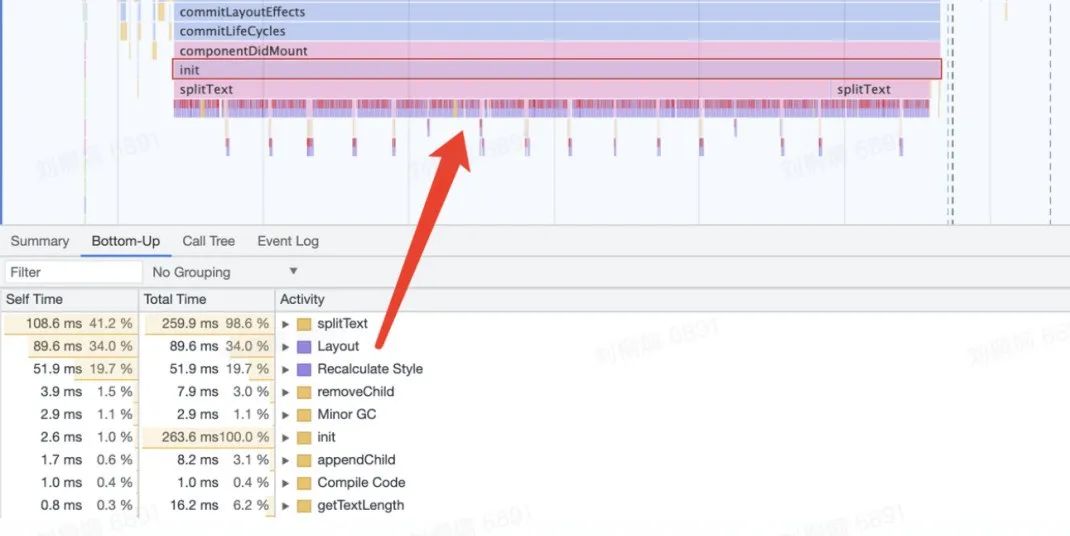
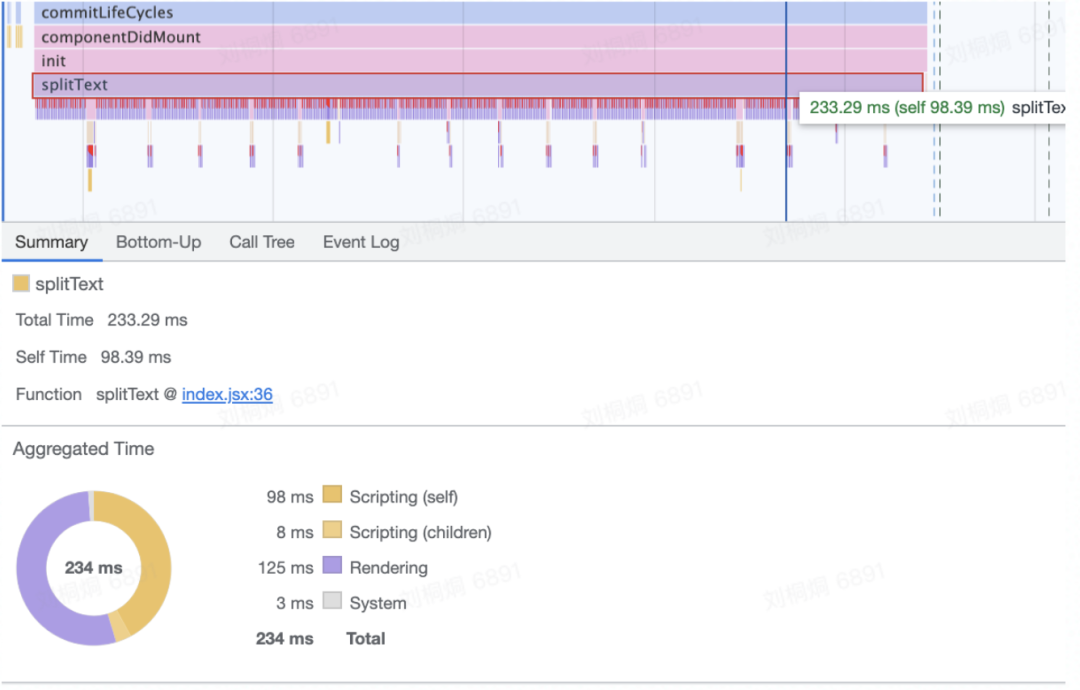
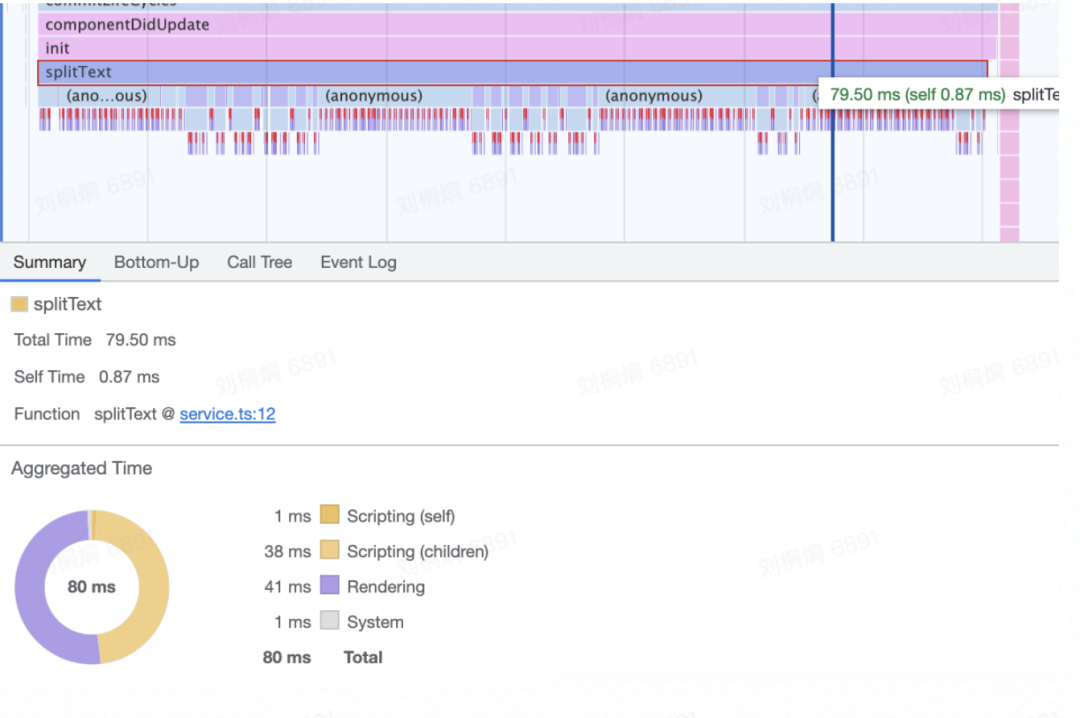
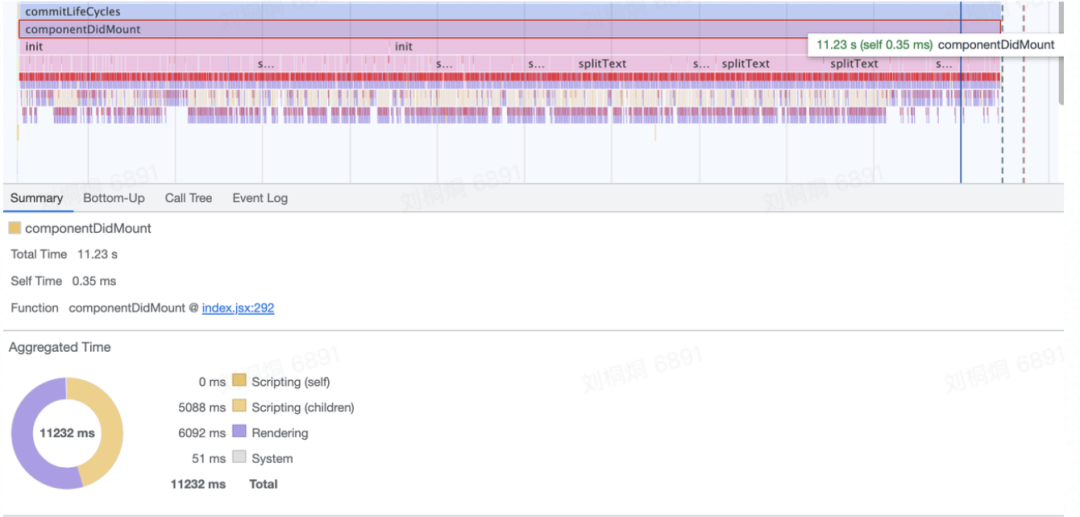
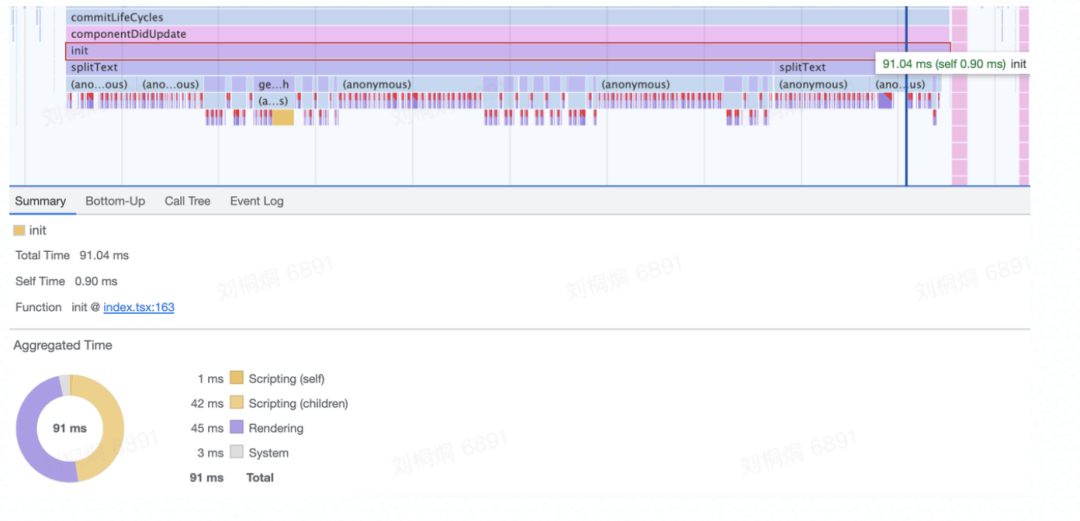
分行算法会频繁获取 offsetWidth :每调用一次,都会导致页面重排,严重耗时; 计算标注纵向偏移量时,会先遍历全部标注,过滤出在当前行的标注,然后进行遍历,得到重叠高度信息,遍历次数过高;
每行文本的字数相差不多,因为中文字的宽度相同,导致字数差异的是数字、字母等; 中文业务场景中数字和字母远没有中文字数多; 即使在最小的屏幕上展示,每行最少也有30个字符;
处理第一行时,我们不再逐字测宽,而是直接截取前30个字符测宽,多退少补直至宽度正确; 记录第一行的字数,作为下一行期望的字数 except,多退少补直至正确; 记录新的一行的字数 n,修正except = ( except + n ) / 2 。重复此步骤,直至文本分行结束
 |  | |
 |  |
针对这个问题,优化思路如下:
