


小来说:
想知道美颜相机是如何实现风格转换,如何大眼、瘦脸的吗?
GAN可以!(图到图翻译、风格迁移)
本文详细介绍了GAN的发展历程和来也科技对GAN的实践
文章较长,列出目录结构辅助大家阅读:
导读
最早期的GAN
结构
损失函数
一些GAN的改进
DCGAN
WGAN
关于模式崩溃与梯度消失
GAN的应用--图到图翻译、风格迁移
cGAN
pix2pix
CycleGAN
来也科技基于GAN的手写字体风格迁移实践
基于BicycleGAN的手写风格迁移实践
模型简介
具体实践
基于Zi2Zi的手写汉字风格迁移实践
模型简介
具体实践
总结
GAN的优缺点分析
训练GAN的技巧
应用场景
参考资料
最早期的GAN
G:不断生成自认为是“真实”的假数据(fake data) D:判断数据为真的可能性,一般是个二分类器
对噪声进行一个batch的采样作为本轮输入送入G,生成一个batch的fake data 将fake data标记为正样本,输入D,用于“欺骗”鉴别器,计算损失,更新G的参数
结构
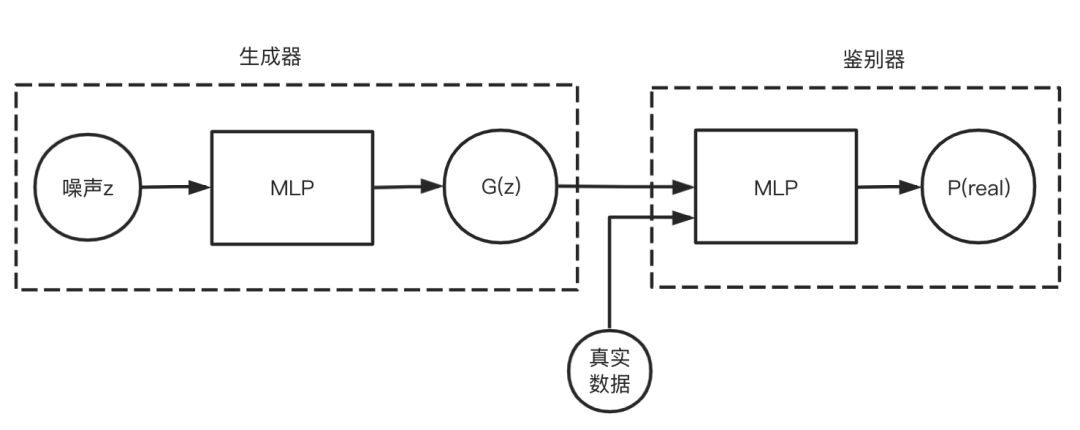
损失函数
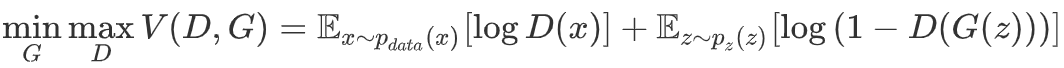
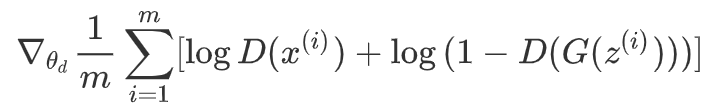
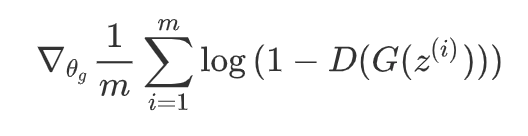
一些GAN的改进
DCGAN
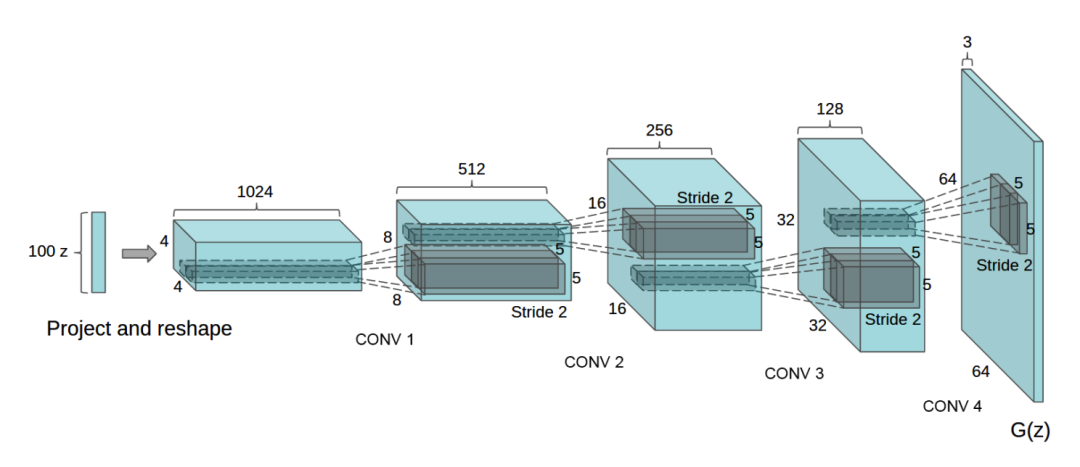
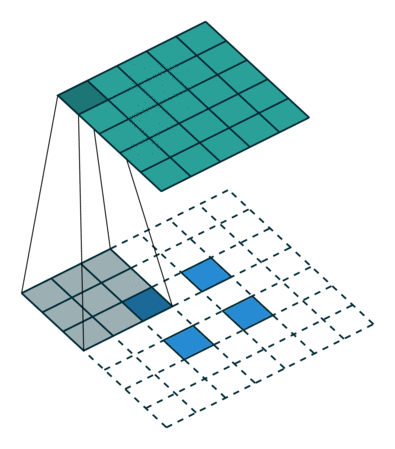

WGAN


关于模式崩溃与梯度消失

GAN的应用--图到图翻译、风格迁移
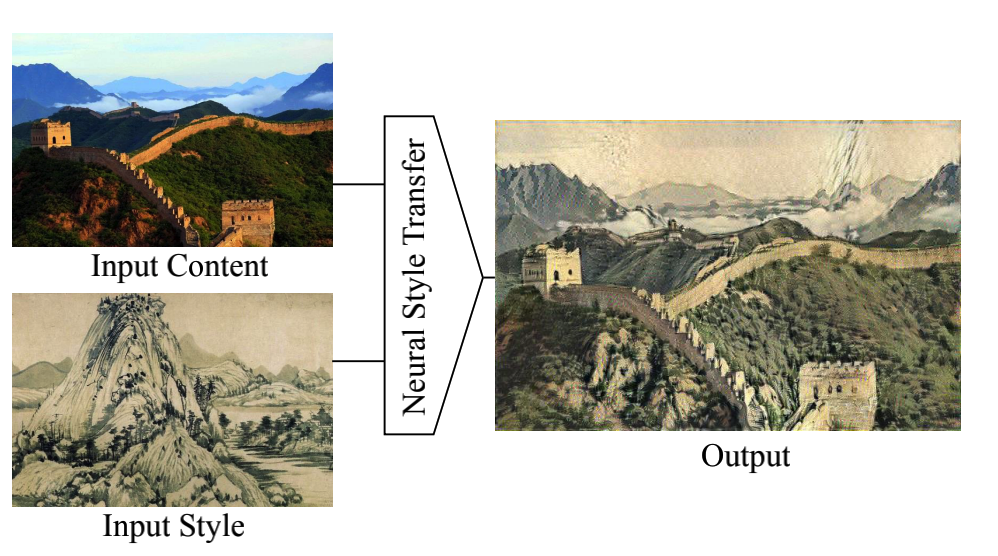
有监督:cGAN,pix2pix 无监督:CycleGAN
cGAN
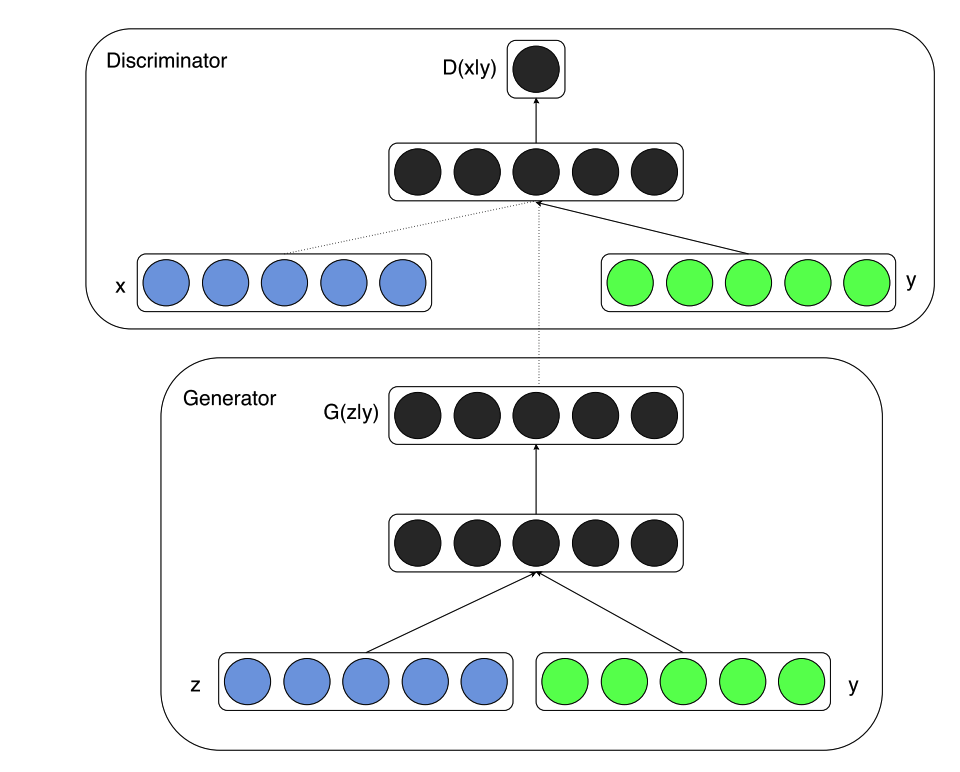
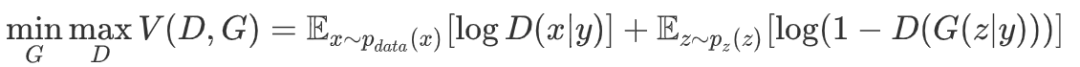
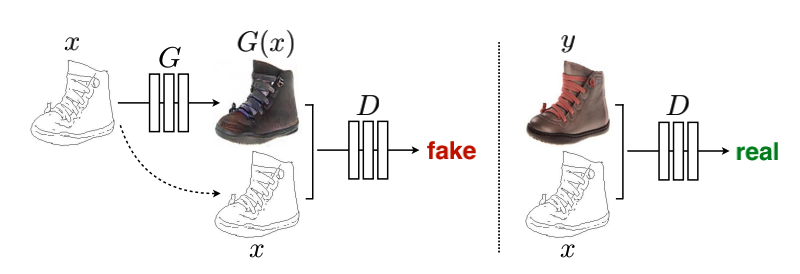
pix2pix
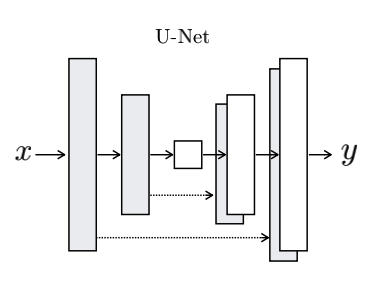
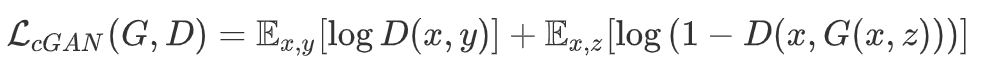
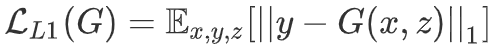
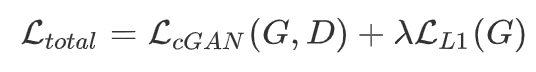