将标注按起始位置升序排列。假设第一行有30个字,那么我们就从升序数组中拿出起始位置小于30的,这就是本行要添加的标注。 判断这些标注是否重叠。假设用户添加了两个标注: 如果二者不重叠,那二者应该展示在一行; 如果二者重叠,那么就要将后处理的标注放在前者的下一行; 遍历数组,把在本行结束的标注剔除。保证每行展示的标注,要么是上一行没有结束的,要么是在本行开始的。
伪代码如下:
function getMarkPosition(lines, marks) { // 起始位置升序 const stIndexArr = marks.sort((a, b) => a.stIndex - b.stIndex); const st = 0; // 本行需要添加的标注 let current = []; for (let line of lines) { // 获取当前行的标注 while(stIndexArr[st].stIndex <= line.endIndex) { current.push(stIndexArr[st]); st++; } // 获取标注 mark.offsetX = getTextLength(line.text.slice(0, mark.stIndex - line.stIndex)) // 添加标注行 addMarkLines(line, current); // 剔除本行结束的标注 current = current.filter(oldMark => oldMark.endIndex > line.endIndex); }}// 添加标注行function addMarkLines (line, marks) { const markLines = [[]]; let inserted = false; // 遍历所有标注 marks.forEach(mark => { // 遍历所有行 for(let i = 0; i < markLines.length; i++) { // 如果本行没有和新标注重叠的,则放入本行 if(!markLines[i].find(oldMark => isOverlap(oldMark, mark))) { mark.offsetY = i; markLines.push(mark); inserted = true; break; } } // 如果所有行都重叠,则单开一行 if(!inserted) { mark.offsetY = markLines.length; markLines.push([mark]); } }) line.markLines = markLines;}