CycleGAN
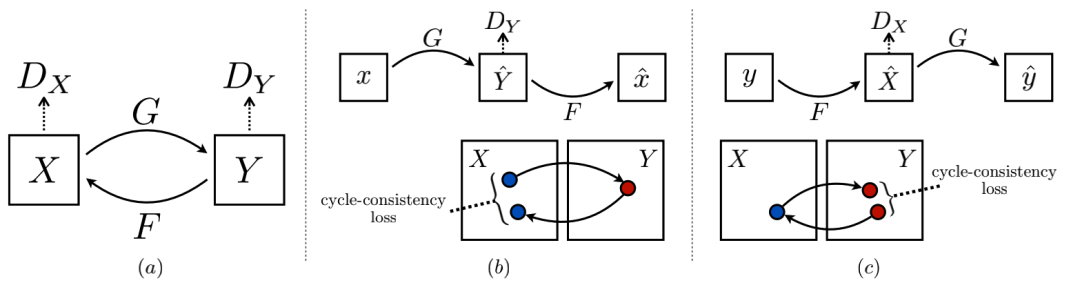
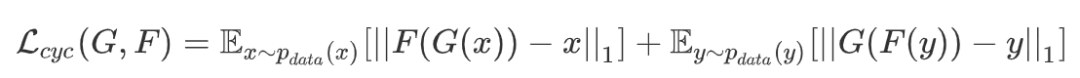
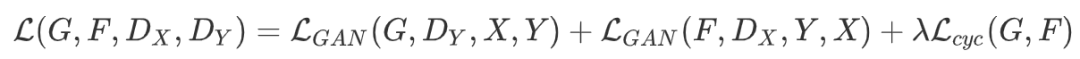
{cat_sketch, cat_color} {handbag_sketch, handbag_color} {lemon_sketch, lemon_color}
X = {cat_sketch, handbag_sketch, lemon_sketch} Y = {cat_color, handbag_color, lemon_color}
来也科技基于GAN的手写字体风格迁移实践
基于BicycleGAN的手写风格迁移实践
模型简介
 。与真实目标风格图像B之间的L1损失与对抗损失以及隐向量与高斯分布之间的KL损失优化模型参数。
。与真实目标风格图像B之间的L1损失与对抗损失以及隐向量与高斯分布之间的KL损失优化模型参数。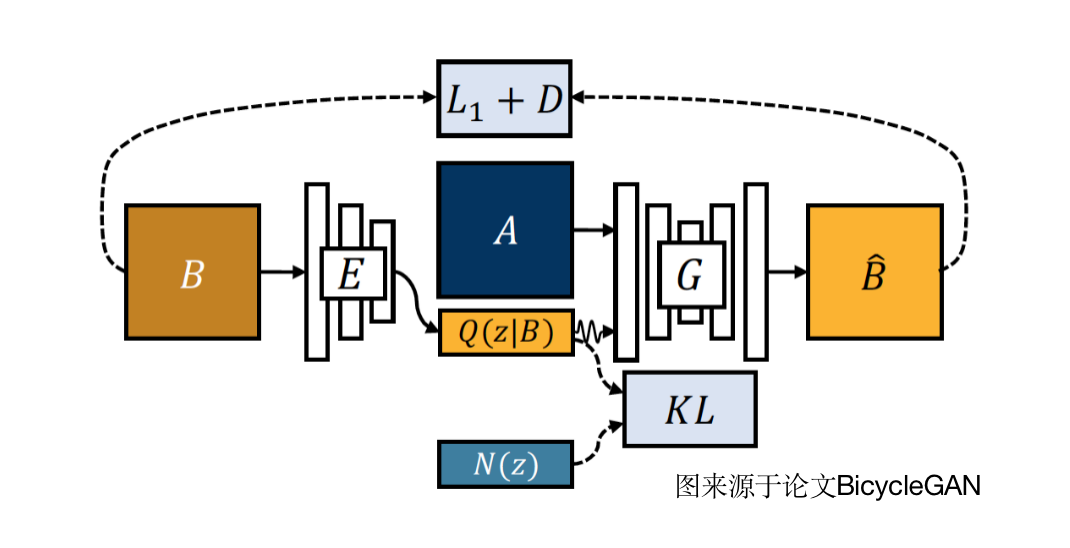 。再次通过cLR-GAN中的编码器提取隐向量z,通过约束z与N(z)之间的L1距离来促使中保留隐向量信息。携带了随机隐向量N(z)信息,因此不能再与B进行像素约束,即:与B仅通过鉴别器计算对抗损失。注意:这里最好不复用cVAE-GAN中的鉴别器。
。再次通过cLR-GAN中的编码器提取隐向量z,通过约束z与N(z)之间的L1距离来促使中保留隐向量信息。携带了随机隐向量N(z)信息,因此不能再与B进行像素约束,即:与B仅通过鉴别器计算对抗损失。注意:这里最好不复用cVAE-GAN中的鉴别器。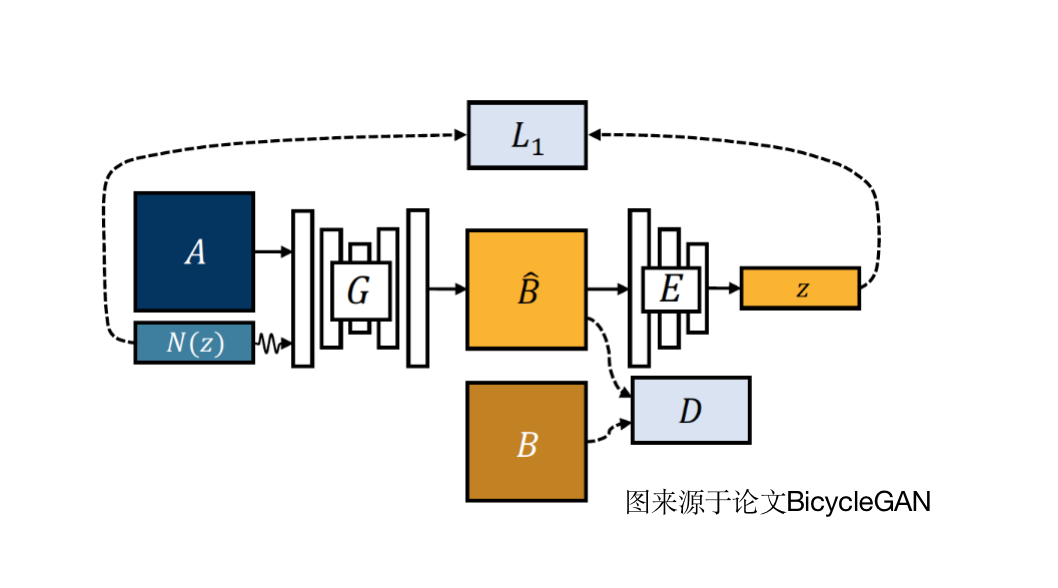
具体实践
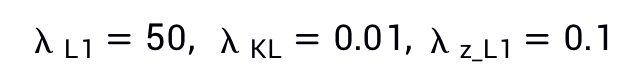 会有较为稳定的结果。但是我们在原始论文的架构上(附录8)上实验发现:模型有较严重的笔画丢失问题,因此尝试引入Feature-Loss和AC-Loss,并设计了LSTM鉴别器来缓解这一问题,但实验效果不及预期。其中,加入Feature-Loss后生成结果有细微增强,下面是实验结果展示,可以看出有些风格上较细的笔画容易在迁移过程中丢失:
会有较为稳定的结果。但是我们在原始论文的架构上(附录8)上实验发现:模型有较严重的笔画丢失问题,因此尝试引入Feature-Loss和AC-Loss,并设计了LSTM鉴别器来缓解这一问题,但实验效果不及预期。其中,加入Feature-Loss后生成结果有细微增强,下面是实验结果展示,可以看出有些风格上较细的笔画容易在迁移过程中丢失:
基于Zi2Zi的手写汉字风格迁移实践
模型简介
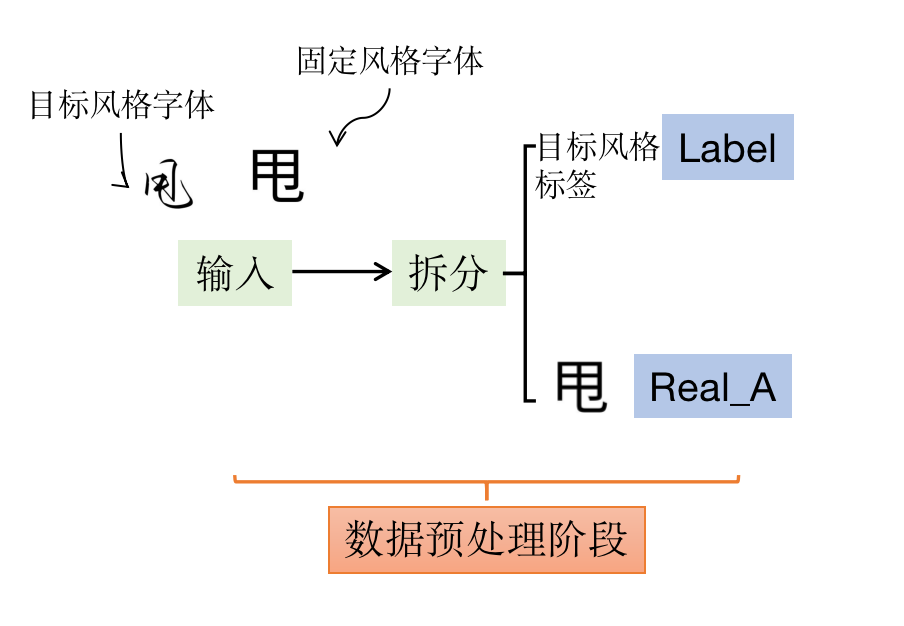
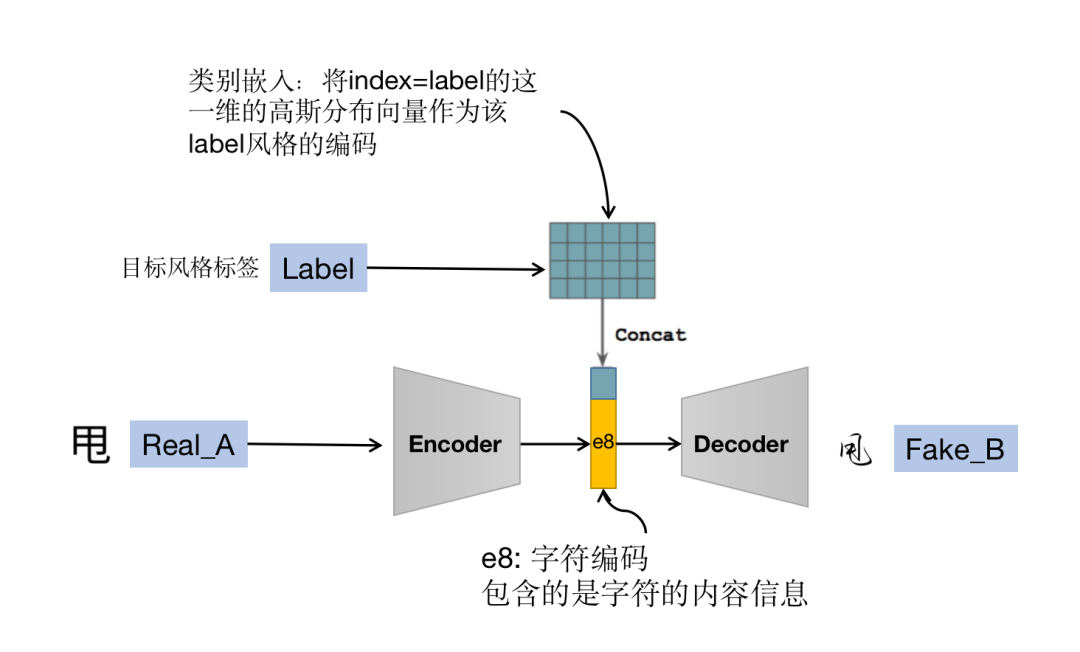
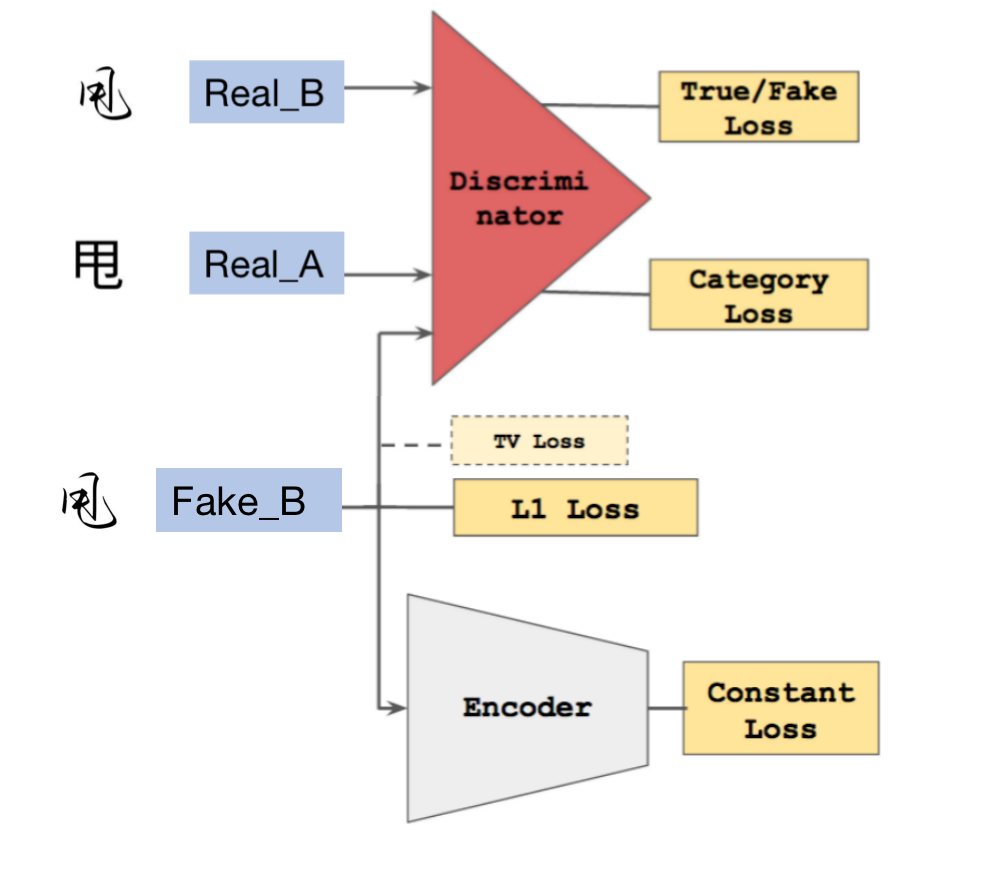
具体实践
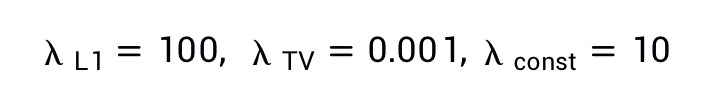 ,其他权重均设为1,会有较稳定良好的训练结果。
,其他权重均设为1,会有较稳定良好的训练结果。
总结
GAN的优缺点分析
训练GAN的技巧
应用场景
Generate Examples for Image Datasets Generate Photographs of Human Faces Generate Realistic Photographs Generate Cartoon Characters Image-to-Image Translation Text-to-Image Translation Semantic-Image-to-Photo Translation Face Frontal View Generation Generate New Human Poses Photos to Emojis Photograph Editing Face Aging Photo Blending Super Resolution Photo Inpainting Clothing Translation Video Prediction 3D Object Generation
GAN典型应用介绍:
https://medium.com/@jonathan_hui/gan-some-cool-applications-of-gans-4c9ecca35900
https://machinelearningmastery.com/impressive-applications-of-generative-adversarial-networks/
参考资料
Generative Adversarial Networks http://arxiv.org/abs/1406.2661
Deep Convolutional GAN https://arxiv.org/abs/1511.06434
Wasserstein GAN https://arxiv.org/abs/1701.07875
Neural Style Transfer: A Review https://arxiv.org/abs/1705.04058
Conditional GAN https://arxiv.org/abs/1411.1784
Image-to-Image Translation with Conditional Adversarial Networks https://arxiv.org/abs/1611.07004
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks https://arxiv.org/abs/1703.10593
https://cloud.tencent.com/developer/article/1335705
比较详细的GAN综述:http://www.gwylab.com/note-gans.html
BicycleGAN:https://arxiv.org/abs/1711.11586
FontRNN:https://onlinelibrary.wiley.com/doi/full/10.1111/cgf.13861
ZI2ZI:https://github.com/kaonashi-tyc/zi2zi
本文作者:摄影师王同学,李嘉琛,薛洁婷
本文编辑:刘桐烔







